

A Real-time Speech-Driven Facial Animation Method
A technology for driving face and animation, applied in the fields of image processing, voice visualization, voice processing, and face animation, it can solve problems such as inability to meet real-time performance and face animation dependence, and achieve the effect of accurate relationship and accurate conversion.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
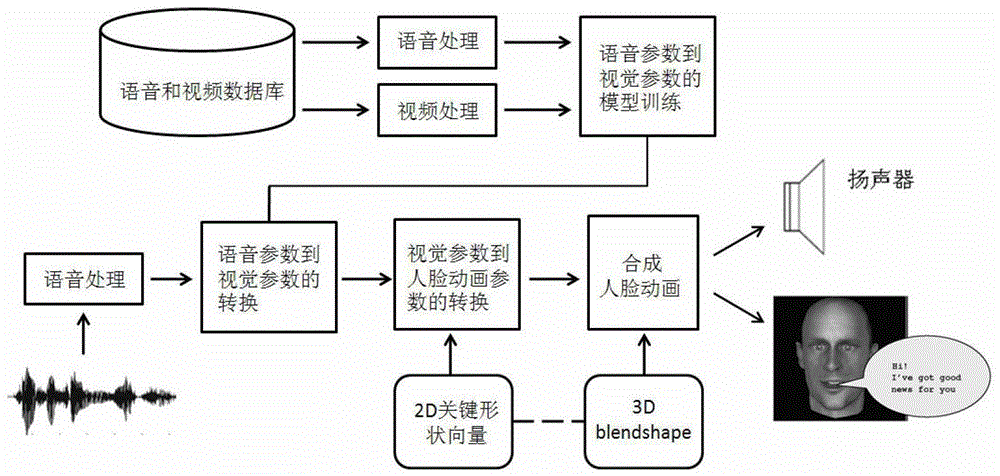
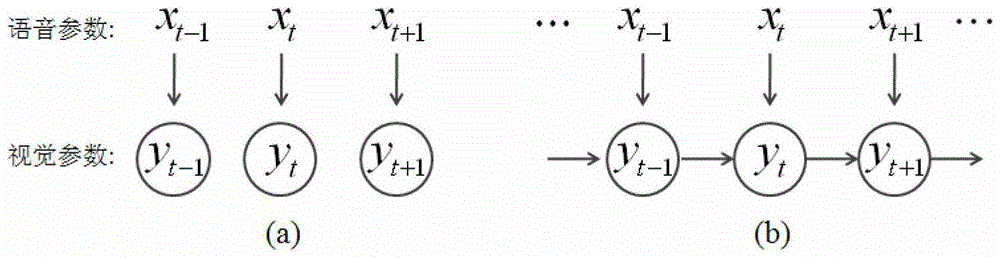
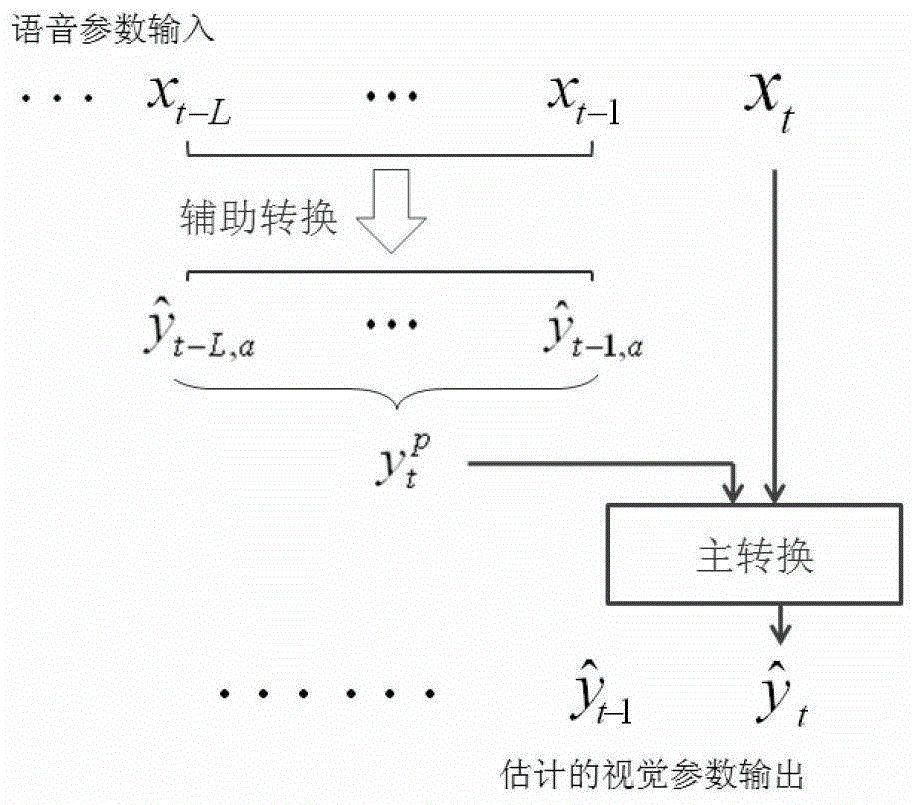
[0034] The invention is a method capable of synthesizing real-time voice-driven facial animation. The main steps are: obtaining voice parameters and their corresponding visual parameters, constructing a training data set; converting voice parameters into visual parameters for modeling and model training; constructing a set of blendshape corresponding to the face model; visual parameters to face animation parameters conversion, such as figure 1 shown.
[0035] 1. Obtain speech parameters and visual parameters, and construct a training data set
[0036] Have a performer read out a set of sentences, chosen to have good phoneme coverage. When reading aloud, the head posture remains unchanged, and the recording and video recording is performed right in front of the performer's face. After the recording and video recording is completed, the sound ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More