

Generating a transition system for use with model checking
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
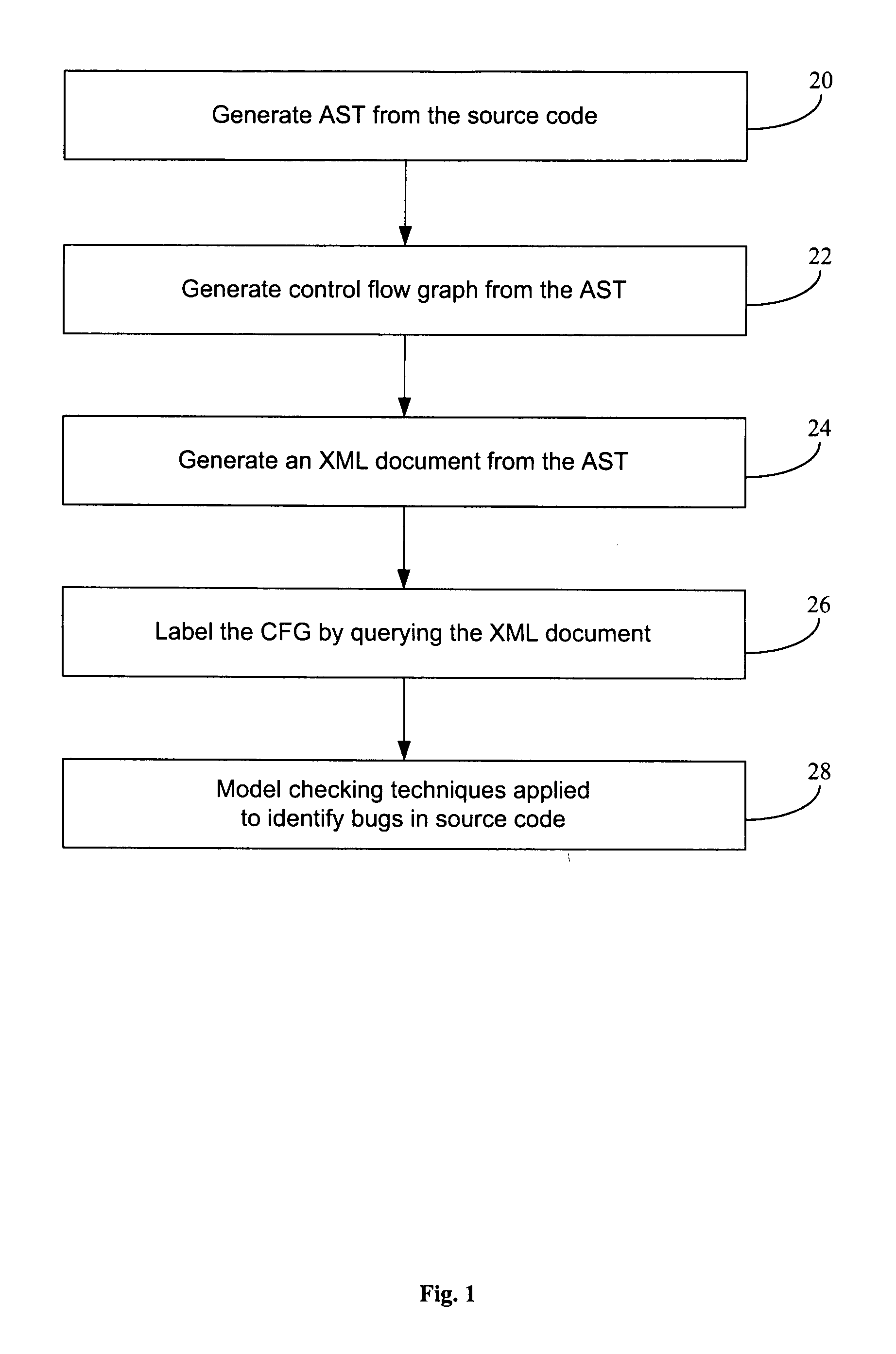
[0049]An example of using the invention to detect static software bugs in source code using model checking will now be described with reference to the flowchart of FIG. 1. We note that while this flow chart has been depicted as a flow of sequential steps, in fact some steps can be performed in parallel. For example, steps 22 and steps 24 of FIG. 1 can be performed in parallel.
