

Data similarity detection method based on sliding window
A data similarity and sliding window technology, applied in the field of data cleaning, can solve the problems of no uniform standard for window size setting and no consideration of impact differences, so as to save detection time and improve detection efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

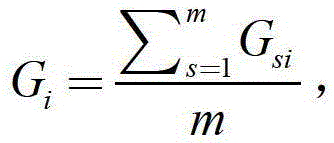
Examples
Embodiment Construction
[0037] The present invention will be described in detail below in conjunction with various embodiments shown in the drawings. However, these embodiments do not limit the present invention, and any structural, method, or functional changes made by those skilled in the art according to these embodiments are included in the protection scope of the present invention.
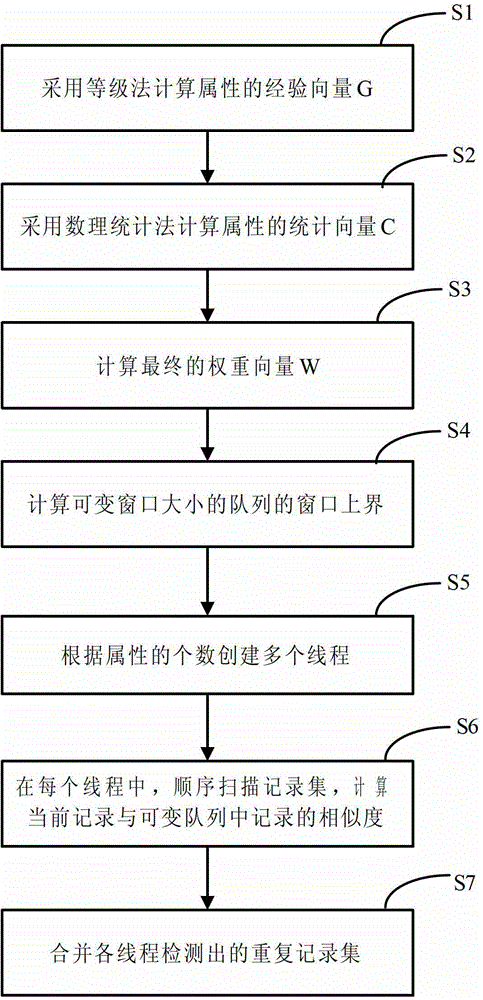
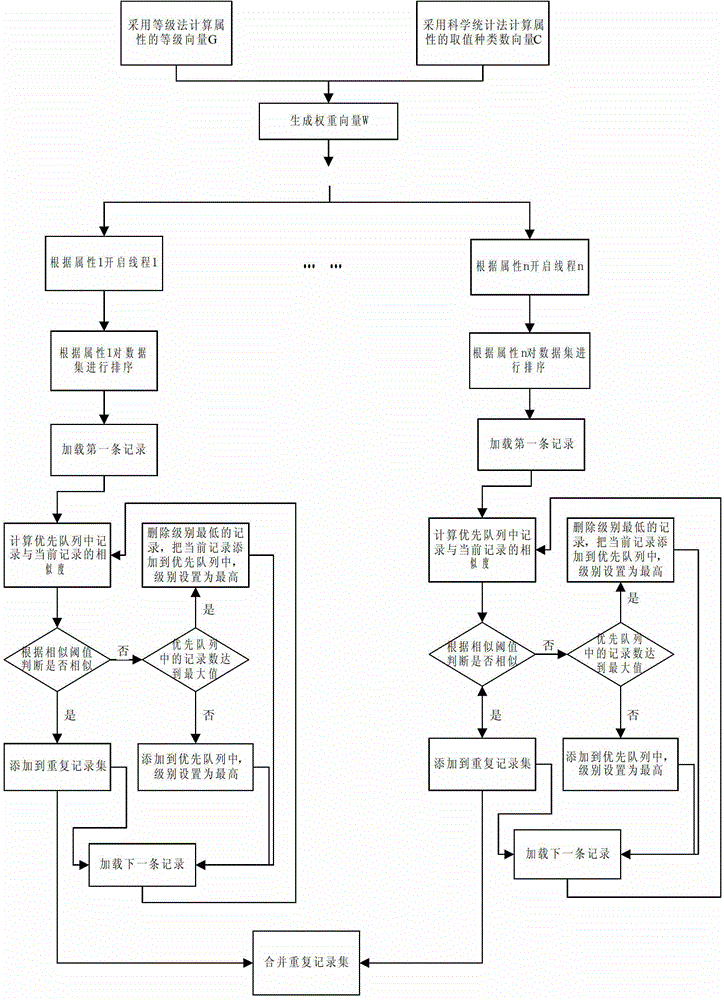
[0038] ginseng figure 1 Shown, a kind of data similarity detection method based on sliding window of the present invention, this method comprises:
[0039] S1. Using the hierarchical method to calculate the experience vector G of the attribute;
[0040] S2. Calculate the statistical vector C of the attribute by mathematical statistics;
[0041] S3. Computing the final weight vector W by integrating the experience vector G and the statistical vector C;
[0042] S4. Calculate the window upper bound of the queue with variable window size.
[0043] S5. Create multiple threads according to the number of attributes; ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More