

Text visual question-answering system and method based on concept interaction and associated semantics
A textual and visual technology, applied in the field of visual question answering, which can solve problems such as ignoring objects and visual relationships
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
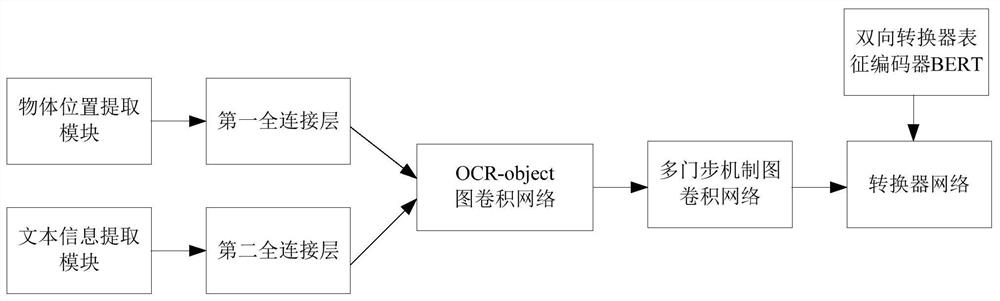
[0066] Such as figure 1 As shown, the present invention provides a text visual question answering system based on concept interaction and associated semantics, including an object position extraction module, a first fully connected layer connected to the object position extraction module, a text information extraction module, and a text information extraction module The connected second fully connected layer, the OCR-object graph convolutional network connected to the first fully connected layer and the second fully connected layer, the gate step mechanism graph convolutional network and the AND gate connected to the OCR-object graph convolutional network Step mechanism graph convolutional network connected to the converter network, the converter network is connected to the bidirectional converter characterization encoder BERT; the object position extraction module is used to extract the vision in the image using the pre-trained fast area object detector Faster-RCNN model Featu...
Embodiment 2
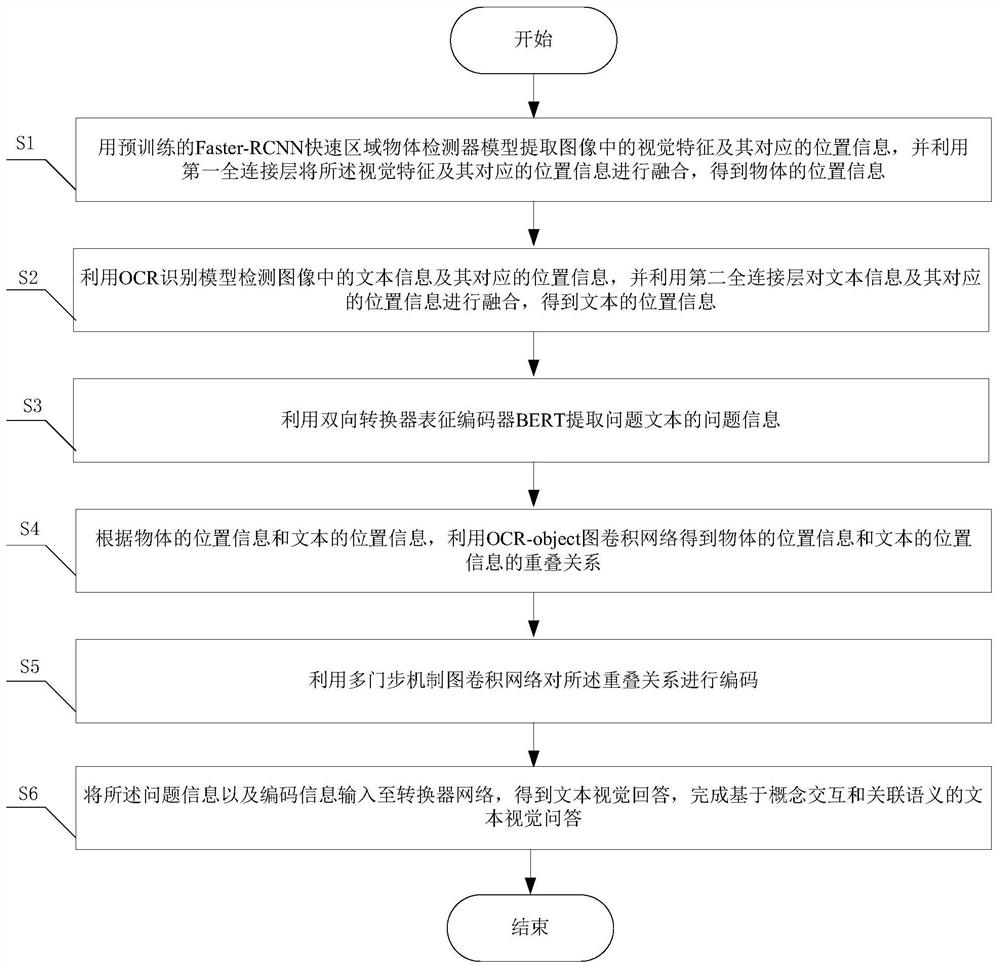
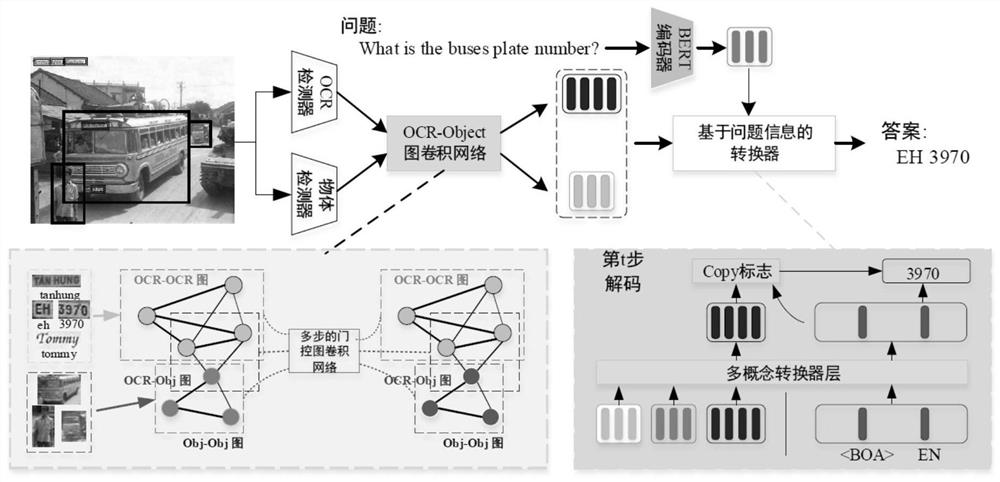
[0069] Based on the above system, the present invention also provides a text visual question answering method based on concept interaction and associated semantics. The basic idea is to use the positional relationship between the object in the image and the text information to model the relationship, and then use the OCR-object image volume Integral network is used to model text information and object information, learn richer and more directional features through the coding of relations based on the gate mechanism, and then use the converter network according to the problem information to compare the objects and objects in the image. Accurate attention to the text to get more accurate answers. Such as Figure 2-Figure 3 As shown, its implementation method is as follows:
[0070] S1. Use the pre-trained fast regional object detector Faster-RCNN model to extract visual features and their corresponding location information in the image, and use the first fully connected layer to fu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More