

System and method for end-to-end speech recognition with triggered attention
A speech recognition and attention technology, applied in speech recognition, speech analysis, neural learning methods, etc., can solve problems that are not suitable for online/streaming transmission
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
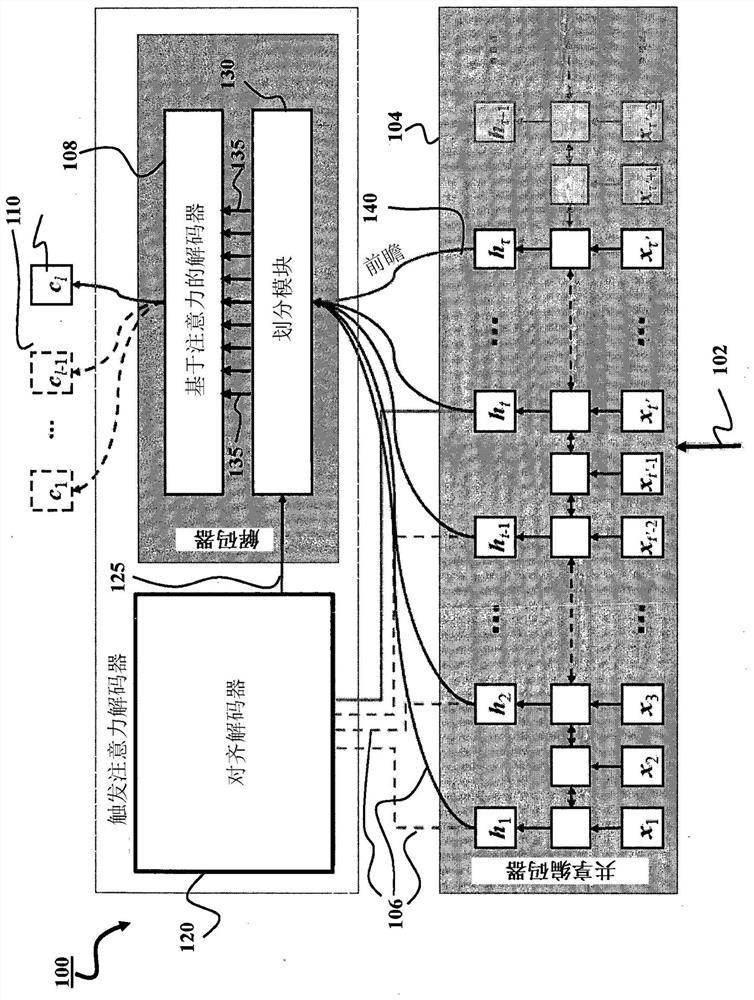
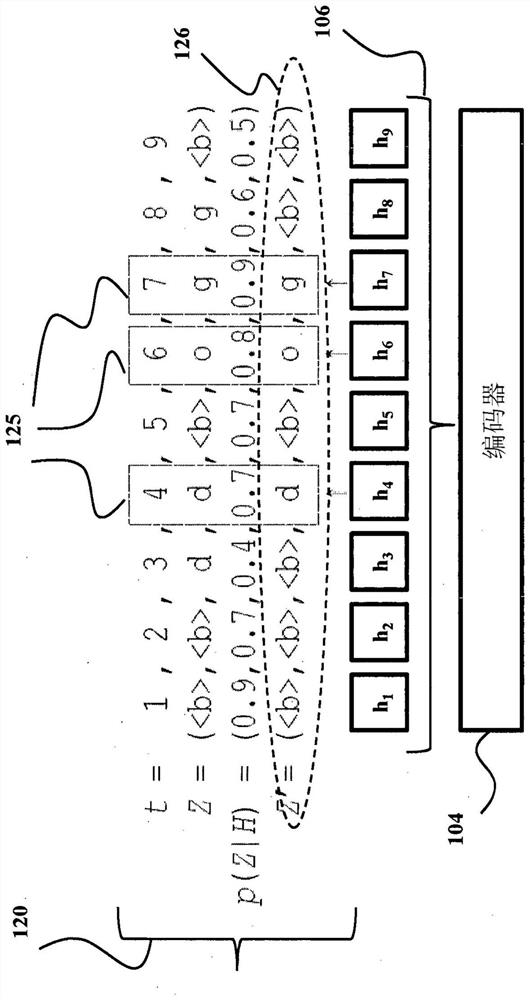
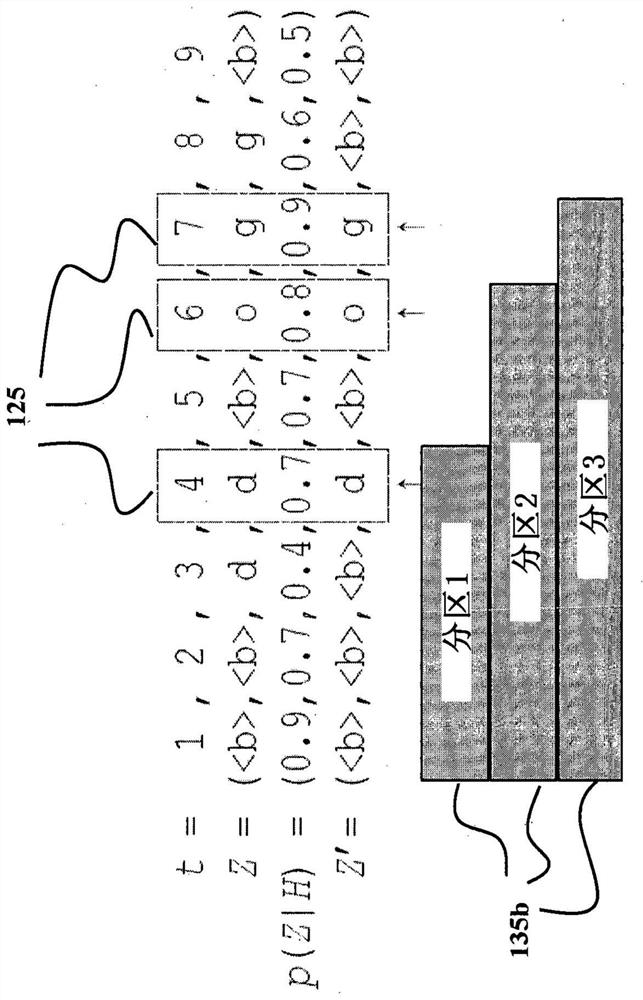
[0047] figure 1 A schematic diagram of a speech recognition system (ASR) 100 configured for end-to-end speech recognition is shown, according to some implementations. The speech recognition system 100 takes an input acoustic sequence and processes the input acoustic sequence to generate a transcribed output sequence. Each transcription output sequence is a transcription of the utterance or part of an utterance represented by the corresponding input acoustic signal. For example, speech recognition system 100 may take input acoustic signal 102 and generate a corresponding transcription output 110 , which is a transcription of the utterance represented by input acoustic signal 102 .
[0048] The input acoustic signal 102 may include a multi-frame sequence, eg, a continuous data stream, of audio data that is a digital representation of an utterance. The sequence of frames of audio data may correspond to a sequence of time steps, eg, where each frame of audio data is associated w...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More