Outlier data mining method based on feature weighting and MapReduce
A feature weighted, outlier data technology, applied in data mining, special data processing applications, electrical digital data processing, etc., can solve the problems of ambiguous cluster structure, large amount of calculation, large amount of data, etc., to achieve mining efficiency and high precision, overcoming efficiency problems, and the effect of small human factors
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0028] For the mining of high-dimensional and massive data, the scheme of the present invention provides the following method steps:
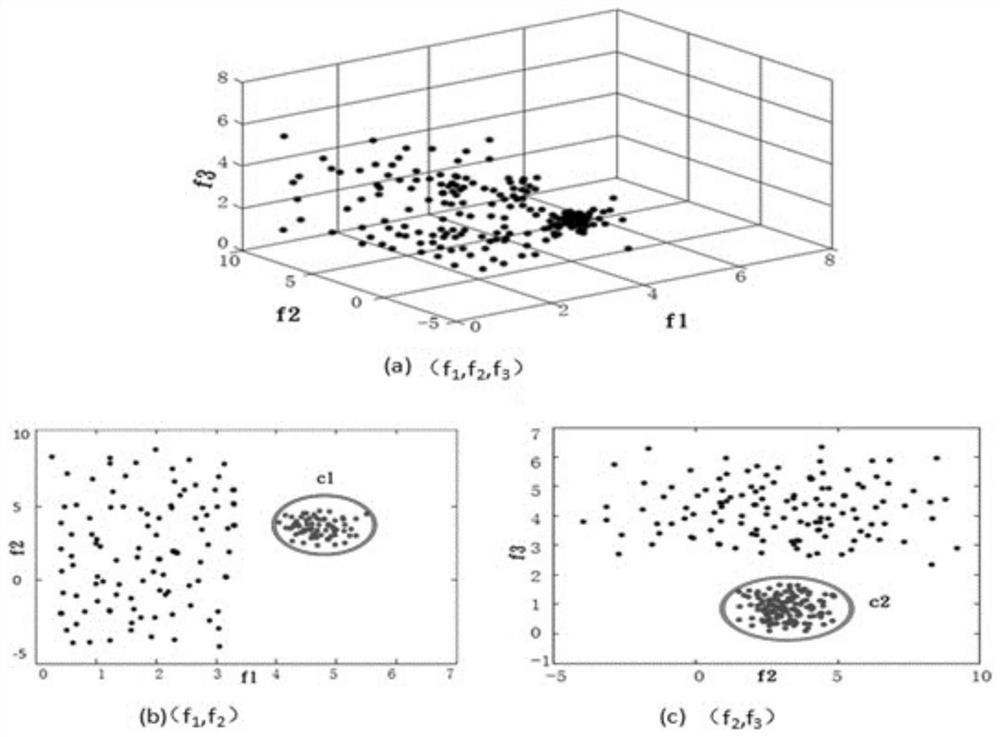
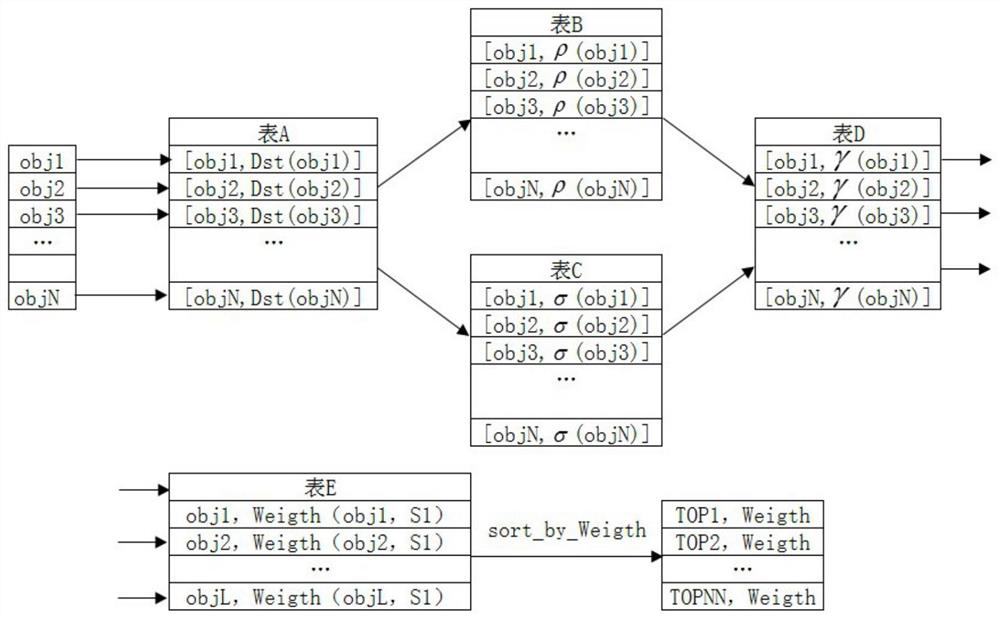
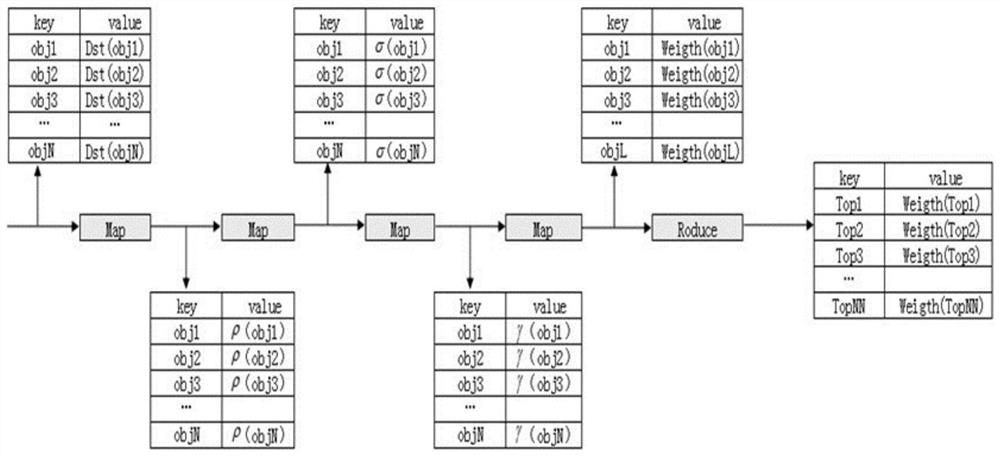
[0029] Step 1: Based on the feature weighted subspace, the subspace data is separated into cluster centers, clusters and candidate outlier data sets under the programming model; Step 2: Calculate the global distance for the outlier data set described in step 1, Then define the outlier data.
[0030]Preferably, in step one, the feature weighted subspace is obtained after defining the feature weighted estimation entropy on the attribute dimension, and then under the MapReduce programming model, the subspace data set is quickly separated by using the density peak algorithm; in step two, the The calculation of the global distance includes calculating its global Weight_k distance, and the calculation of the Weight_k distance also includes a process of sorting the Weight_k distance set in descending order and outputting TOP-N data. Further, in the f...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com