Inplausible method based on few-sample relation prediction model
A technology for predicting models and relationships, applied in the field of knowledge graphs, can solve problems such as difficult decision-making process and insufficient interpretability, and achieve the effects of high practicability, good application prospects, and improved credibility
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

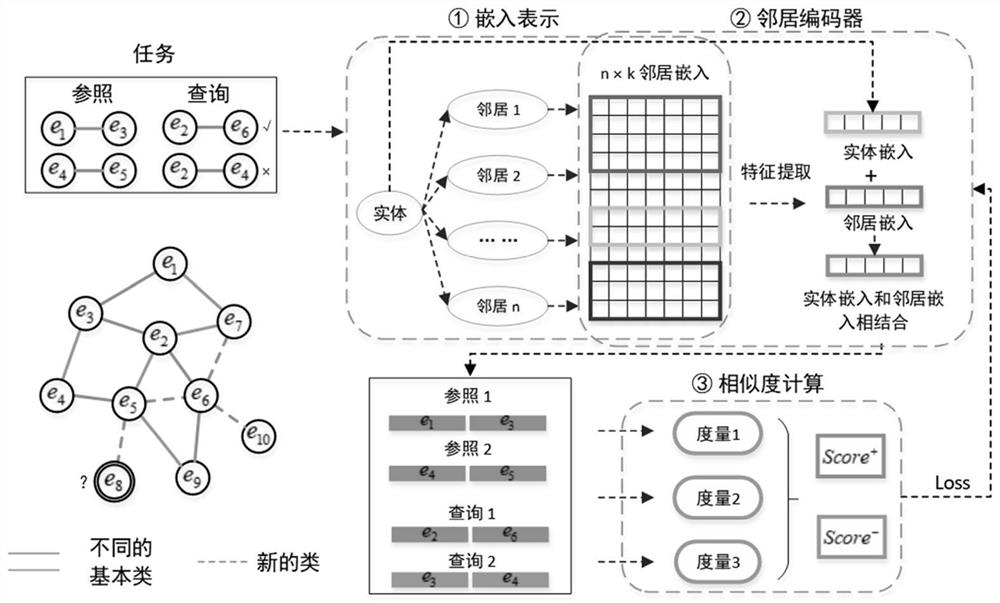
Examples
Embodiment Construction
[0028] The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, but not all of the embodiments. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
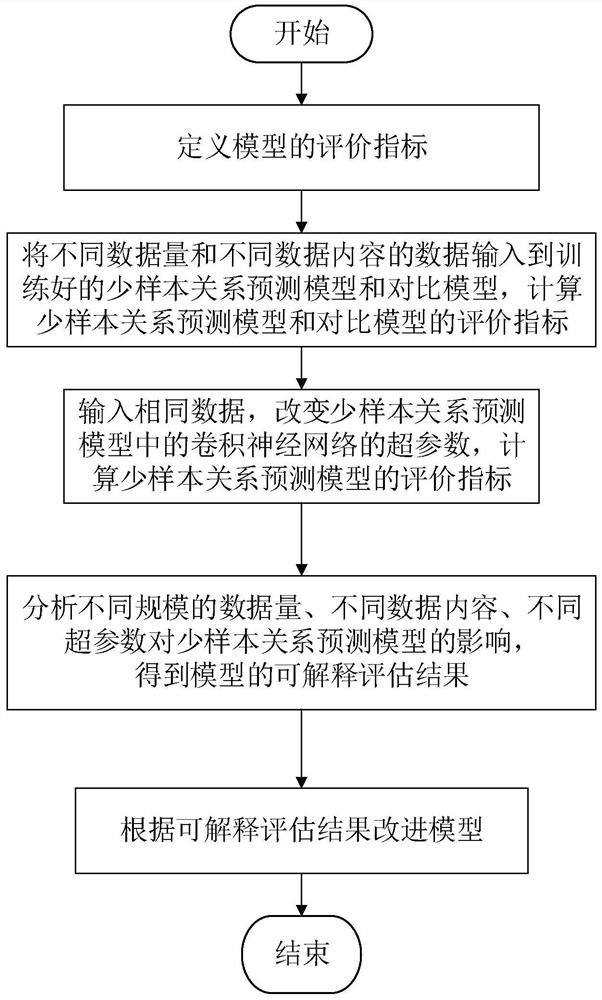
[0029] The present invention proposes an interpretable method based on a few-sample relation prediction model, such as figure 1 As shown, the method includes: evaluating the interpretability of a few-sample relationship prediction model to obtain an interpretable evaluation result; improving the model according to the interpretable evaluation result; acquiring a question from a user, and entering the question into the improved few-samp...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



