

End-to-end text-independent voiceprint recognition method and system
A voiceprint recognition, text-independent technology, applied in speech analysis, instruments, etc., can solve the problem of low voiceprint recognition accuracy, and achieve the effect of reducing intra-class distance, improving accuracy, and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
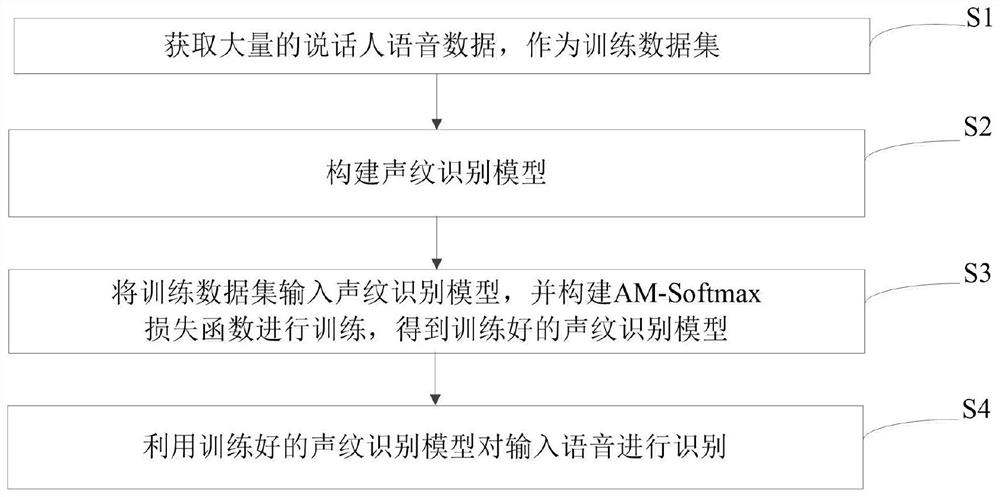
[0036] An embodiment of the present invention provides an end-to-end text-independent voiceprint recognition method, including:
[0037] S1: Obtain a large amount of speaker voice data as a training data set;
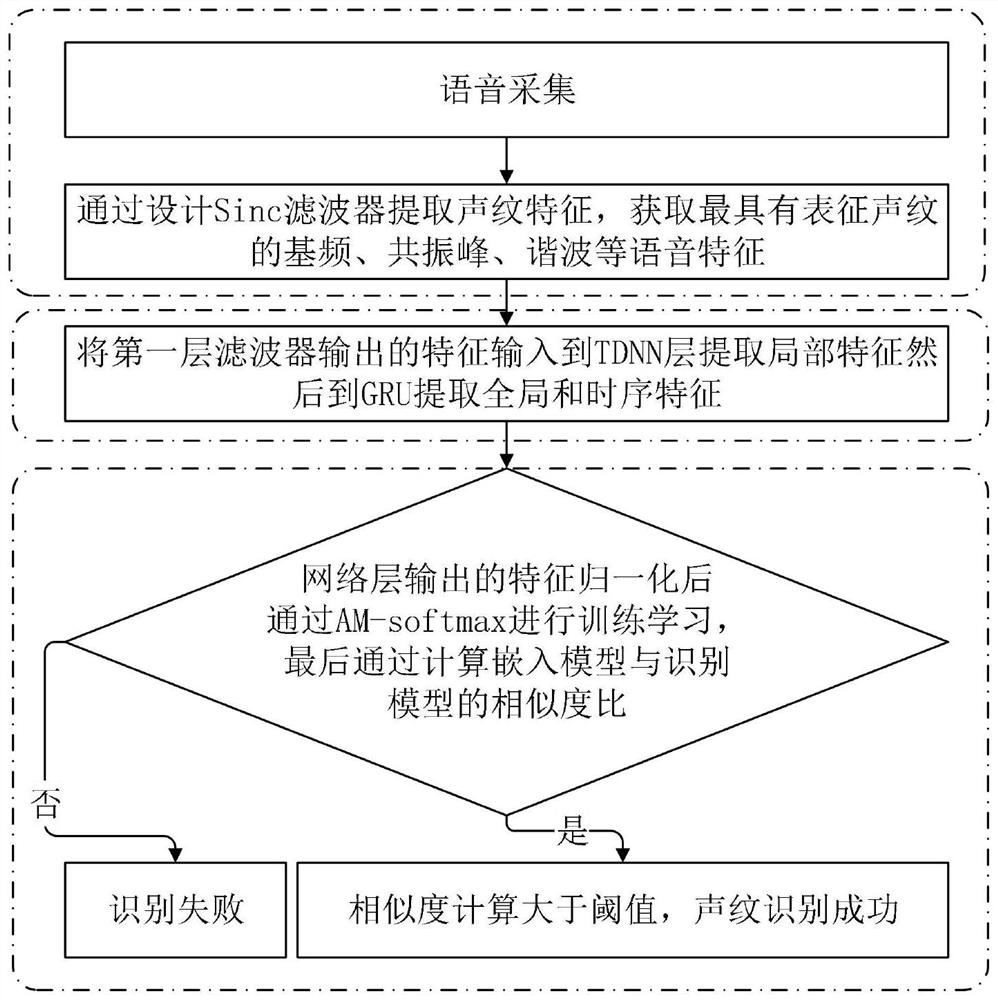
[0038]S2: Build a voiceprint recognition model, in which the voiceprint recognition model includes a frame-level feature extraction layer, an utterance-level feature extraction layer, a high-order attention pooling layer, and a fully connected layer. The frame-level feature extraction layer includes three time-delay neural networks. The network TDNN is used to extract frame-level features in the input speech data; the utterance-level feature extraction layer includes three gated recurrent units GRU, which are used to perform global feature extraction and temporal representation of frame-level features to generate utterance-level features; The attention pooling layer includes a high-order statistical pooling layer and a high-order attention pooling layer. The high-order ...
Embodiment 2
[0085] Based on the same inventive concept, this embodiment provides an end-to-end text-independent voiceprint recognition system, please refer to Figure 5 , the system consists of:
[0086] The training data set obtaining module 201 is used to obtain a large amount of speaker voice data as a training data set;
[0087] The voiceprint recognition model construction module 202 is used to build a voiceprint recognition model, wherein the voiceprint recognition model includes a frame-level feature extraction layer, a speech-level feature extraction layer, a high-order attention pooling layer, and a fully connected layer. The extraction layer includes three time-delay neural networks TDNN for extracting frame-level features in the input speech data; the utterance-level feature extraction layer includes three gated recurrent units GRU for global feature extraction and temporal representation of frame-level features , to generate utterance-level features; the high-order attention ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More