

Visual model training and video processing method and device, equipment and storage medium
A visual model and training method technology, applied in the field of artificial intelligence, can solve the problems of low accuracy of similar videos and large differences in visual features, and achieve the effect of solving scene conversion problems, high feature discrimination, and high discrimination
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

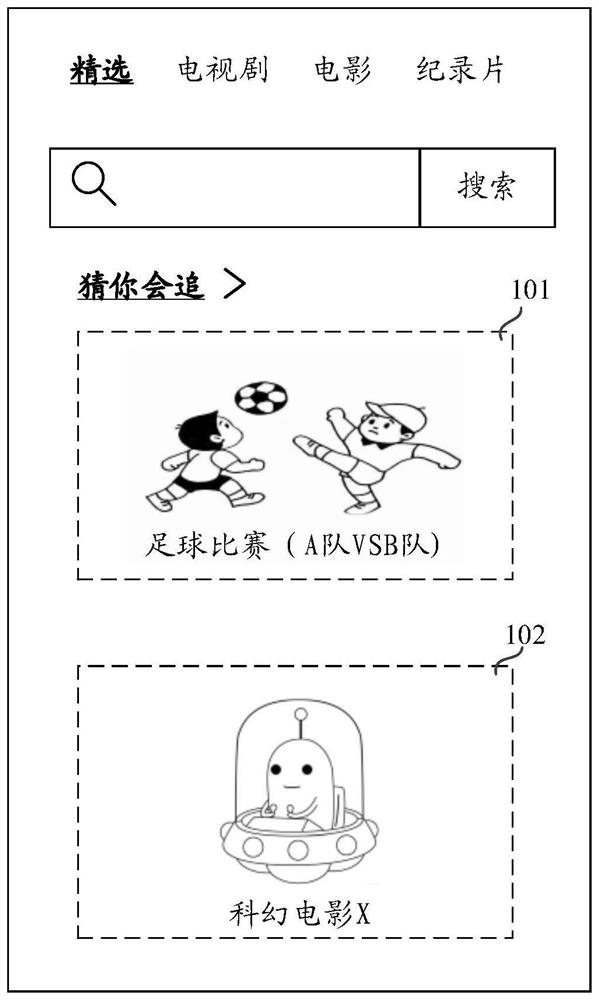
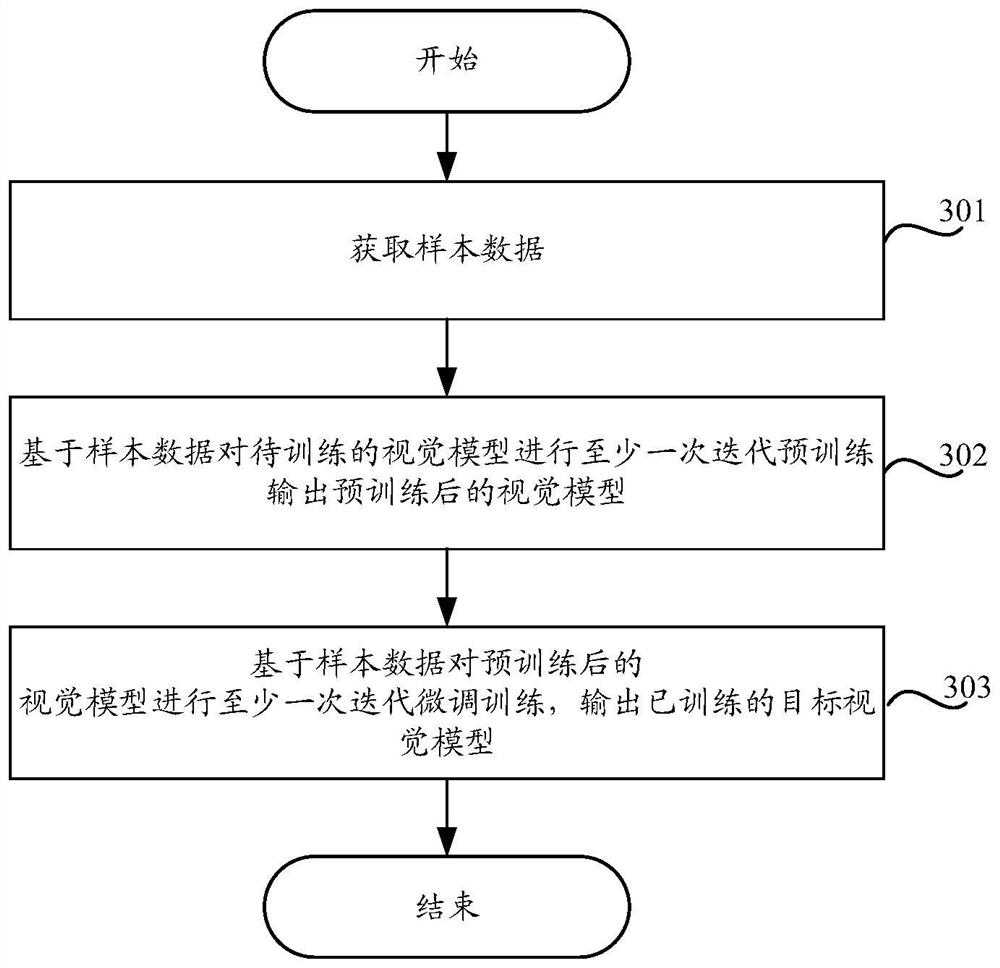
Examples
Embodiment approach 1
[0176] Embodiment 1. Using a pre-trained visual model, feature extraction is performed on each sample video frame to obtain the target sample visual features corresponding to each sample video frame. Then, based on the obtained visual features of the target samples, the predicted video categories corresponding to each sample video frame are respectively predicted. Based on the predicted video categories corresponding to each sample video frame in the selected sample video frame set, a corresponding second loss function is obtained, and then the parameters of the pre-trained visual model are adjusted by using the second loss function.
[0177] Specifically, since each set of sample video frames in the sample data corresponds to different sample videos, the predicted video categories of sample video frames corresponding to the same sample video should be the same, while the predicted video categories of sample video frames corresponding to different sample videos The categories ...
Embodiment approach 2
[0184] Embodiment 2: Using a pre-trained visual model, feature extraction is performed on each sample video frame, and the target sample visual features corresponding to each sample video frame are obtained. Then, based on the obtained visual features of the target samples, the predicted video categories corresponding to each sample video frame are respectively predicted. Based on the predicted video category corresponding to each sample video frame in the selected sample video frame set, a corresponding second loss function is obtained.
[0185] Based on the target sample visual features corresponding to each sample video frame, the prediction canvas area corresponding to each sample video frame is determined. Then, the fourth loss function is determined based on the prediction canvas area corresponding to each sample video frame and the reference canvas area corresponding to each sample video frame. The second loss function and the fourth loss function are used to adjust th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More