Speech enhancement method based on time-frequency domain joint loss function
A loss function, speech enhancement technology, applied in speech analysis, neural learning methods, instruments, etc., can solve problems affecting speech recognition accuracy, damage, speech enhancement phase mismatch, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

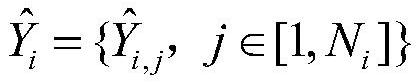
Examples
Embodiment Construction
[0068] This embodiment is used to implement training and testing based on the aishell speech set and the musan noise set.
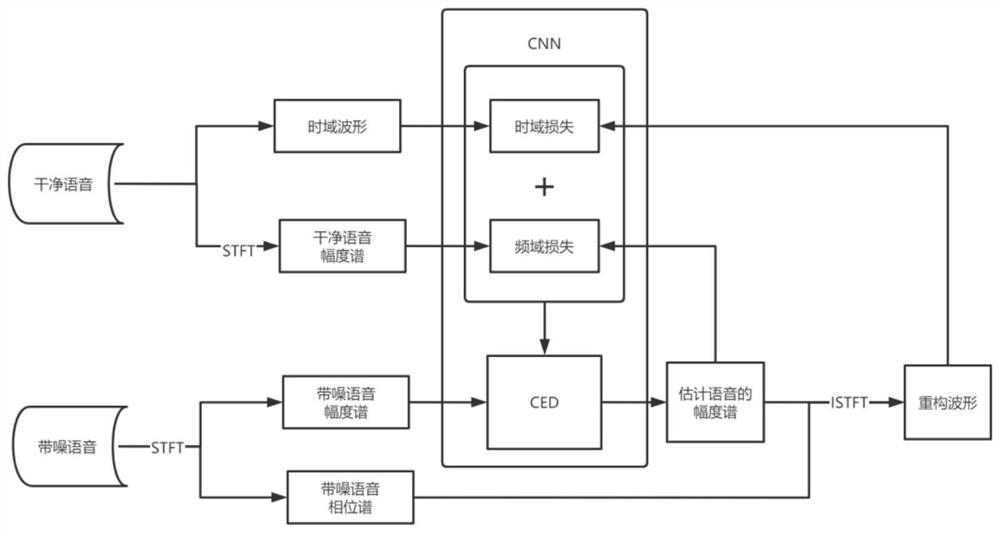
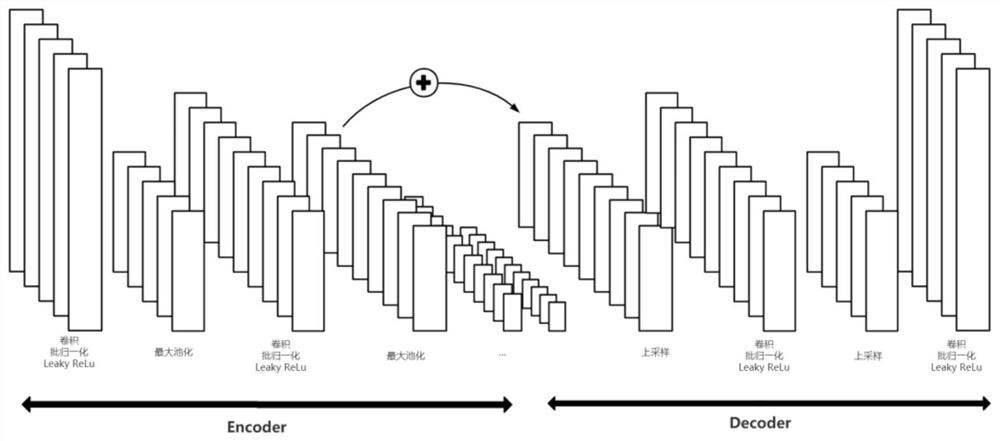
[0069] like figure 1 As shown, this embodiment performs speech enhancement and training based on a convolutional neural network (Convolutional Neural Network, CNN) model. Comparing with existing algorithms for speech enhancement by replacing the loss function with a joint loss function in the time-frequency domain.
[0070] The first embodiment of the present invention is a speech enhancement method based on a joint loss function in the time-frequency domain, and the specific steps are as follows:
[0071] Step 1: Assemble the clean speech data set and the noise data in the open source data set into a noisy speech data set. The clean speech in the clean speech data set is divided into frames and overlapped by the method of short-time Fourier transform, and converted into each clean speech. The frequency domain amplitude spectrum of speech, construct a c...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More