

Kafka-based stacked data consumption method, terminal equipment and storage medium
A data and consumption data technology, applied in the field of data processing, can solve the problems of data accumulation, insufficient downstream consumption capacity, inability to monitor topic data accumulation and deal with them, and achieve the effect of improving data throughput capacity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
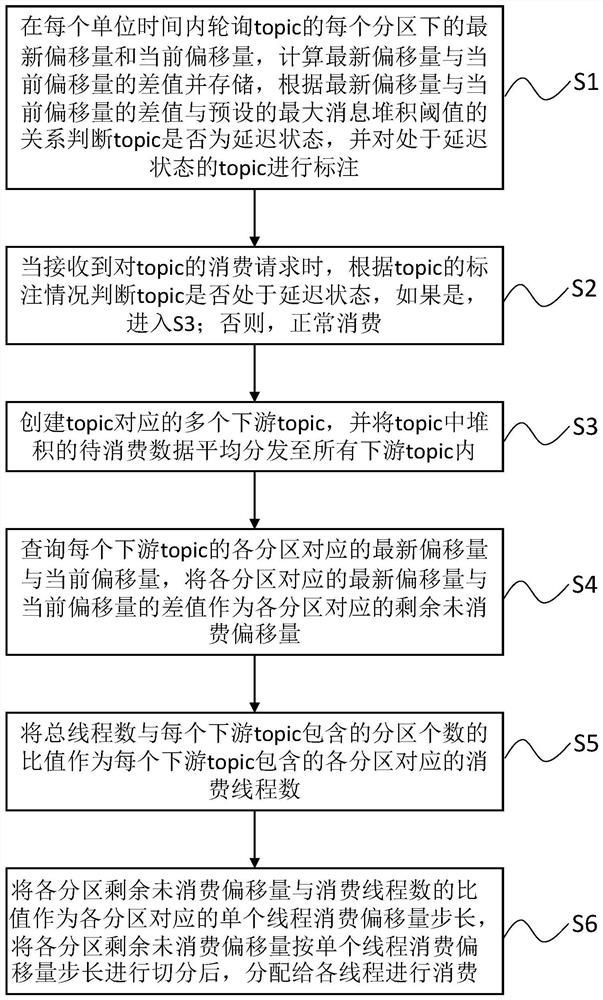
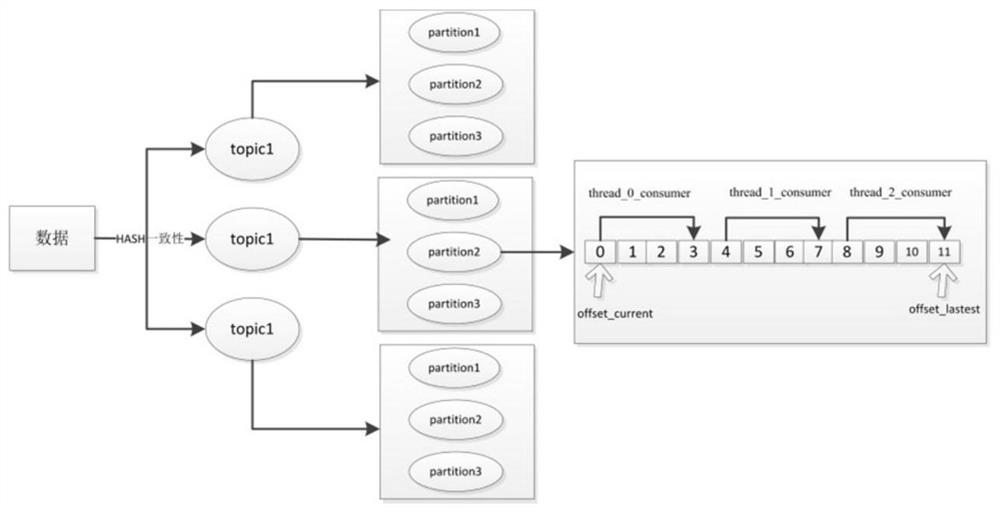
[0033] The embodiment of the present invention provides a Kafka-based accumulation data consumption method, such as figure 1 and figure 2 As shown, the method includes the following steps:
[0034] S1: Poll the latest offset (offset_latest) and the current offset (offset_current) under each partition (Partition) of the topic in each unit time, calculate the difference between the latest offset and the current offset, and Store, determine whether the topic is in a delayed state according to the relationship between the difference between the latest offset and the current offset and the preset maximum message accumulation threshold, and mark the topic in the delayed state.
[0035] In this example, a topic whose difference between the latest offset and the current offset is greater than the maximum message accumulation threshold is set as a topic in a delayed state. In order to improve the accuracy of judgment, it is further set that the mean or median value of the difference...
Embodiment 2
[0052] The present invention also provides a Kafka-based accumulation data consumption terminal device, including a memory, a processor, and a computer program stored in the memory and executable on the processor, when the processor executes the computer program The steps in the foregoing method embodiment of Embodiment 1 of the present invention are implemented.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More