

Memory access bifurcation-based GPU (Graphics Processing Unit) kernel program recombination optimization method
A technology of core program and optimization method, applied in the directions of multi-program device, program control device, resource allocation, etc., can solve problems such as low execution efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
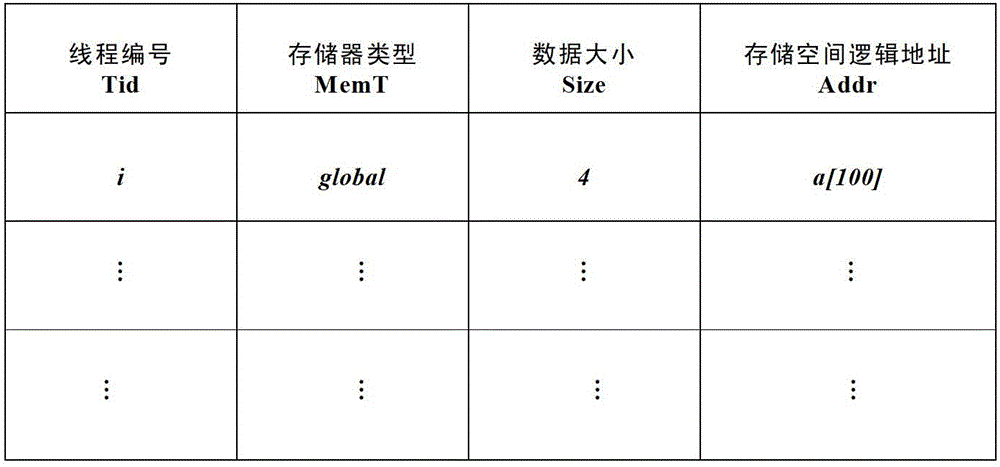
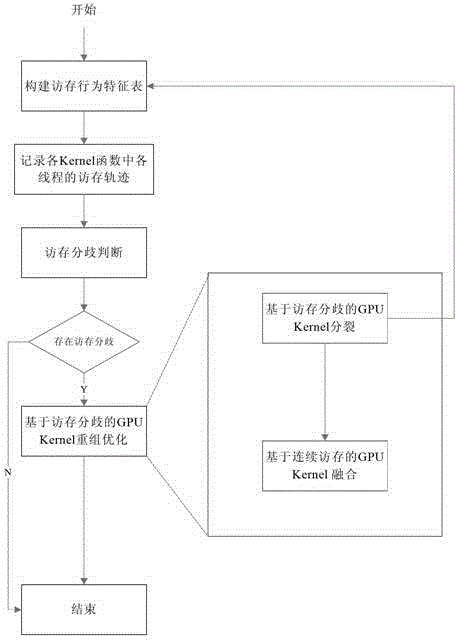
[0069] figure 1 In order to fetch the behavior feature table structure, the specific feature table establishment method is as follows:
[0070] Create a memory access behavior feature table for each Kernel function of the GPU program. The memory access behavior feature table contains four fields, namely: thread number Tid, memory type MemT accessed by the thread, data size accessed by the thread, and accessed Storage space logical address Addr. The thread number Tid represents the unique number of the thread in the Kernel function domain; the memory type MemT accessed by the thread represents the memory type accessed by the thread, and the memory type includes global memory Global, shared memory Shared Memory, texture memory Texture Memory and constant memory Constant Memory; The size of the data accessed by the thread Size indicates the number of bytes of storage space occupied by the data accessed by the thread; the logical address Addr of the storage space accessed by the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More