An improved Openpose-based classroom multi-person abnormal behavior and mask wearing detection method
A detection method and abnormal technology, applied to biological neural network models, instruments, computer components, etc., can solve the problems of high cost, lack of classroom teaching quality evaluation, lack of real-time performance, etc., and achieve the effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0060] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
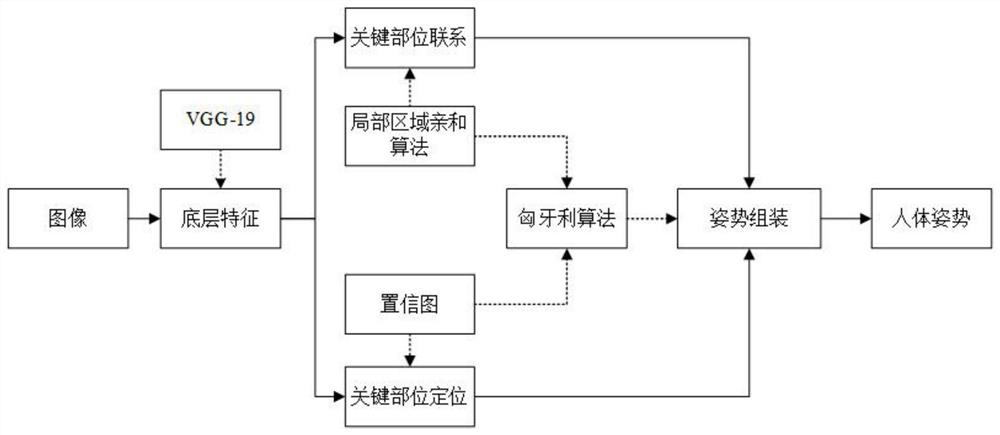
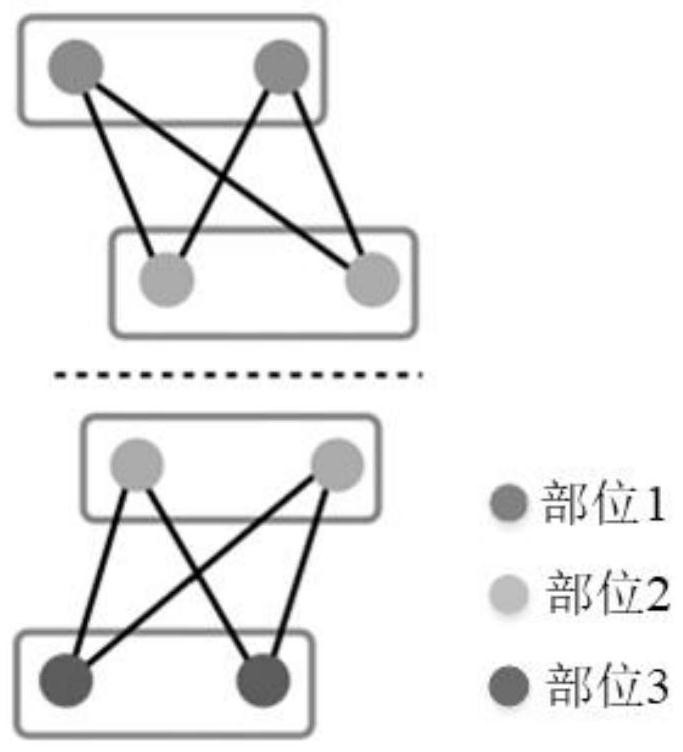
[0061] see Figure 1-27 , the present invention provides a kind of technical scheme: a kind of abnormal behavior of many people based on improved Openpose classroom and mask wearing detection method, comprises the following steps:
[0062] S1. Through the front-end and back-end cameras of the classroom, continuously shoot at a certain initial frame rate to obtain images of students in class;
[0063] S2. In the classroom attendance stage, the camera normally ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More