

Training method for embedded automatic sound identification system
A technology of automatic speech recognition and training method, applied in speech recognition, speech analysis, voice input/output, etc., can solve the problems of similar parts distinction, recognition rate decline, and key parts not getting enough attention.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

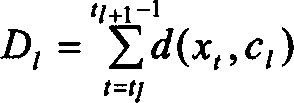
Examples
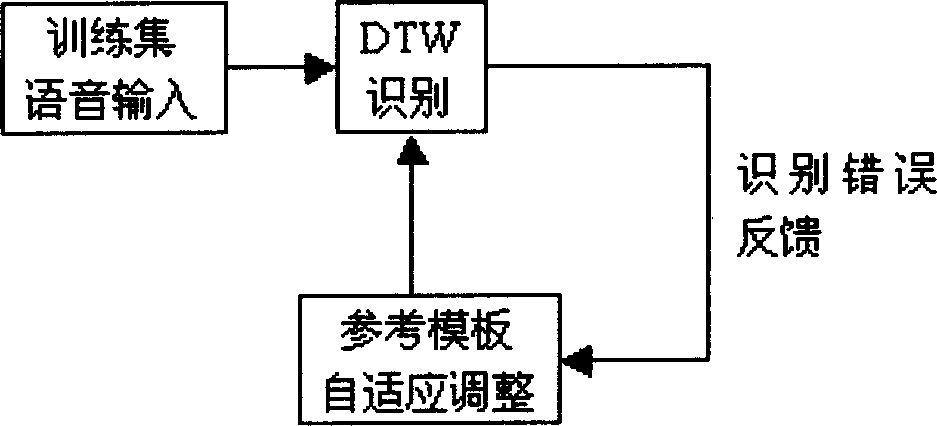
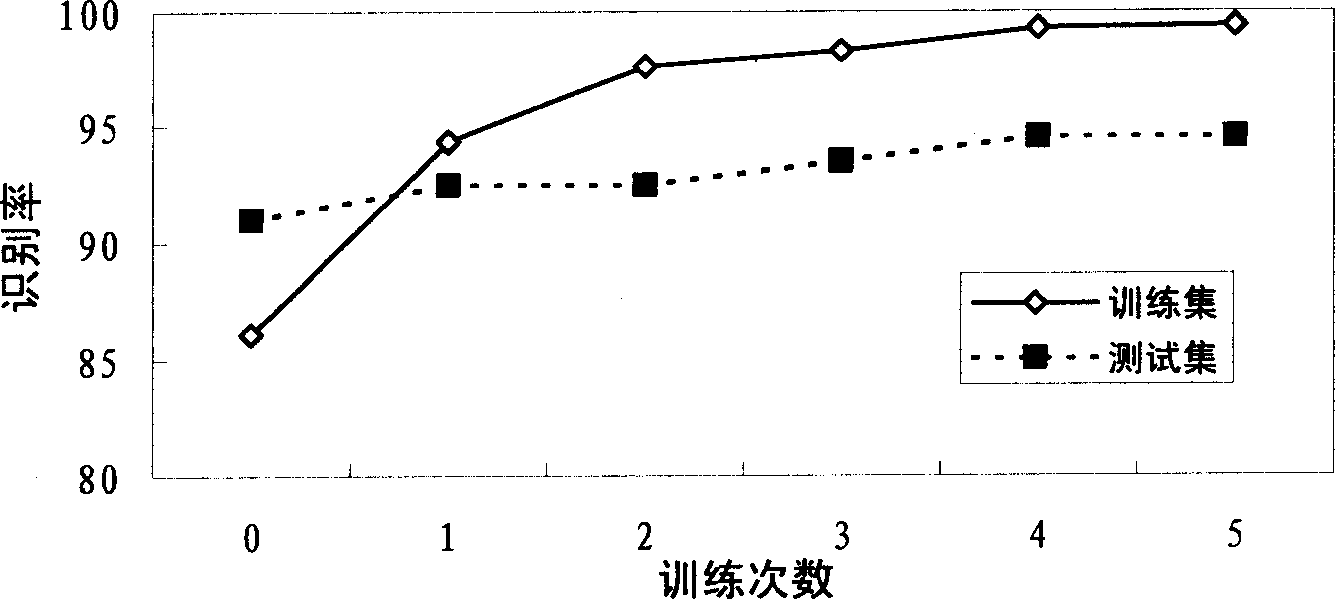
Embodiment
[0016] 1. Improved MSVQ template
[0017] Assuming that the frame length is T, the speech signal is usually represented by a feature vector sequence: X={x 1 , x 2 ,...,x T}. The segmentation method is based on a minimum distortion criterion in order to aggregate those frames that are most related into one segment. In addition, the total number of segments N s Related to the number of syllables contained in the word, each syllable in Chinese is usually composed of 3 to 4 phonemes (here, each syllable is divided into 3 segments, and each phoneme corresponds to a segment). First define the boundary as t l and t l+1 Intra-segment distortion D of segment l of -1 l for:
[0018] D l = Σ t = t l t l + 1 ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More