

Roller Arbitration Method and Circuit for On-Chip Data Exchange
A technology of data exchange and arbitration method, which is applied in the direction of electrical digital data processing, digital computer components, architecture with a single central processing unit, etc., and can solve problems such as difficulty in realizing high-speed circuits, fairness and complexity, and difficult iterative arbitration , to achieve the effect of easy high-speed circuit, short arbitration time and simple judgment logic
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0049] The present invention will be further described below in conjunction with embodiment, but protection scope of the present invention is not limited to this:
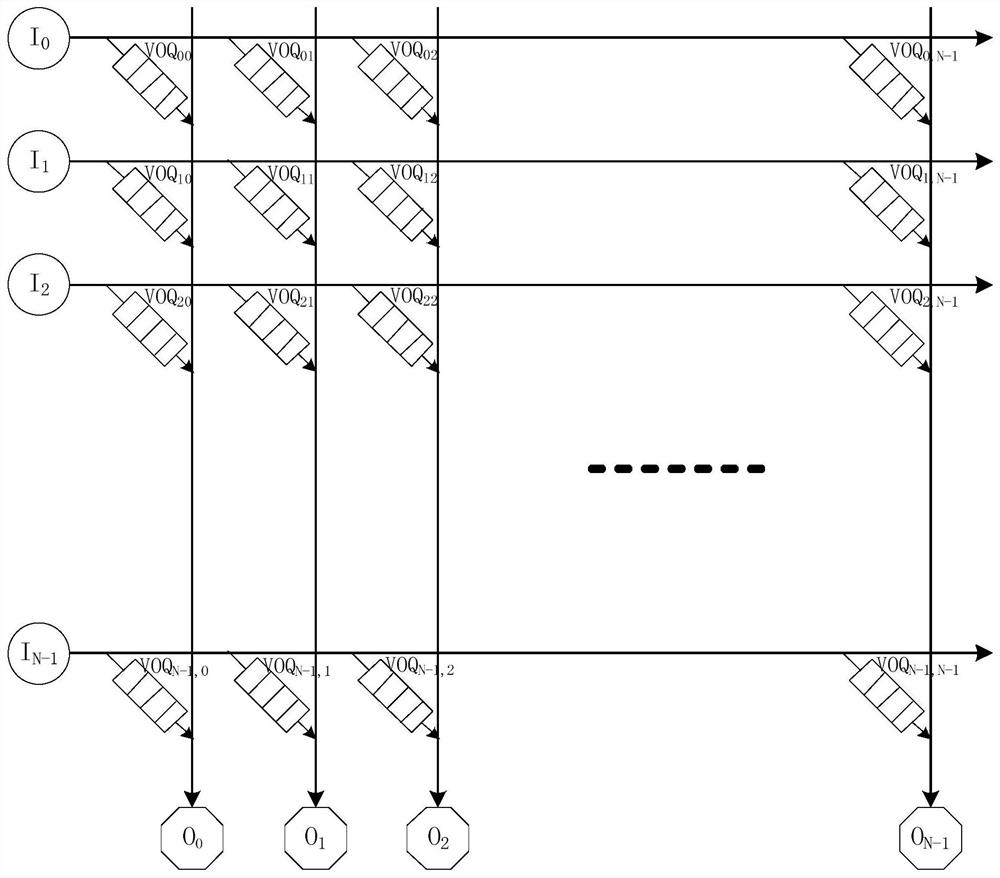
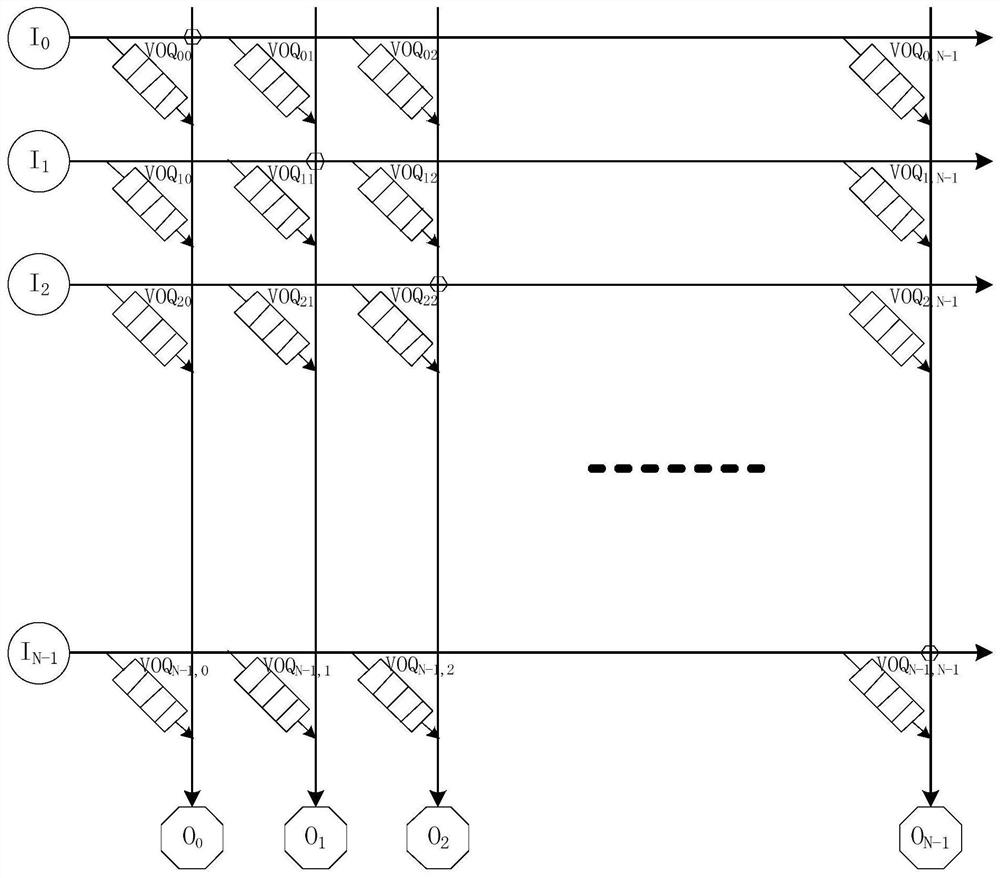
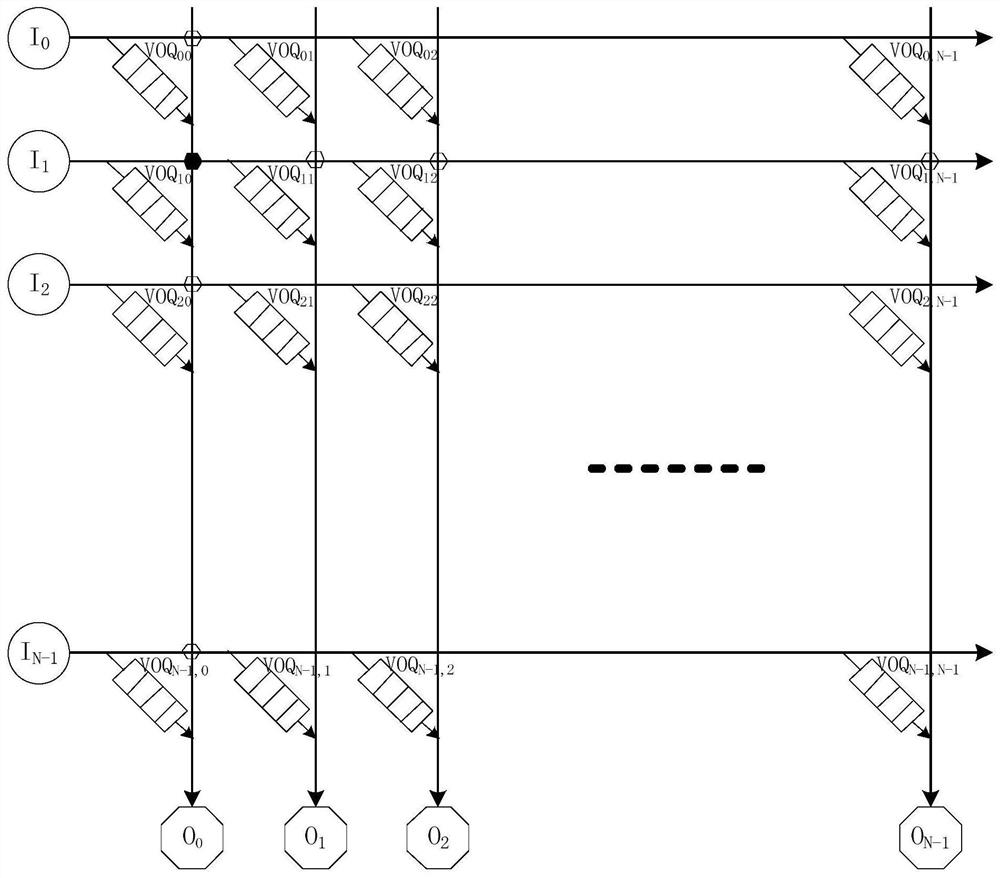
[0050] figure 1 An NxN cross network routing structure is given: each intersection of I0, I1, ..., IN-1 and O0, O1, ..., ON-1 is a routing path, also called a transmission pair. Each intersection is a VOQij request path, the first number of the VOQ subscript indicates the input port number, and the second number indicates the output port number. Each input port Ii can only have one routing node selected in one cycle, and each output port can only have one routing node selected in one cycle. There are at most N paths selected in one cycle.
[0051] In order to ensure that each input port realizes fair arbitration, each input port obtains the data transmission volume as equal as possible, and each virtual output queue VOQ of each input port obtains the data transmission volume as equal as possible, the invention di...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More