Face illumination processing method based on Retinex decomposition and generative adversarial network
A processing method and network technology, applied in the field of image processing and pattern recognition, can solve the problems of poor local shadow processing effect, easy distortion and distortion of face images, and inability to recognize face images.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0079] Below in conjunction with accompanying drawing and specific embodiment the present invention is described in further detail:
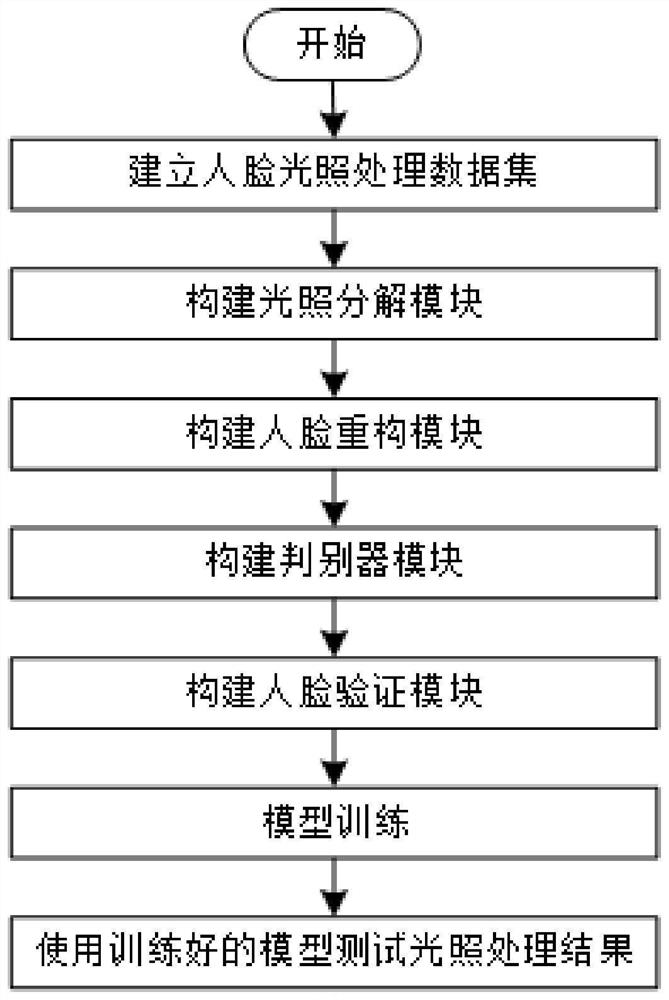
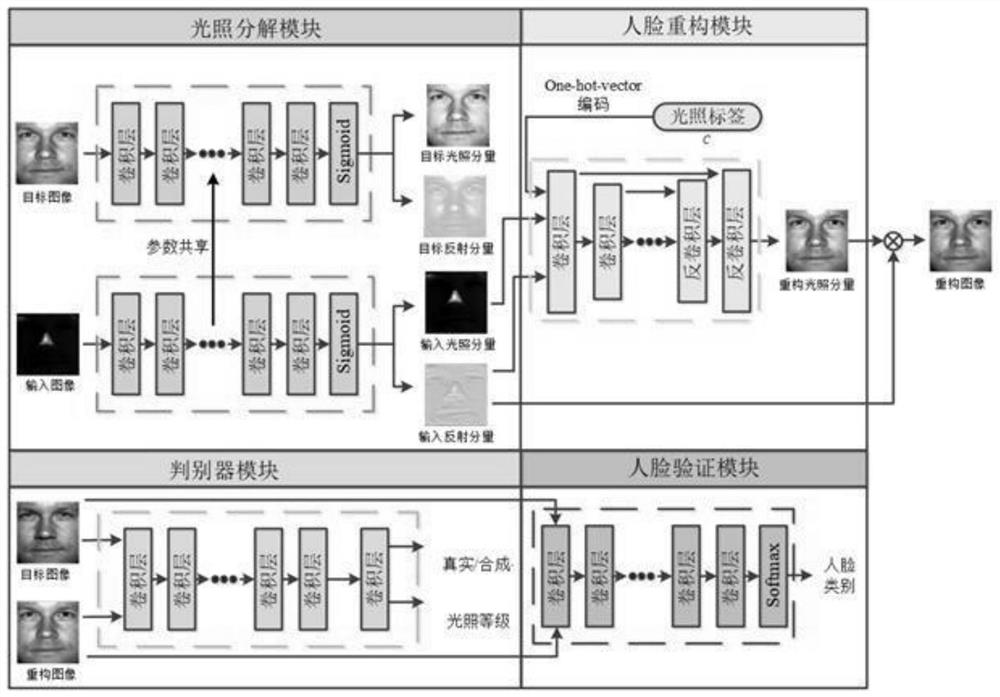
[0080] The invention provides a face illumination processing method based on Retinex decomposition and generation confrontation network. The model proposed by the method includes an illumination decomposition module, a face reconstruction module, a discriminator module and a face verification module. Among them, the illumination decomposition module extracts the reflection component and illumination component of the face image; the face reconstruction module adjusts the illumination level of the input face image; the discriminator module uses generative confrontation learning to ensure the authenticity of the synthesized face image; the face verification module retains Identity information for synthetic face images.
[0081] Refer to the specific process figure 1 As shown, this embodiment provides a face illumination processing method based on ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com