N-element non-autoregressive speech synthesis method and device and electronic equipment
A speech synthesis and autoregressive technology, applied in speech synthesis, speech analysis, instruments, etc., can solve the problems of high complexity and fitting ability of Mel spectrum decoder, requirements, etc., to reduce work requirements and improve robustness Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
preparation example Construction
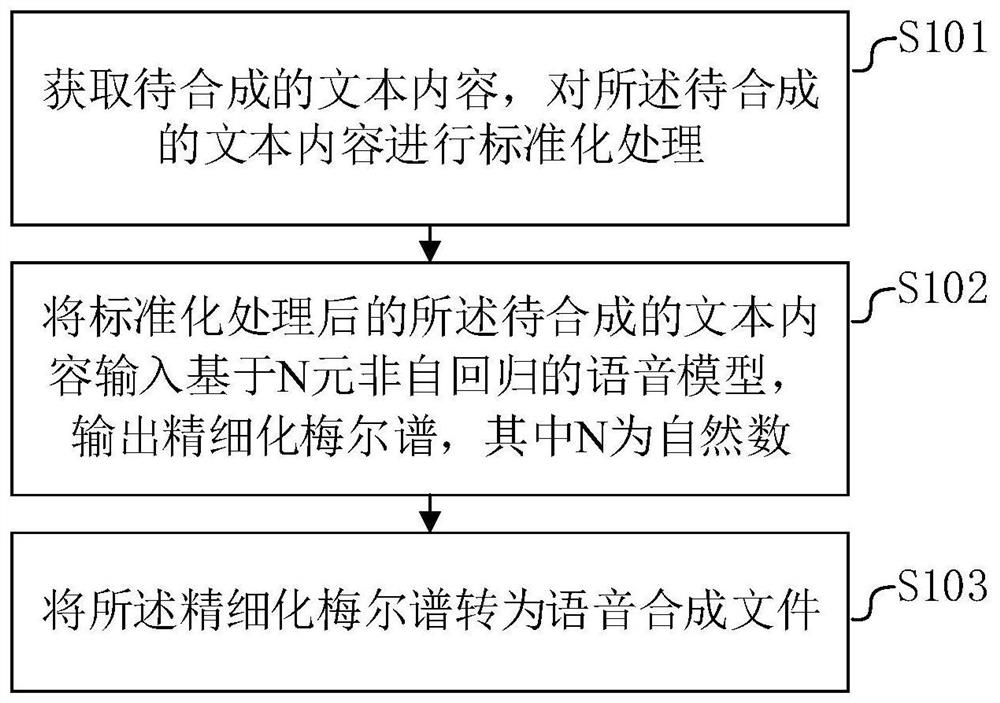
[0046] figure 1 is a schematic flow chart of an N-ary non-autoregressive speech synthesis method, such as figure 1 As shown, the methods include:
[0047] S101. Acquire text content to be synthesized, and perform standardization processing on the text content to be synthesized.
[0048] In this embodiment, since the input text content contains a lot of non-standard text content, such as punctuation, numbers, symbols and other words or words, the N-element non-autoregressive speech model cannot convert these non-standard text information It is a mel spectrum, so the text content needs to be normalized.
[0049] On the basis of the above technical solution, further, the flow chart of standardizing the text content to be synthesized is as follows: figure 2 shown, including:
[0050] S1011. Segment the to-be-synthesized text content into short sentences.
[0051] In this embodiment, the input text content is usually the content of the entire paragraph, including multiple lon...
Embodiment 1
[0079] S201. Input the text "ZYB".
[0080] S202. Standardize "ZYB".
[0081] Here, as an example, it is assumed that the content of the input text “ZYB” remains unchanged before and after normalization, so the pronunciation sequence after normalization is “ZYB”.
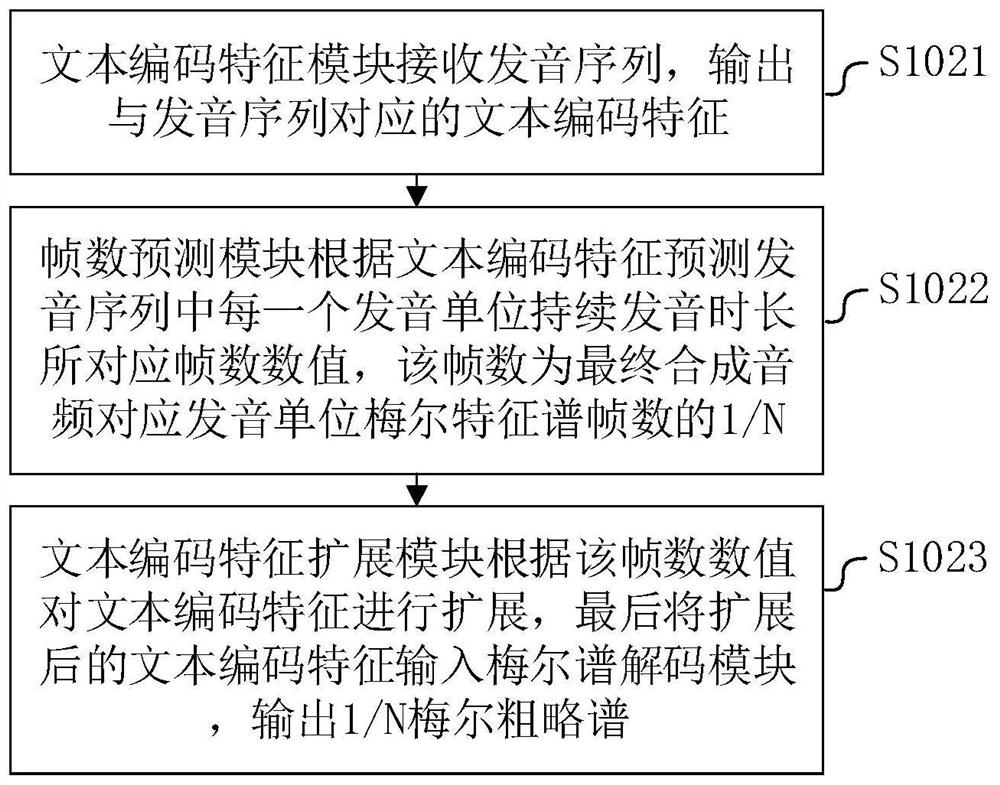
[0082] S203. The text feature encoding module receives the pronunciation sequence, and outputs the text encoding features "Z', Y', B'".
[0083] S204. The frame number prediction module predicts the frame number value of the pronunciation sequence.
[0084] In this embodiment, it is assumed that the input text "ZYB" and the final synthesized audio corresponding to the spectrogram corresponding to the Meltep exact frame number (pfn, precise frame number) are respectively: pfn1=2, pfn2=4, pfn3=4 .
[0085] Assuming that N is 2, then when the frame number prediction module is predicting, the predicted frame numbers (rfn, roughth frame number) corresponding to the ZYB pronunciation sequence are:
[0086]
[0087]...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com