Method for suppressing voice noise of mobile phone
A mobile phone and noise suppression technology, which is applied to the structure of the phone, voice analysis, and sidetone cancellation circuits, etc., can solve the problems of poor suppression effect, and achieve the effects of easy development and implementation, easy implementation, and simple structure
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
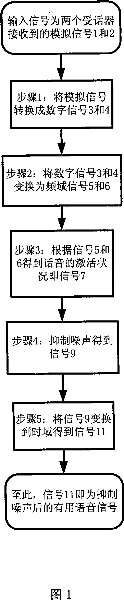
[0024] A kind of method that the present invention proposes is used for mobile phone suppressing speech noise, in conjunction with accompanying drawing and embodiment describe in detail as follows:
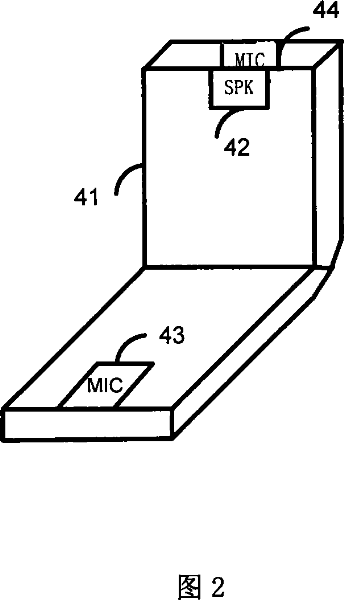
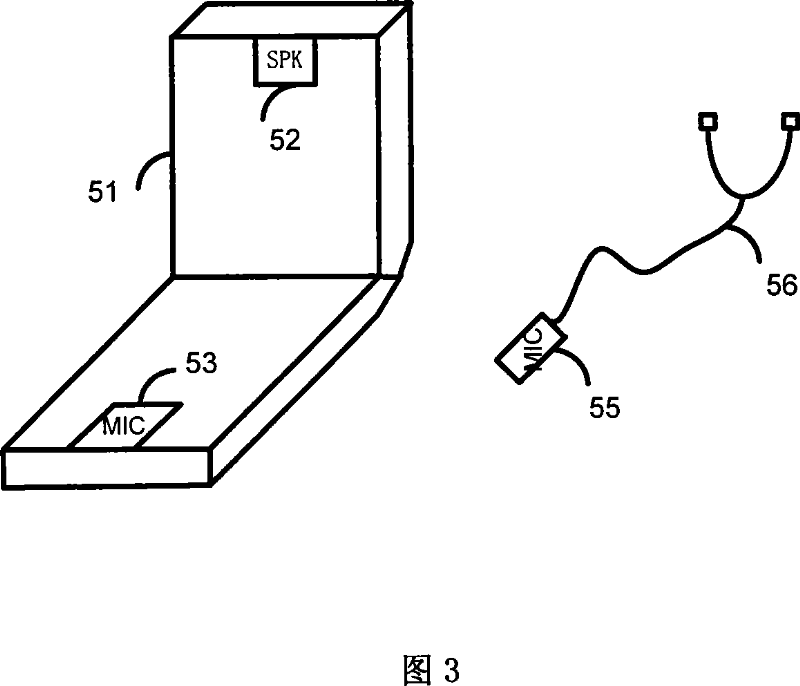
[0025] The method of the present invention needs to set a receiver, and the distance between the receiver and the receiver of the mobile phone that adopts the method makes the energy of the voice obtained by the receiver of the mobile phone greater than the energy of the voice that the receiver obtains, and the two receivers obtain The noise energy of is the same order of magnitude; The overall process flow of the method of the present invention is as shown in Figure 1, and this method comprises the following steps:
[0026] 1) respectively receiving the analog signals 1 and 2 output by the two receivers, and converting the analog signals into digital signals 3 and 4;
[0027] 2) converting the two output digital signals 3, 4 into frequency domain signals 5, 6;
[0028] 3) detect...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More