

Data storage method and device, server and storage medium
A data storage and data technology, applied in the field of data processing, can solve the problems of low data processing efficiency and large storage space occupied by mass data storage, and achieve the effect of improving data processing efficiency and avoiding excessive storage space occupation.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
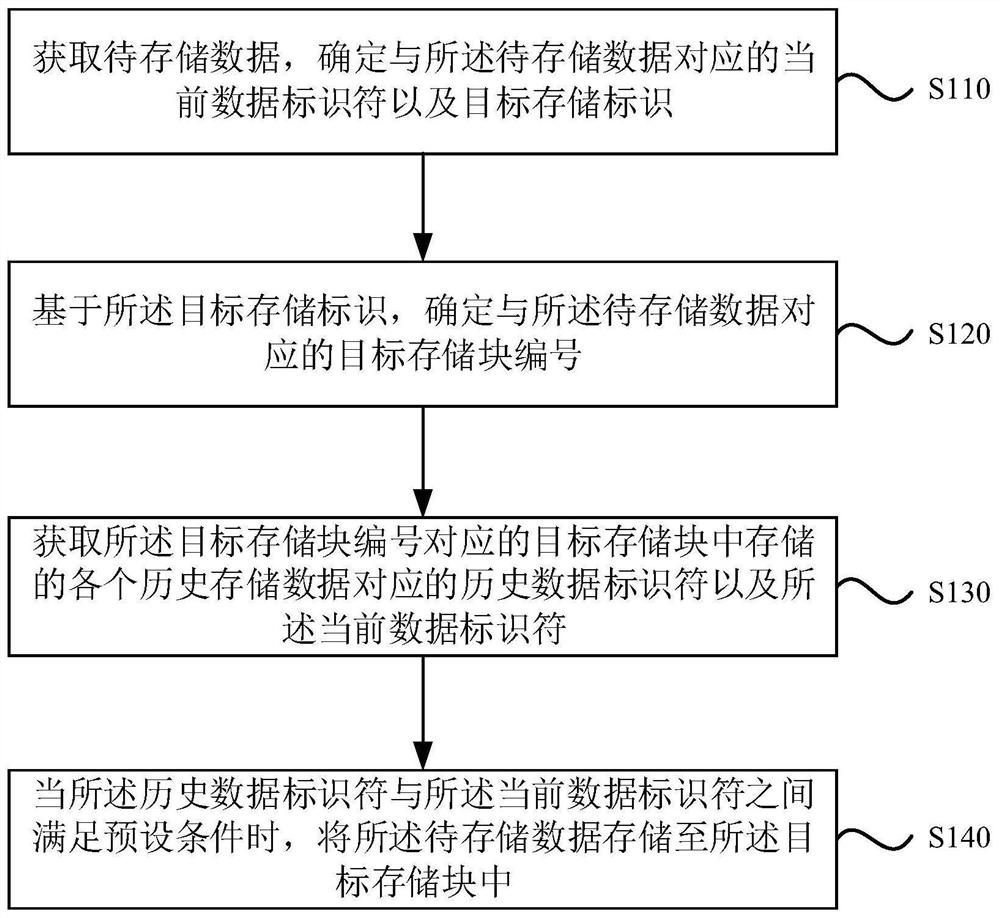
[0028] figure 1 It is a schematic flow diagram of a data storage method provided by the embodiment of the present invention. This embodiment is applicable to the situation of deduplication, merging and storage of massive structured data. The method can be executed by the management system of the storage chip, and the system can Realized in the form of software and / or hardware.
[0029] Before introducing the technical solution of this embodiment, an application scenario is briefly introduced. For example, the method can be applied to offline and / or online tasks, that is, the situation of offline or online data deduplication and merging.
[0030] Such as figure 1 As shown, the method specifically includes the following steps:
[0031] S110. Acquire data to be stored, and determine a current data identifier and a target storage identifier corresponding to the data to be stored.
[0032] Wherein, the data to be stored may be massive structured data requiring structured dedupl...
Embodiment 2
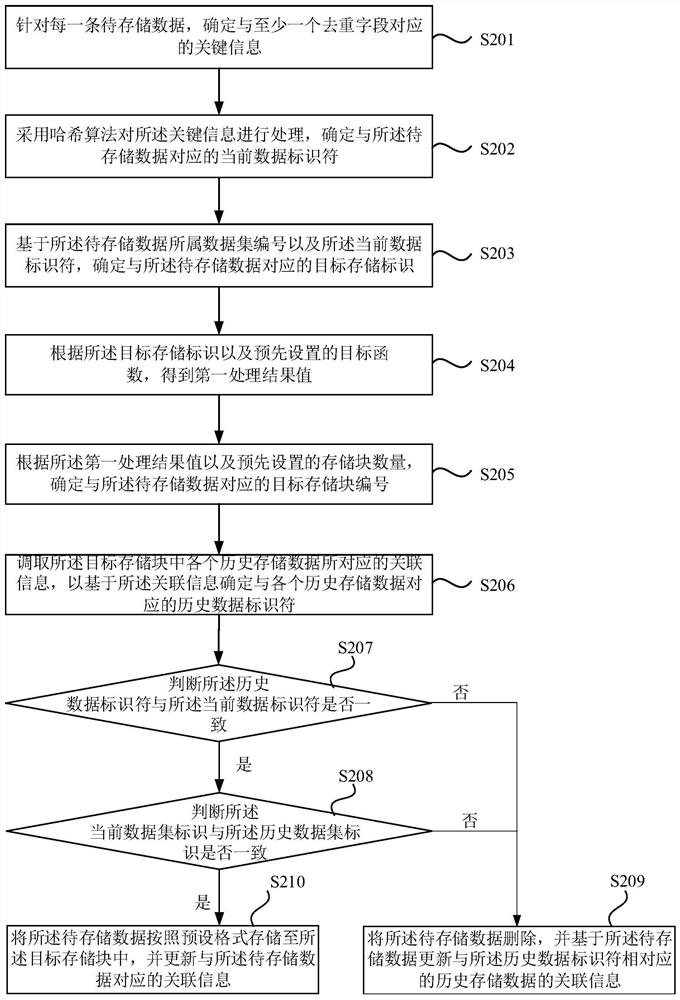
[0047] figure 2 It is a flowchart of a data storage method provided by Embodiment 2 of the present invention. This embodiment is a further optimization based on Embodiment 1. Such as figure 2 As shown, the method specifically includes:
[0048] S201. For each piece of data to be stored, determine key information corresponding to at least one deduplication field.
[0049] Among them, the data level of the data to be stored is generally in the hundreds of billions, and the space occupation may reach tens or even hundreds of terabytes. Therefore, it is necessary to deduplicate, merge and store each piece of data to be stored in each data set.
[0050] Wherein, in this embodiment, first, data may be processed according to a deduplication policy, and key information in at least one deduplication field may be extracted. It can be understood that the deduplication strategy is to determine the fields to be deduplicated, that is, the fields that need to be deduplicated, and the s...
Embodiment 3
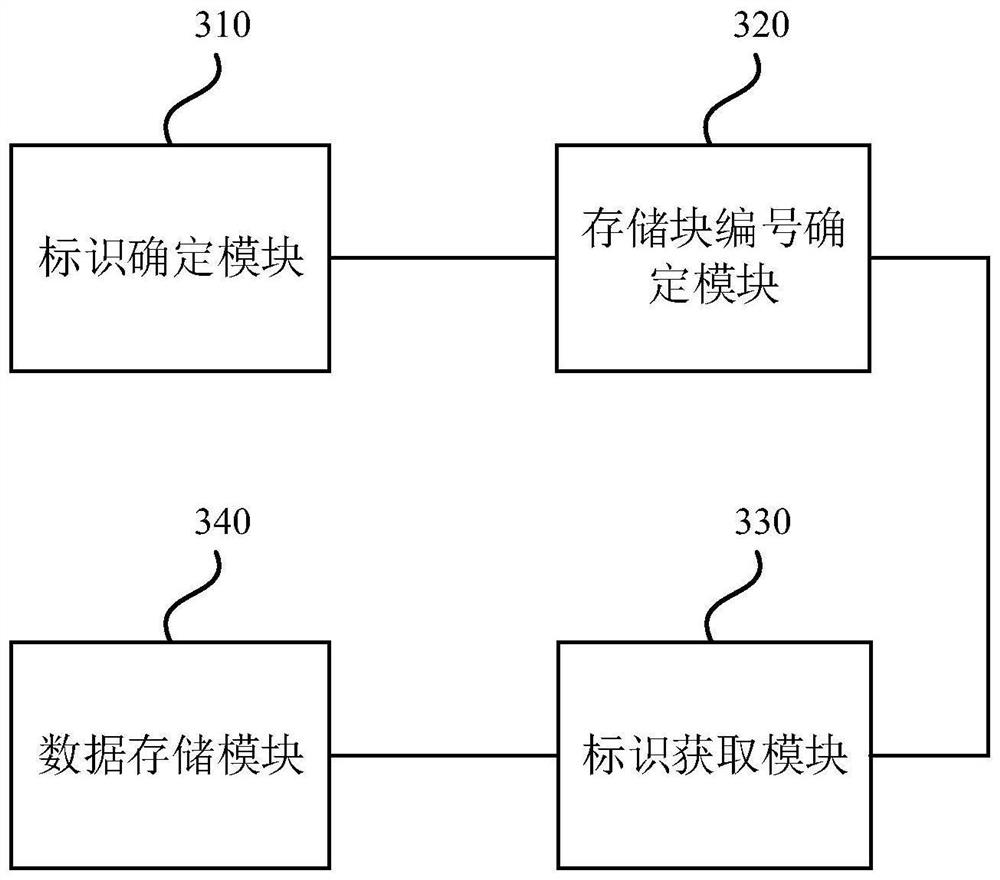
[0086] image 3 It is a structural block diagram of a data storage device provided by Embodiment 3 of the present invention. The device is used to execute a data storage method provided by any of the above embodiments, and has corresponding functional modules and beneficial effects for executing the method. The device includes: an identifier determination module 310 , a storage block number determination module 320 , an identifier acquisition module 330 and a data storage module 340 .
[0087] The identification determination module 310 is used to obtain the data to be stored, and determine the current data identifier corresponding to the data to be stored and the target storage identification; the storage block number determination module 320 is used to determine the target storage identification based on the target storage identification. The target storage block number corresponding to the data to be stored; the identification acquisition module 330, configured to obtain t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More