

Online shop big data processing method and device, equipment and storage medium
A big data processing and data technology, applied in the field of data processing, can solve the problems of partition scan failure, slow execution speed, slow data reading, etc., and achieve the effect of reducing reading failure, scheduling commodity data volume stably, and improving scheduling speed.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

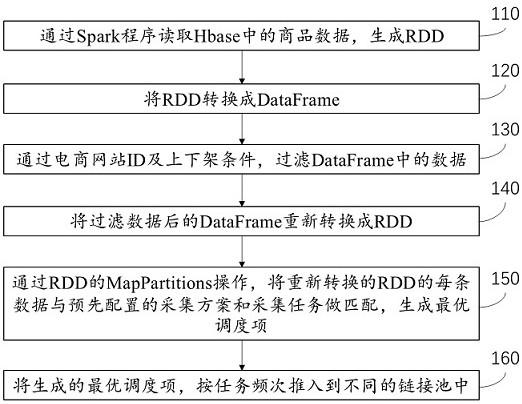


Examples
Embodiment Construction
[0036] Preferred embodiments of the present invention will be described in more detail below with reference to the accompanying drawings. Although preferred embodiments of the invention are shown in the drawings, it should be understood that the invention may be embodied in various forms and should not be limited to the embodiments set forth herein. Rather, these embodiments are provided so that this disclosure will be thorough and complete, and will fully convey the scope of the invention to those skilled in the art.
[0037] The terminology used in the present invention is for the purpose of describing particular embodiments only and is not intended to limit the invention. As used herein and in the appended claims, the singular forms "a", "the", and "the" are intended to include the plural forms as well, unless the context clearly dictates otherwise. It should also be understood that the term "and / or" as used herein refers to and includes any and all possible combinations o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More