

Low-delay high-reliability V2V resource allocation method based on deep reinforcement learning
A technology of reinforcement learning and resource allocation, applied in the field of Internet of Vehicles, can solve the problems of not considering the energy consumption of V2V communication, the inability to expand large-scale networks, and the large transmission overhead, so as to maximize system energy efficiency, ensure reliability and delay requirements , The effect of maximizing energy efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
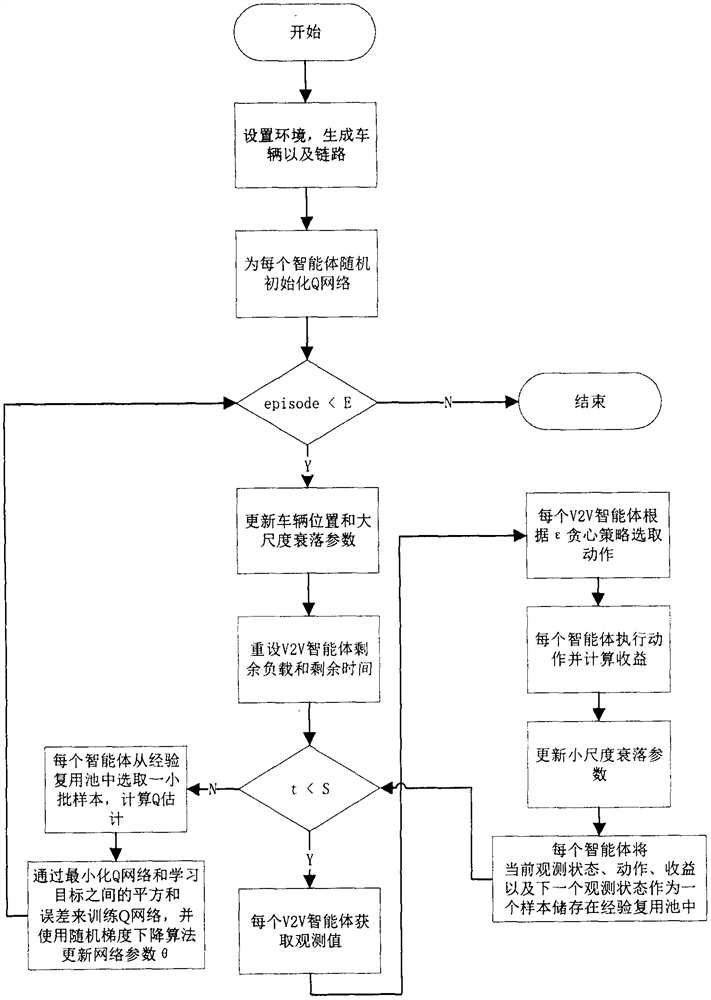
[0036] The core idea of the present invention is to propose a low-latency and high-reliability V2V resource allocation method based on deep reinforcement learning in order to enable the communication between vehicles outside the coverage of the base station to meet the delay requirements while maximizing energy efficiency. .
[0037] The present invention is described in further detail below.
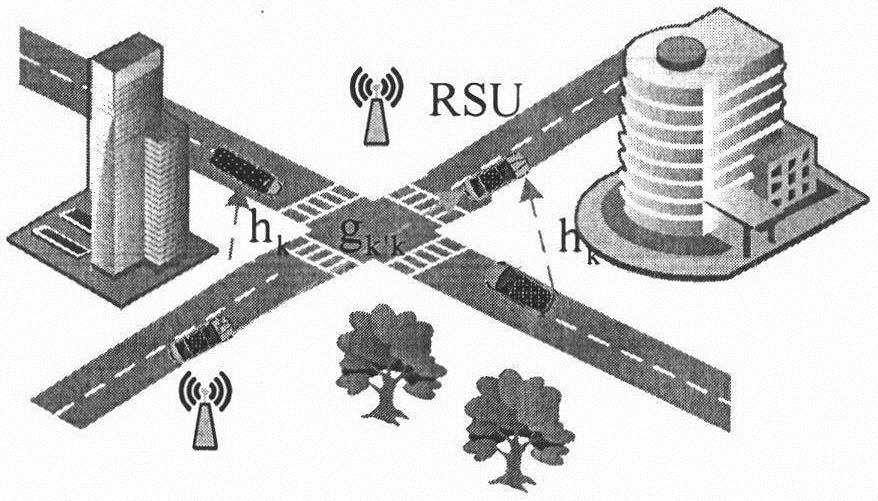
[0038] Step (1), considering the area not covered by the base station, in order to transmit data related to driving safety between vehicles (V2V), use URLLC slice resource blocks for communication;
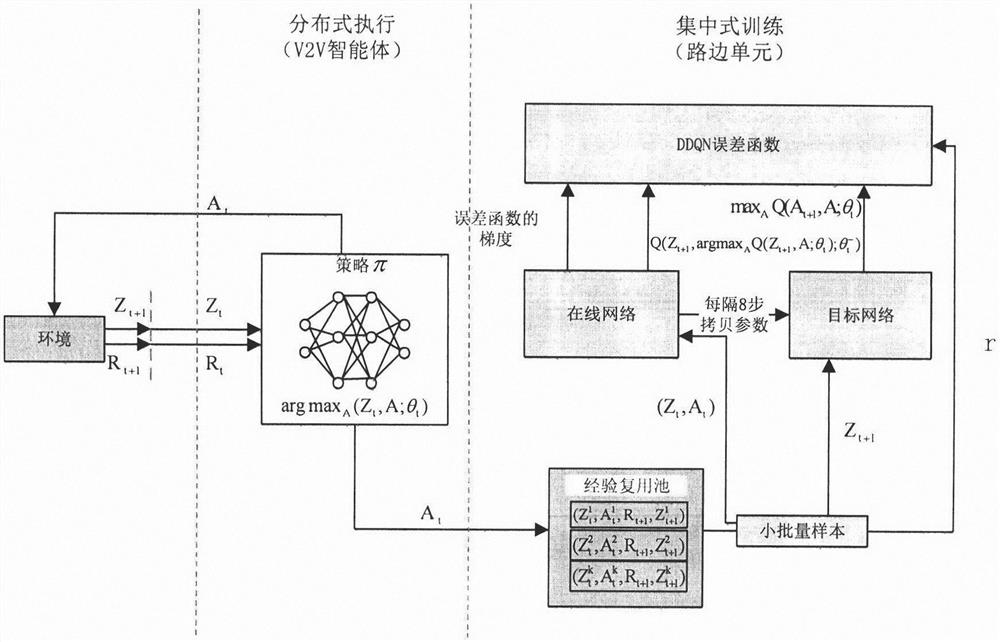
[0039]Step (2), the training phase, at each step, the V2V agent informs the computing unit of the current local observation information. The real environment state includes the global channel state and the behavior of all agents, which are agnostic to individual agents. Each V2V agent can only obtain part of the information that it can obtain, that is, observation information. The obser...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More