

Video synthesis method and device, equipment and storage medium
A video synthesis and video technology, applied in the field of video processing, can solve problems affecting user experience, poor anchor video effect, voice content and lips are out of sync, etc., to achieve the effect of improving viewing experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
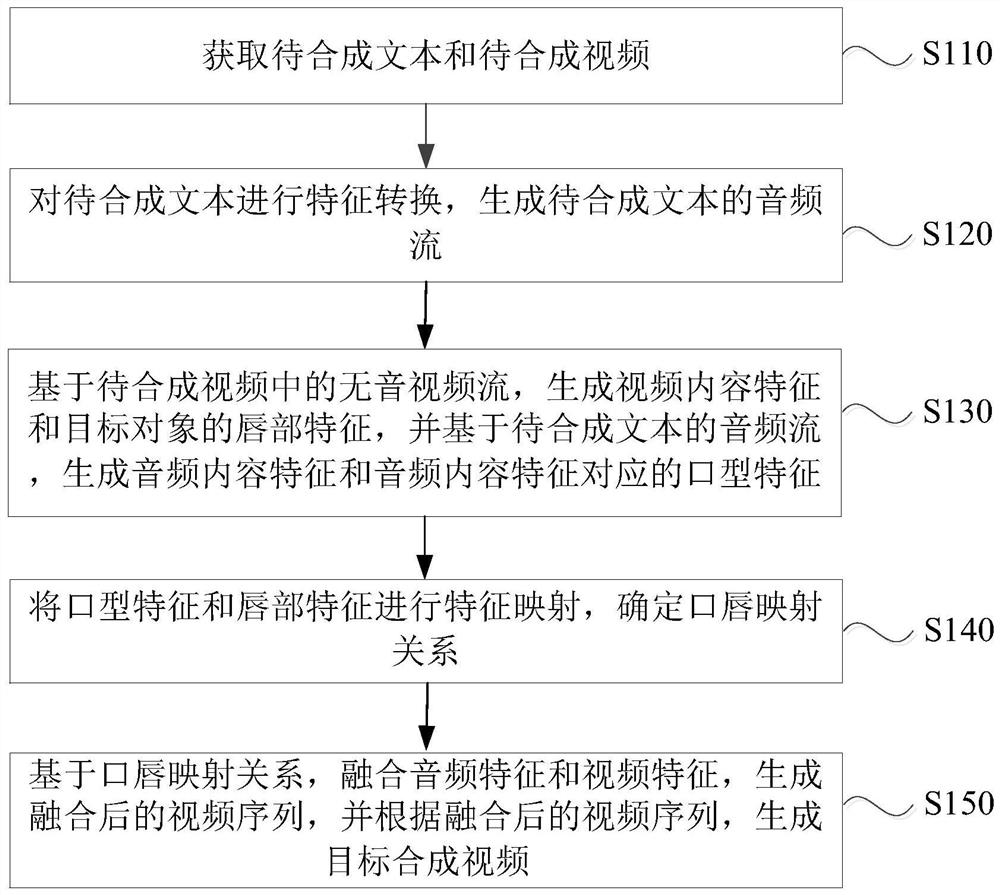
[0035] figure 1 It is a schematic flow chart of a video synthesis method provided by Embodiment 1 of the present invention. This embodiment is applicable to the case of performing video synthesis based on the text to be synthesized and the video to be synthesized. The method can be executed by a video synthesis device, wherein the system It can be implemented by software and / or hardware, and is generally integrated in a terminal or server. For details, see figure 1 As shown, the method may include the following steps:
[0036] S110. Acquire the text to be synthesized and the video to be synthesized.
[0037] Wherein, the text to be synthesized refers to a text file that needs to be played by the target object. The text to be synthesized may be Chinese text, English text, or text written in other languages, and the text to be synthesized may include advertisement content, factual content, meeting content, and the like. The video to be synthesized can be a video clip of any ...
