

Online examinee voice authentication recognition and state maintenance system, and recognition method
A voice authentication and state maintenance technology, applied in voice analysis, instruments, etc., can solve problems such as low recognition rate, and achieve the effect of improving recognition efficiency, accuracy and efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
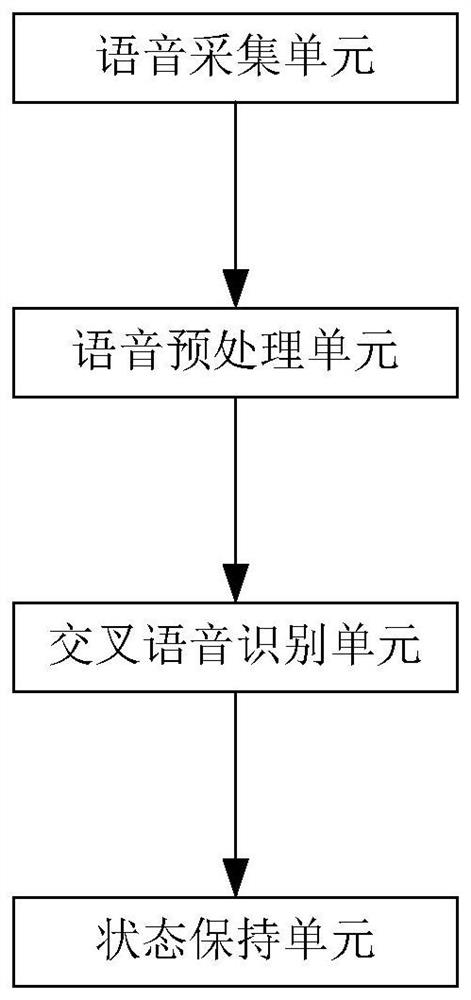
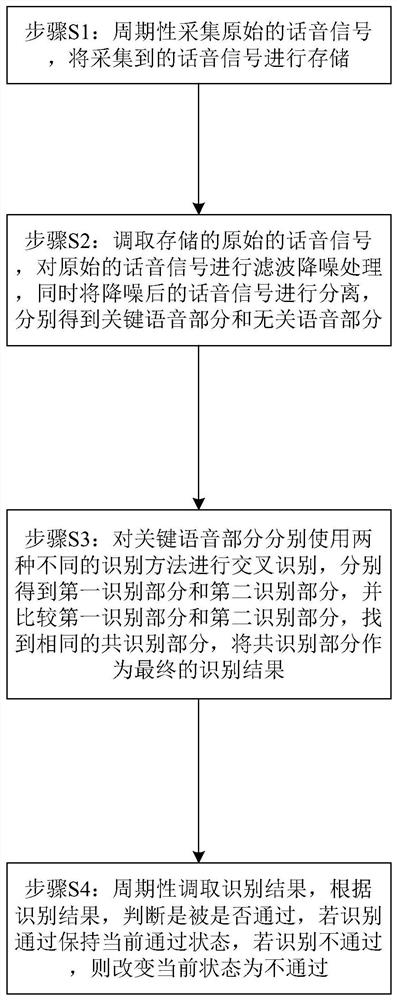
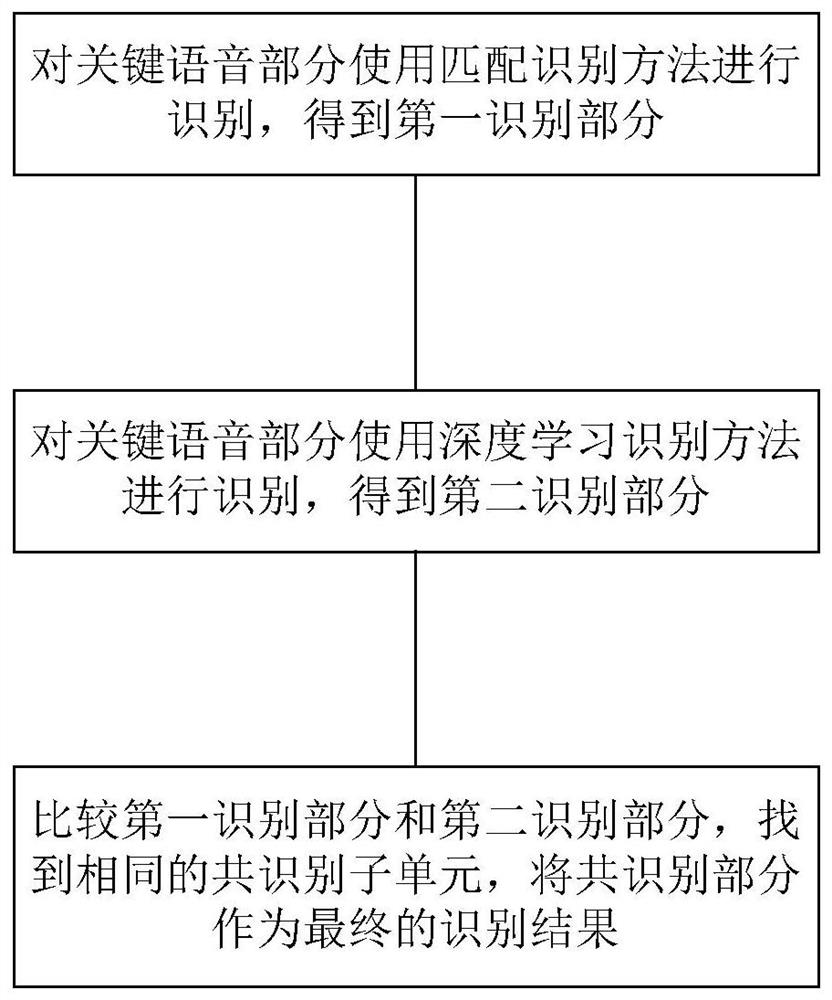
[0030] Such as figure 1 As shown, the online examinee's voice authentication recognition and state maintenance system, the system includes: a voice collection unit, a voice preprocessing unit, a cross speech recognition unit and a state maintenance unit; the voice collection unit is configured to periodically collect the original Voice signal, the collected voice signal is stored; the voice pre-processing unit is configured to call the stored original voice signal, perform filtering and noise reduction processing on the original voice signal, and simultaneously process the noise-reduced voice signal Separation is carried out to obtain key speech parts and irrelevant speech parts respectively; the cross-speech recognition unit is configured to use two different recognition methods for cross-recognition of the key speech parts, respectively, to obtain the first recognition part and the second recognition part , and compare the first recognition part with the second recognition p...
Embodiment 2
[0033] On the basis of the previous embodiment, the speech preprocessing unit includes: a filtering noise reduction processing subunit and a speech signal separation subunit; the filtering noise reduction processing subunit is configured to perform filtering and noise