

Visual question and answer and visual question and answer model training method and device, equipment and storage medium
A training method and visual technology, applied in the computer field, can solve problems such as the inability to capture the relationship between multiple texts, the inability to effectively understand the relationship between natural language text and visual content, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
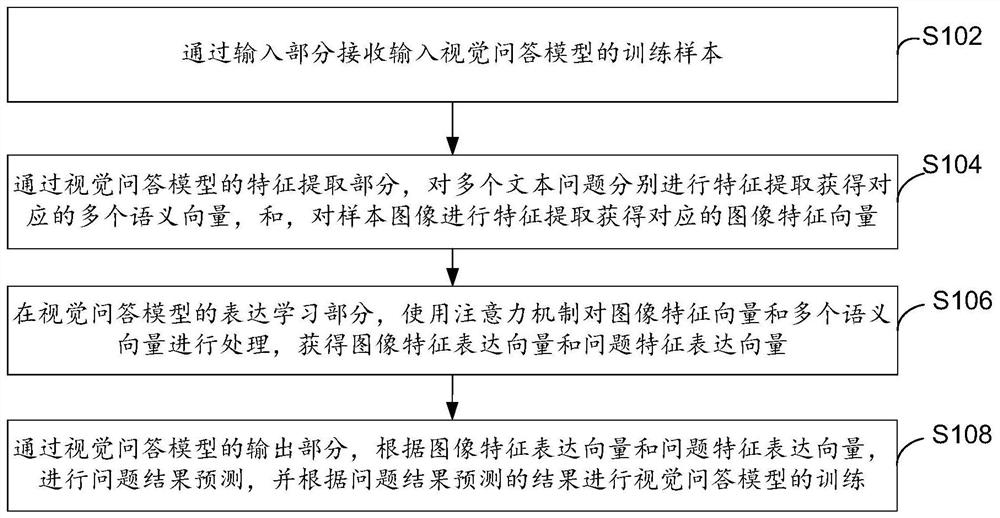
[0032] refer to Figure 1A, shows a flowchart of steps of a method for training a visual question answering model according to Embodiment 1 of the present invention.
[0033] The training method of the visual question answering model of the present embodiment comprises the following steps:
[0034] Step S102: Receive and input training samples of the visual question answering model through the input part.
[0035] In this embodiment, the visual question answering model includes an input part, a feature extraction part, an expression learning part and an output part. Wherein, the input part may be an input layer of the visual question answering model, through which data to be processed can be input to the visual question answering model. Specifically in this embodiment, what is input is a training sample, and the training sample includes a sample image and multiple text questions corresponding to the sample image.
[0036] It should be noted that, in the embodiments of the pr...
Embodiment 2
[0056] refer to figure 2 , shows a flowchart of steps of a method for training a visual question answering model according to Embodiment 2 of the present invention.
[0057] The training method of the visual question answering model of the present embodiment comprises the following steps:
[0058] Step S202: Receive and input training samples of the visual question answering model through the input part.
[0059] Wherein, the training samples include sample images and multiple text questions corresponding to the sample images. As mentioned above, there can be one or more sample images, and each sample image corresponds to multiple text questions.
[0060] Since there may be multiple sample images, in a feasible manner, the sample images may be multiple continuous video key frame images, and the multiple text questions are texts converted from audio corresponding to multiple video key frame images. Continuous multi-frame video frames can form a video clip. In a video clip, ...
Embodiment 3
[0085] refer to Figure 3A , shows a flowchart of steps of a method for training a visual question answering model according to Embodiment 3 of the present invention.
[0086] In this embodiment, a sample image is taken as an example of continuous video key frame images to illustrate the training method of the visual question answering model provided by the embodiment of the present invention.
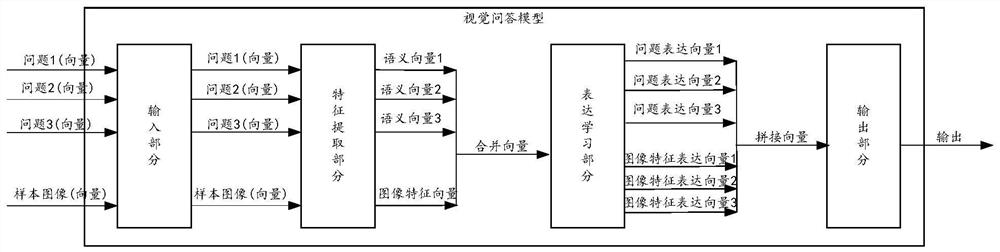
[0087] In this example, the visual question answering model used is Figure 3B As shown, it includes: input part, feature extraction part, expression learning part and output part.
[0088] Figure 3B In , the word vectors of 5 text questions and the corresponding vectors of 16 continuous video key frame images are input to the visual question answering model through the input part.
[0089] The feature extraction part adopts the form of Bi-GRU layer and FC layer for the text problem, wherein, after the FC layer, there are also ReLU layer and Dropout layer (the following is a brief ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More