Two-stage resampling method for unbalanced data
A two-stage, resampling technology, applied in neural learning methods, instruments, biological neural network models, etc., can solve problems such as unbalanced data, distribution characteristics and difficult synthesis of samples, etc., to improve quality, improve classification performance indicators, and enrich and diversify sexual effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0038] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
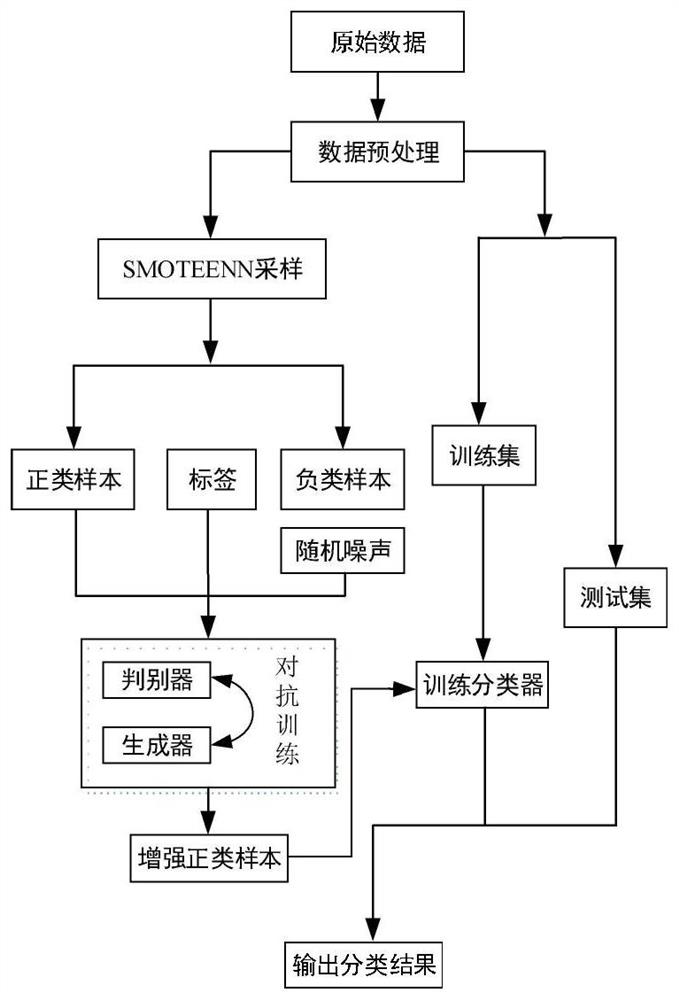
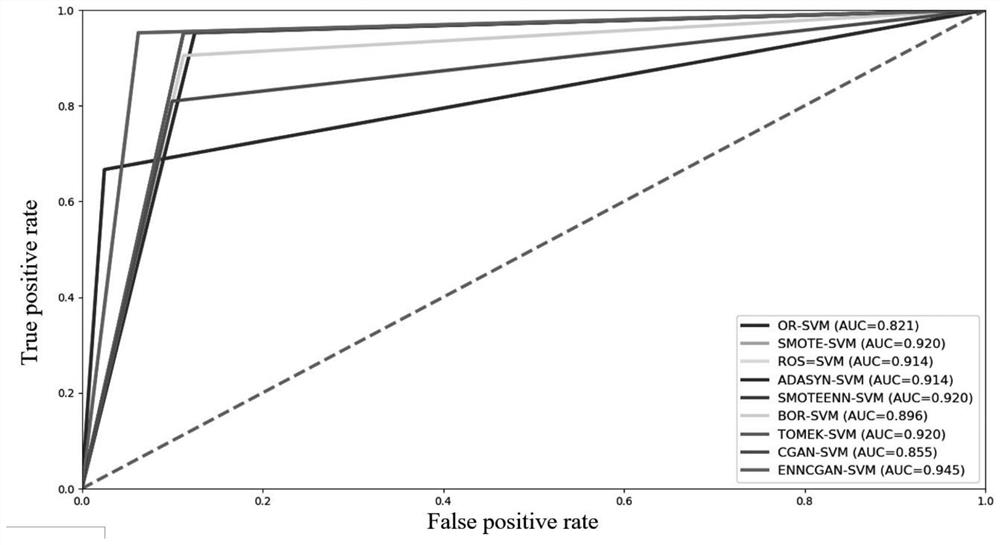
[0039] The technical solution adopted in the present invention is a two-stage resampling method for unbalanced data, and the overall process of the present invention is as follows figure 1 As shown, the specific steps of the invention and related pseudocodes are shown in Algorithm 1.
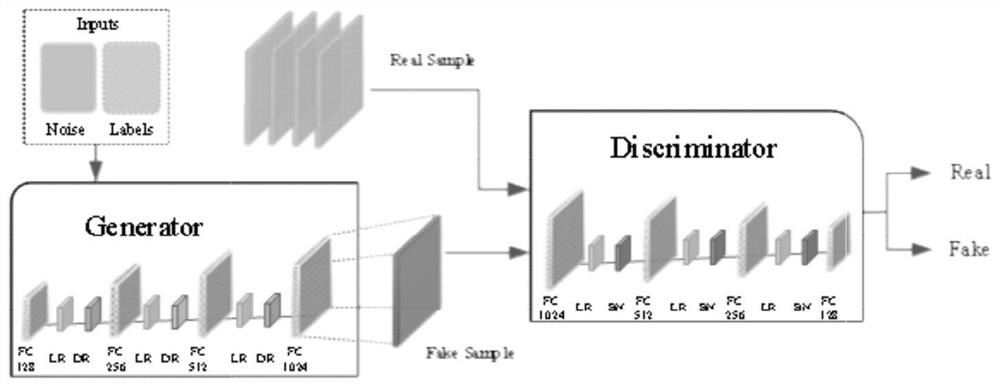
[0040] Algorithm 1: Imbalanced data classification preprocessing method based on CGAN and SMOTEENN
[0041] Input: the original unbalanced dataset S after normalization;
[0042] Output: classification results after sample set processing
[0043] Step 1: Divide the unbalanced data set S after data normalization processing into training sets Strain and Stest, record the number of positive and negative samples in the training set as S0, S1, and add_num=S1-S0 the number of generated samples
[0044] Step 2: Use the SMOTEENN method to oversample the original unbal...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com