A method for caching read and write data hierarchically in a storage cluster
A technology for storing clusters and reading and writing data, which is applied in the field of cloud computing storage. It can solve problems such as low reading and writing speeds and affect the performance of cloud management operations, and achieve the effect of reducing delay and improving cloud management performance experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
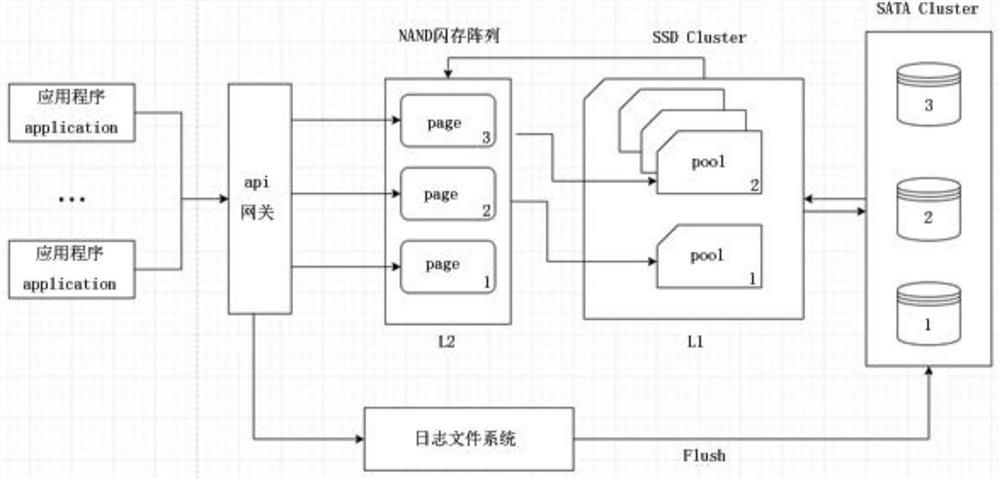
The second-level cache L2 adopts a NAND flash memory array, and the pool data of the first-level cache L1 is extracted into segments according to the index
Segment, and then save it in the form of Segment. The extracted segment Segment only stores the index and address of the pool data.
Each segment segment has a dynamically variable length, and the length of each segment segment is based on the flash space of the second level cache L2
Make free scheduling.
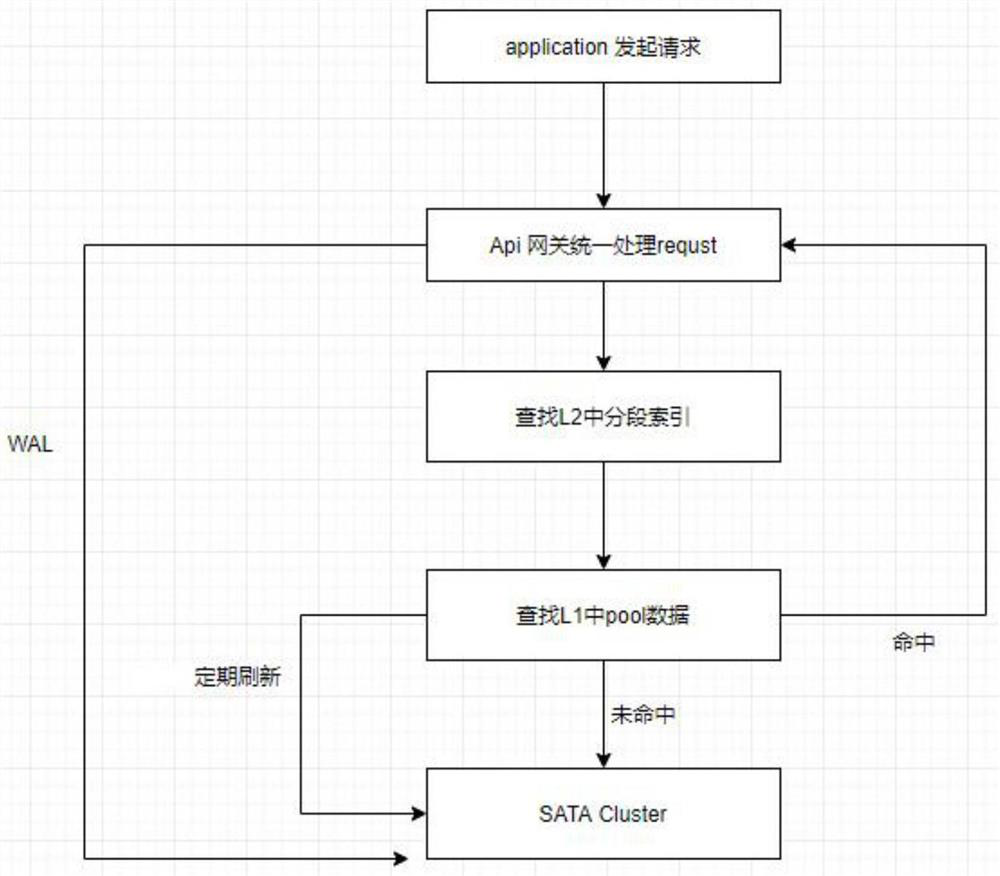
[0039] The api gateway, as the traffic entry of all requests, handles requests uniformly and merges the same request data.
[0040] The journaling file system stores data as write requests occur.
In the present embodiment, the first level cache is used as cache, and the size of the data block and the recall probability are determined according to the size of the data block.
The formula depends on performance goals, which include maximizing cache hit rate, minimizing average response time, and minimizing
The amount...
Embodiment 2
Segment, and then save it in the form of Segment. The extracted segment Segment only stores the index and address of the pool data.
Each segment segment has a dynamically variable length, and the length of each segment segment is based on the flash space of the second level cache L2
Make free scheduling. A second background thread is defined in the second level cache L2, and the second background thread is used to periodically clean up the second level
Cache dirty data for L2.
[0056] The api gateway is used as the traffic entry for all requests, and processes requests uniformly and merges the same request data.
[0057] The journaling file system stores data as write requests occur.
In this embodiment, the first-level cache is used as cache, and the size of the data block and the recall probability are determined according to the size of the data block.
The formula depends on performance goals, which include maximizing cache hit rate, minimizing average response time,...
Embodiment 3
[0069] On the basis of the structure of the first embodiment or the second embodiment, the GlusterFS cluster can also be used to replace the ceph cluster.
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap