

Multi-modal Transformer image description method based on dynamic word embedding
An image description and multi-modal technology, applied in image coding, image data processing, character and pattern recognition, etc., can solve problems such as poor effect and insufficient semantic understanding of the model, so as to improve semantic understanding and semantic description ability , the effect of reducing the semantic gap problem
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
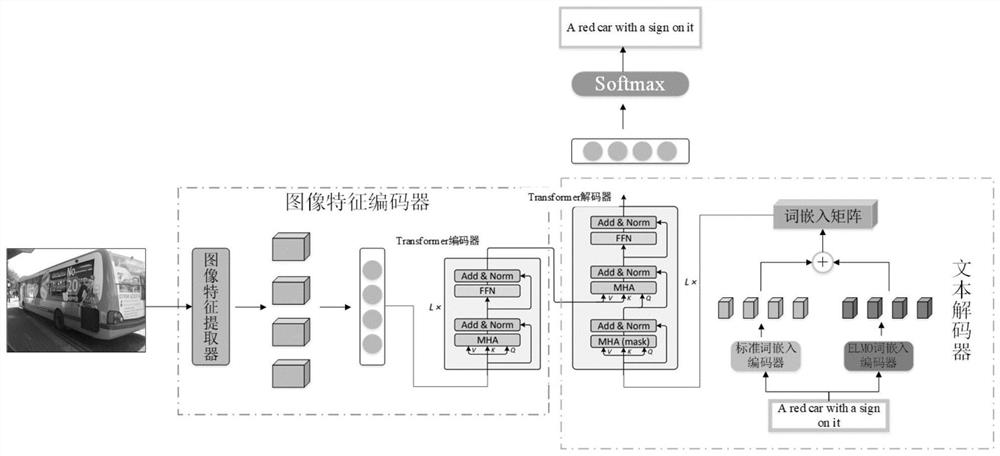
[0048] An image description method based on a dynamic word embedding multimodal Transformer, as follows figure 1 , 2 As shown, it specifically includes the following steps:
[0049] (1) Use the image feature extractor component to select the salient area of the image and extract the image features of the image: perform feature extraction on the target in the image to generate a more meaningful image feature matrix, such as Figure 4 As shown; feature extraction is performed on the target in each target frame in the image, and the feature matrix of the image is generated, and the size is (1024*46).
[0050] Wherein, for the salient area of the image, feature extraction is performed on the target in the image: for the obtained target area of the image, PCA is used to extract the main information in the target area of the image.
[0051]
[0052] Then the main information obtained Perform a linear transformation to the same feature dimension as the input to the nex...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More