
Patsnap Eureka
For R&D, Patsnap Eureka makes reading and utilizing patents & technical documents easy.
Patsnap Eureka AIR
Designed for self-driven R&D workflows. Generate viable solutions, solve complex R&D challenges, empower your innovation with AI.

Patsnap Eureka Materials
Designed for material experts only. Revolutionize your material R&D, from search, analyze, to developing new materials.

TechResearch
Generate reliable direction feasibility study reports for your R&D in just a few steps.

TechSeek
Discover and master advanced knowledge NOW. Basics, ideas, possibilities, all at once.

TechMind
As an expert in R&D Theories, TechMind can generates customized viable solutions instantly.

TechRisk
Analyze your overall solution with one click, know your potential R&D risks in advance.

TechMonitor
Get weekly tech updates, stay abreast of the latest tech innovations and key insights.
Deployment method and system of reasoning server supporting multiple models and multiple chips and electronic equipment
A server and multi-chip technology, applied in the computer field, can solve the problems of accelerated processor deployment that is not easy and only supports, and achieve the effect of improving operating performance and good scalability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
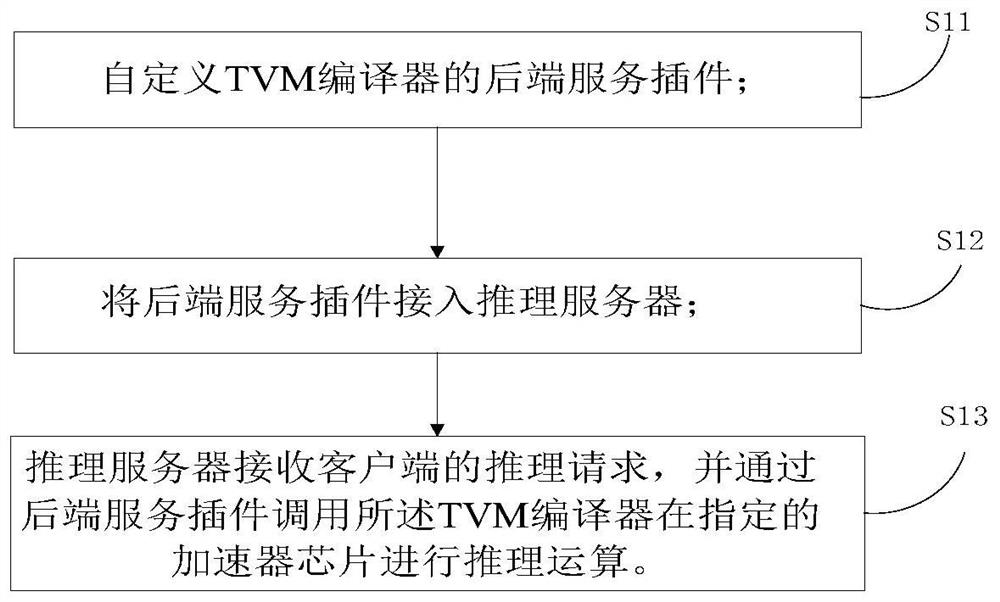
[0034] figure 1 It is a flowchart of a method for deploying an inference server supporting multiple models and multiple chips in Embodiment 1 of the present invention. This embodiment is applicable to the situation where the inference service framework is deployed uniformly, and the method can be executed by a deployment system supporting multi-model and multi-chip inference servers. The system can be implemented by software and / or hardware, and Integrated in a server, wherein the reasoning server can be configured in the server.
[0035] For the convenience of description and understanding, the deployment process of the present invention will be described in detail in the subsequent description by taking the Triton reasoning server as an example. However, this method is not limited to the application of Triton inference server, and inference servers such as tensorflowserving or torchserve can also be used.