Embodiment 2
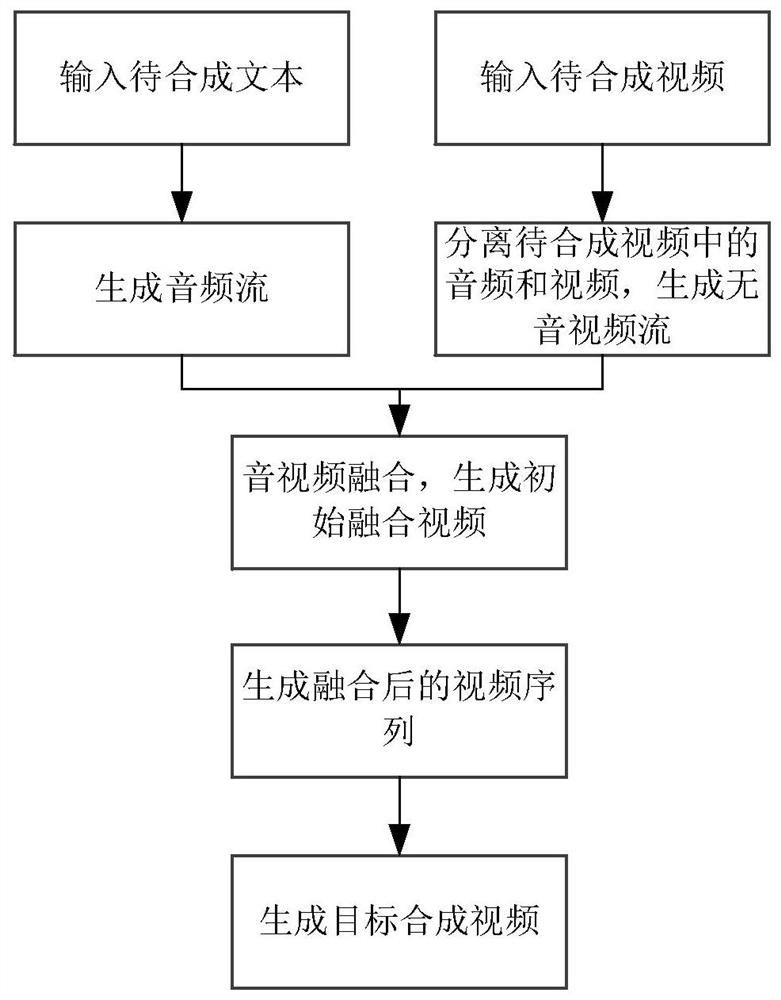
[0069] Figure 4 It is a schematic flowchart of a video synthesis method provided in Embodiment 2 of the present invention. The technical solution of this embodiment is refined on the basis of the above embodiments. Optionally, performing feature conversion on the text to be synthesized to generate an audio stream of the text to be synthesized includes: The text to be synthesized is input to the trained speech generation model, and the encoder based on the speech generation model performs feature extraction on the text to be synthesized to obtain the one-hot vector of the text to be synthesized; decoding based on the speech generation model The device converts the one-hot vector into a speech signal; based on the sequence generation sub-model of the speech generation model, inversely transforms the speech signal into a time-domain wave signal, and uses the time-domain wave signal as the to-be-synthesized The audio stream for the text. For the parts not described in detail in...
Embodiment 3
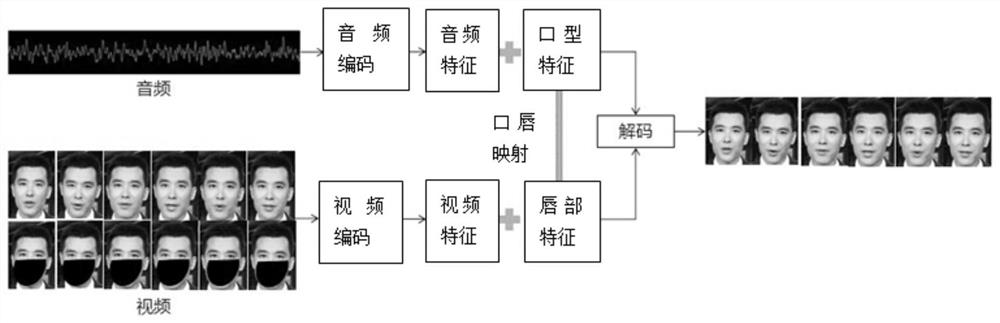
[0084] Figure 6 It is a schematic flowchart of a video synthesis method provided by Embodiment 3 of the present invention. The technical solution of this embodiment is refined on the basis of the foregoing embodiments. Specifically, the process of generating the video feature and the lip feature is refined. For the parts not described in detail in the method embodiment, please refer to the above embodiment. For details, see Figure 6 As shown, the method may include the following steps:
[0085] S310. Acquire the text to be synthesized and the video to be synthesized.
[0086] S320. Perform feature conversion on the text to be synthesized, and generate an audio stream of the text to be synthesized.
[0087] S330. Separate the video stream and the audio stream in the video to be synthesized to obtain an audio-free video stream, and combine the audio-free video stream and the audio stream of the text to be synthesized to generate an initial fusion video.
[0088] S340. Ex...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More