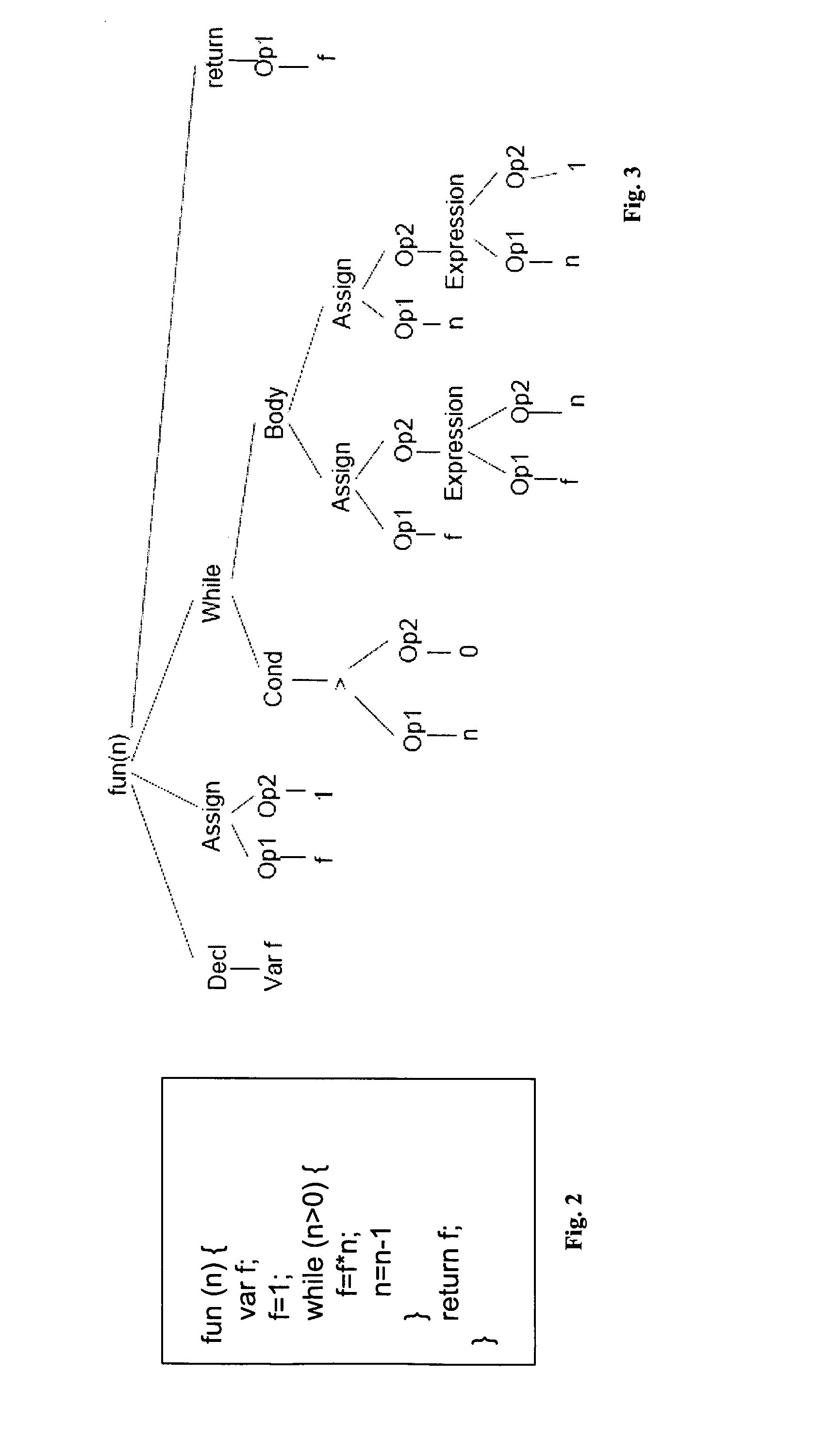
[0050]Take the source code of the sample program shown in FIG. 2. This sample program is automatically converted 20 to an abstract syntax tree (AST) shown in FIG. 3. An AST is a labelled tree, where the nodes are labelled by operators of a program, and where the leaf nodes represent its operands (i.e., variables or constants). The AST is an intermediate structure generated when parsing (i.e., reading in) a program and it is a natural precursor to the control flow graph (CFG). Every node in the AST has a unique identifier called a node ID (not shown).