[0036] Triton Inference Server is an open source inference framewo...
Embodiment 2
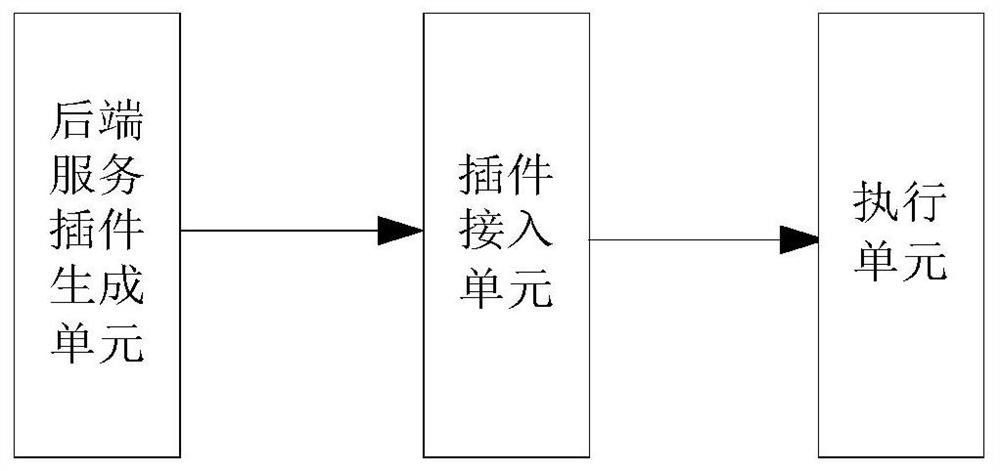
[0079] figure 2 It is a schematic structural diagram of a deployment system of an inference server supporting multiple models and multiple chips in Embodiment 2 of the present application. Such as figure 2 As shown, the deployment system includes: a backend service plug-in generation unit, a plug-in access unit, and an execution unit.
[0080] Wherein, the back-end service plug-in generation unit is used to generate a TVM compiler back-end service plug-in conforming to the specified format according to the specified format accessed by the back-end of the reasoning server;
[0081] A plug-in access unit, configured to connect the back-end service plug-in to the reasoning server;
[0082] The execution unit is used to call the TVM compiler through the backend service plug-in to perform inference operations on the specified accelerator chip according to the inference request of the client. Wherein, when the DSP loaded with TVM is running, the DSP chip is used for reasoning, ...
Embodiment 3
[0085] According to the embodiments disclosed in the present application, the present application also provides an electronic device, a readable storage medium, and a computer program product.
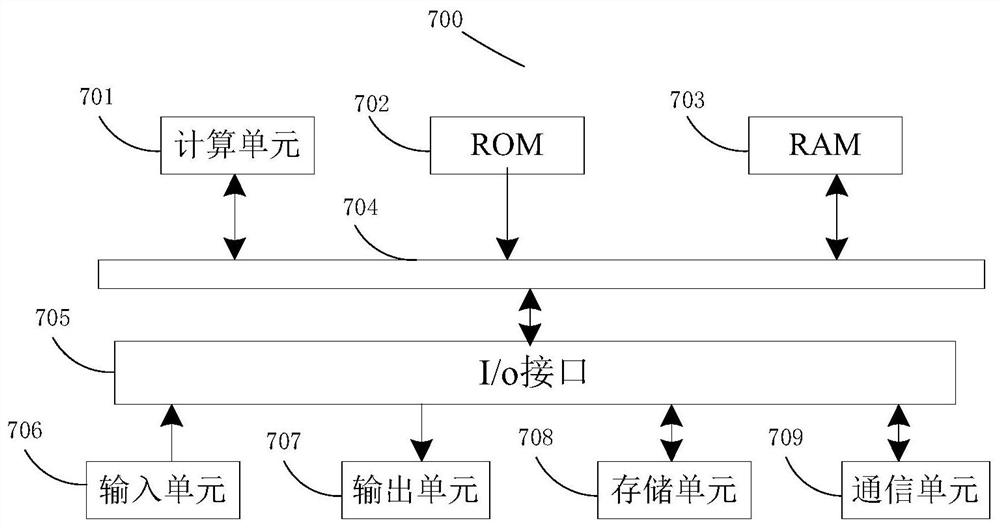
[0086] image 3 A schematic block diagram of an example electronic device 700 that may be used to implement embodiments disclosed herein is shown. Electronic device is intended to represent various forms of digital computers, such as laptops, desktops, workstations, personal digital assistants, servers, blade servers, mainframes, and other suitable computers. Electronic devices may also represent various forms of mobile devices, such as personal digital processing, cellular telephones, smart phones, wearable devices, and other similar computing devices. The components shown herein, their connections and relationships, and their functions, are by way of example only, and are not intended to limit implementations of the present disclosure described and / or claimed herein.
[0087] Such ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com