reduction on the original speech signal The processing specifically includes: decomposing the voice signal to obtain a noise voice signal, an error voice signal and a basic voice signal; and performing noise voice signal suppression on the noise voice signal part, and performing voice signal compensation on the error voice signal part. On the basis of the voice signal, the final voice signal is obtained; first, the received voice signal is expressed by the following formula: P P =Asincos(0.5wt+1.5kx); its voice signal energy density is: Among them, A is the amplitude of the voice signal; w is the phase of the voice signal; t is the time parameter of the voice signal; k is the correction coefficient, which is any...
Embodiment 3
[0035] On the basis of the previous embodiment, the voice signal separation subunit is configured to separate the noise-reduced voice signal to obtain key voice parts and irrelevant voice parts respectively; specifically, it includes: pre-collected voice signals The analysis is carried out to obtain the change relationship of the irrelevant speech time interval, the key speech time interval and the cumulative probability of the voice signal; the noise-reduced voice signal is separated by using the obtained change relationship.
[0036] refer to Figure 5 , the time interval of the irrelevant speech and the time interval of the key speech change periodically, and with the increase of time, the cumulative probability will increase significantly. In this way, the speech signal can be separated according to a pre-established model or variation relationship. From the separated voice signal, the key voice part can be obtained. Recognizing key speech parts in the follow-up can sign...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More