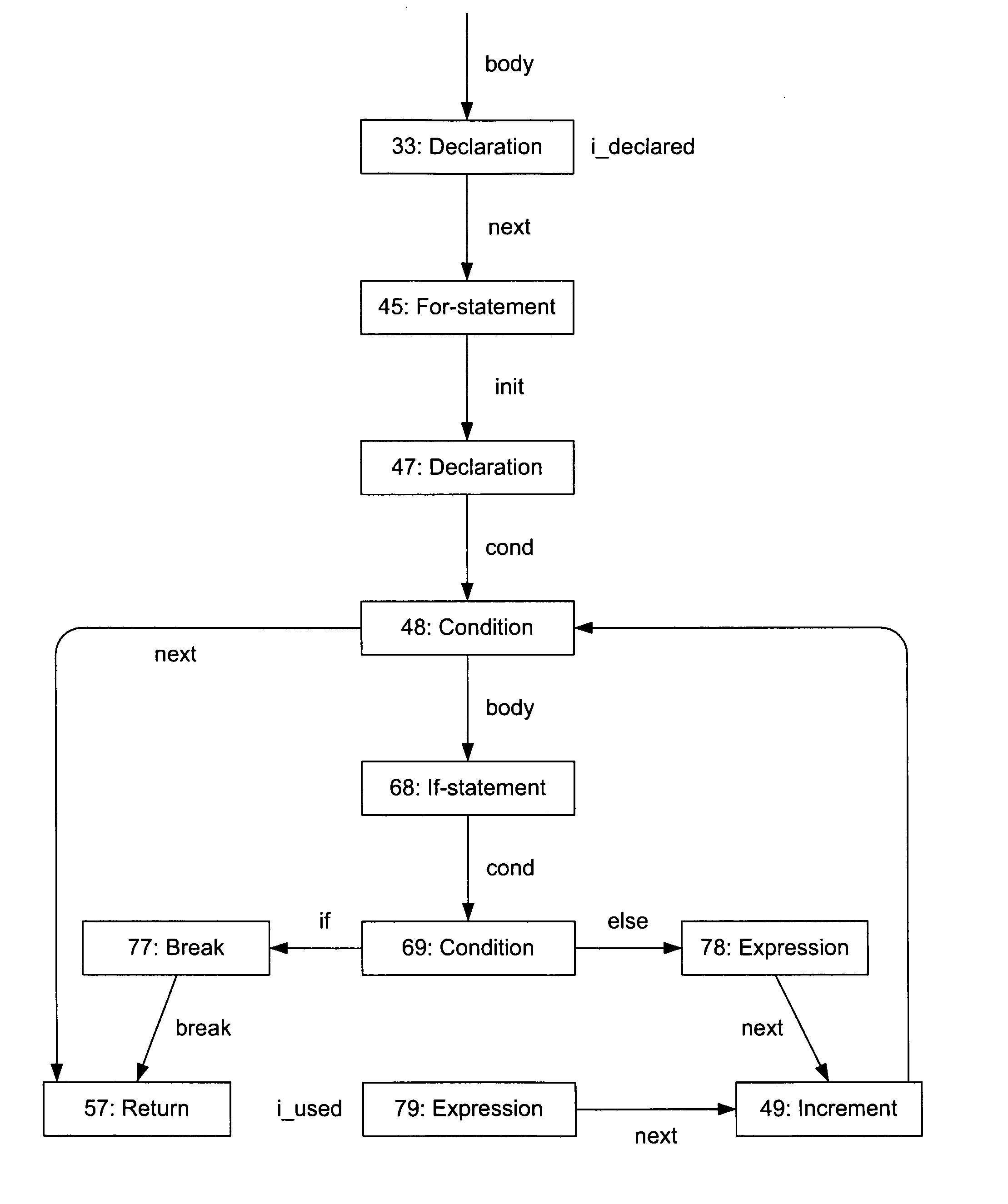
[0051]Next, we automatically generate 22 a CFG as shown in FIG...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More