

End-to-end bone and air conduction voice combined recognition method
A recognition method and speech technology, applied in speech recognition, speech analysis, instruments, etc., to improve the recognition performance and reduce the error rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

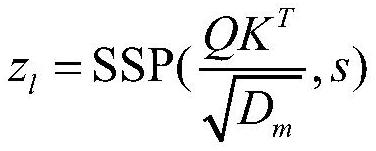
Examples
specific Embodiment
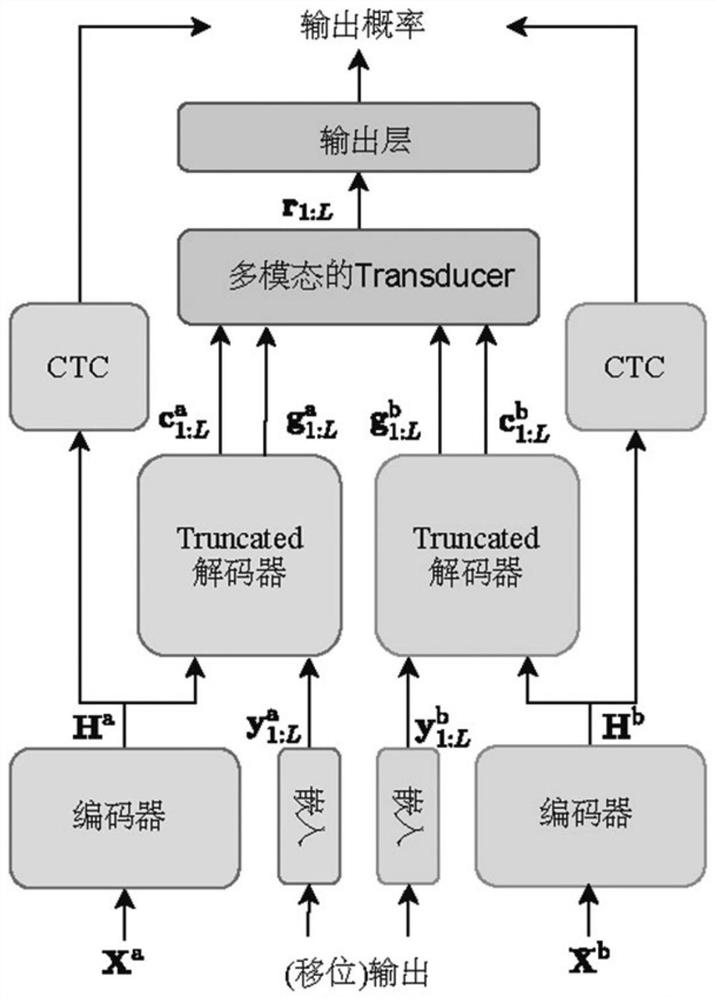
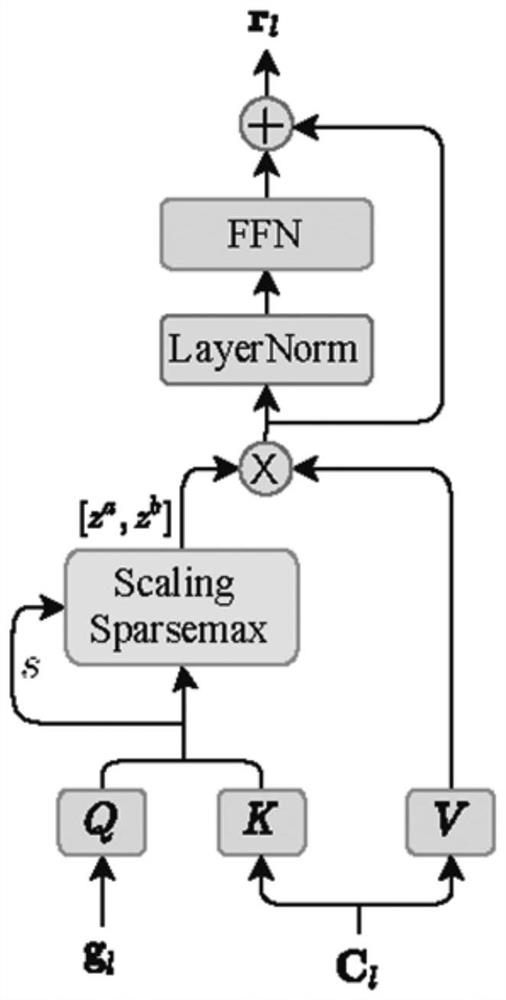
[0063] S1: Get synchronized bone conduction and air conduction voice data (x a ,x b ) to build a data set, where x a For pure air conduction voice recorded in an anechoic laboratory or in a relatively quiet environment, x b Bone conduction voice for simultaneous recording. Downsample all speech to 16kHz, 16bit quantization. The input data of the model is noisy air conduction and bone conduction speech, and the output is the text y corresponding to the speech. Because the bone conduction speech itself does not introduce environmental noise, we only add noise to the air conduction speech according to a certain range of signal-to-noise ratio, that is, in is the noisy air-conducted speech, n a for ambient noise. The final dataset is Then further set 84% of the dataset as a training set, 8% as a validation set, and the remaining 8% as a test set.
[0064] S2: Data Augmentation and Feature Extraction
[0065] S21: Change the speech rate of the speech signal to perform p...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More