

Orderly table data management method and system based on Hadoop distributed file system (HDFS)
A distributed file and management method technology, applied in the orderly management of table data based on the Hadoop distributed file system and the system field, can solve long delays, lack of optimization mechanisms for multi-channel data aggregation, and inability to meet manual queries, etc. problems, to achieve the effect of improving efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0042] Hereinafter, embodiments of the present invention will be described in detail with reference to the accompanying drawings.
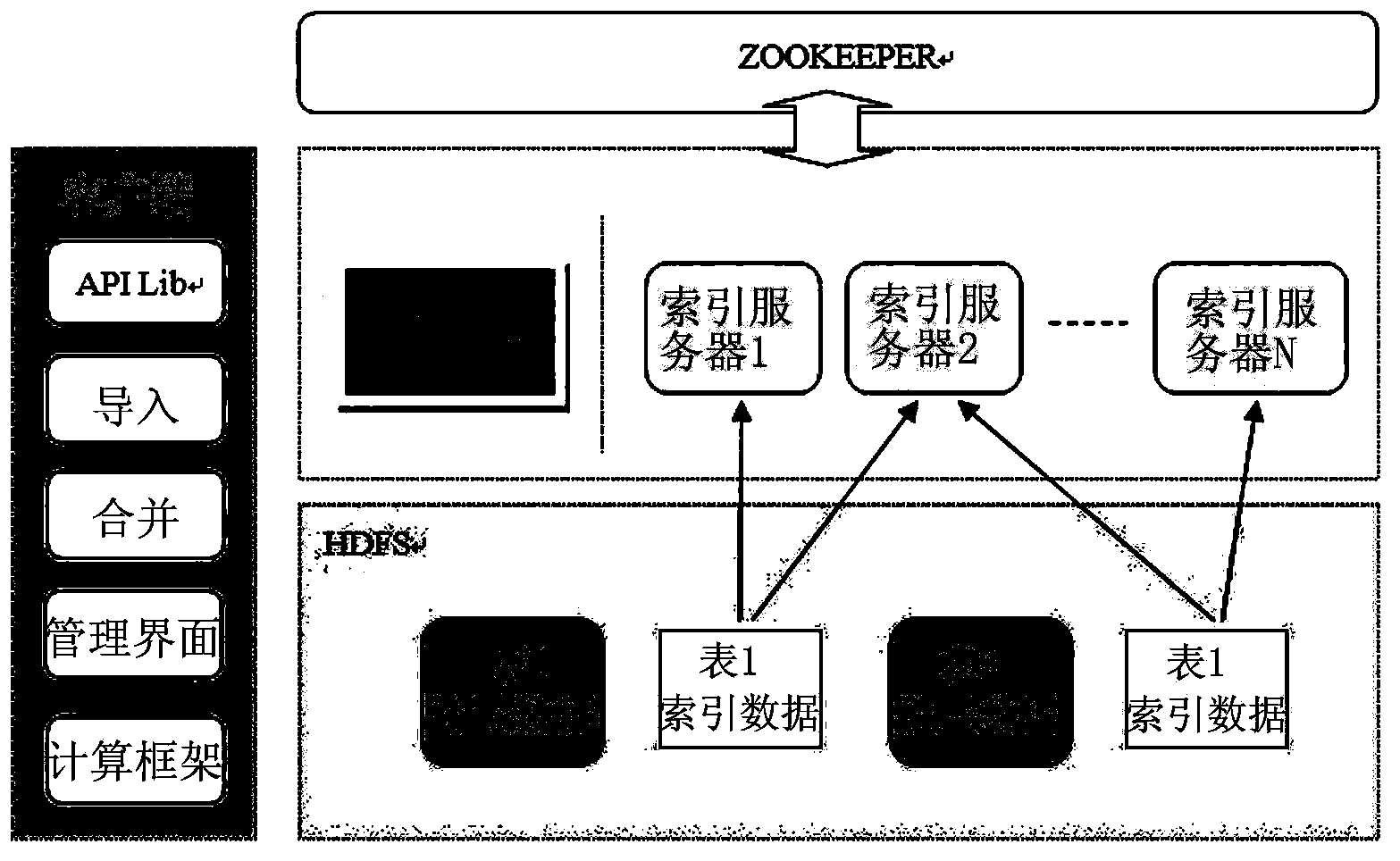
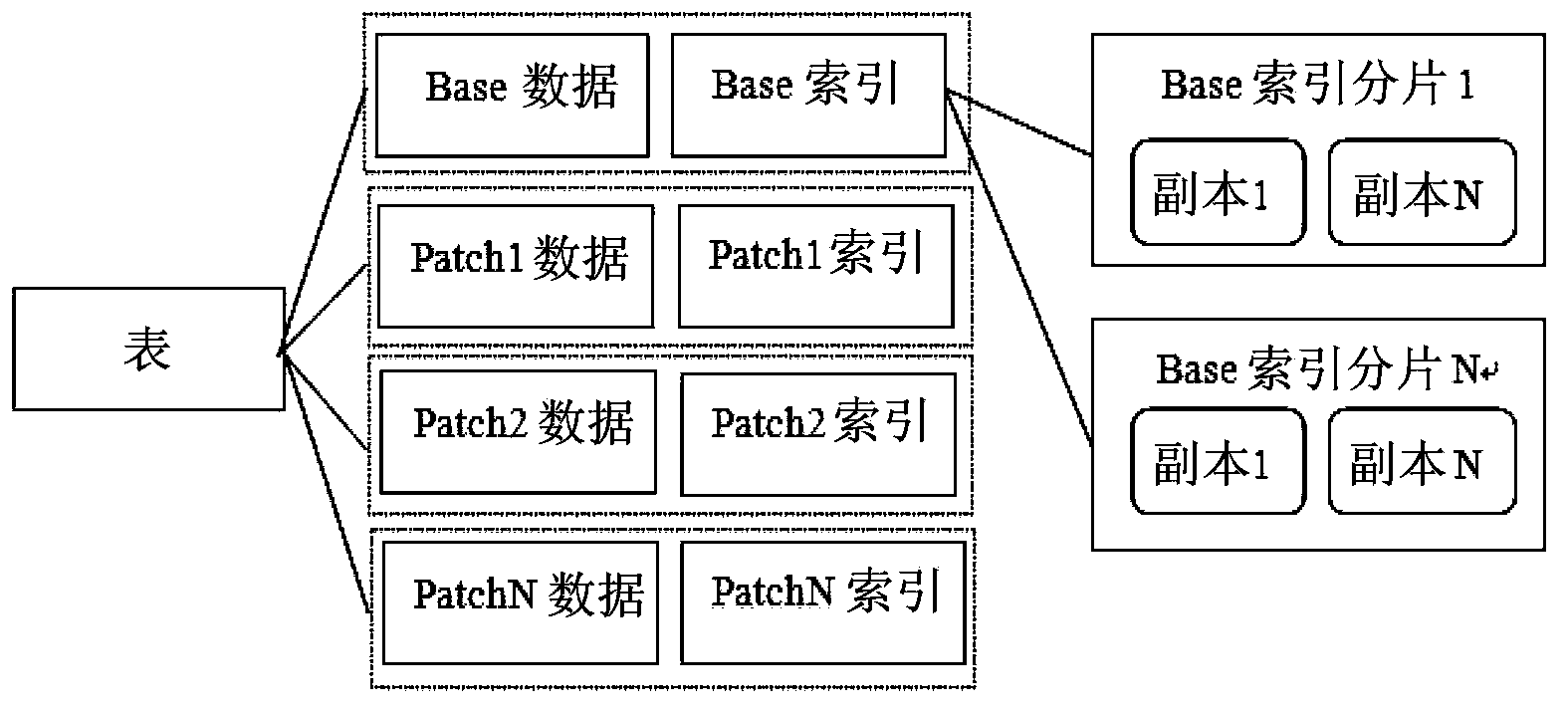
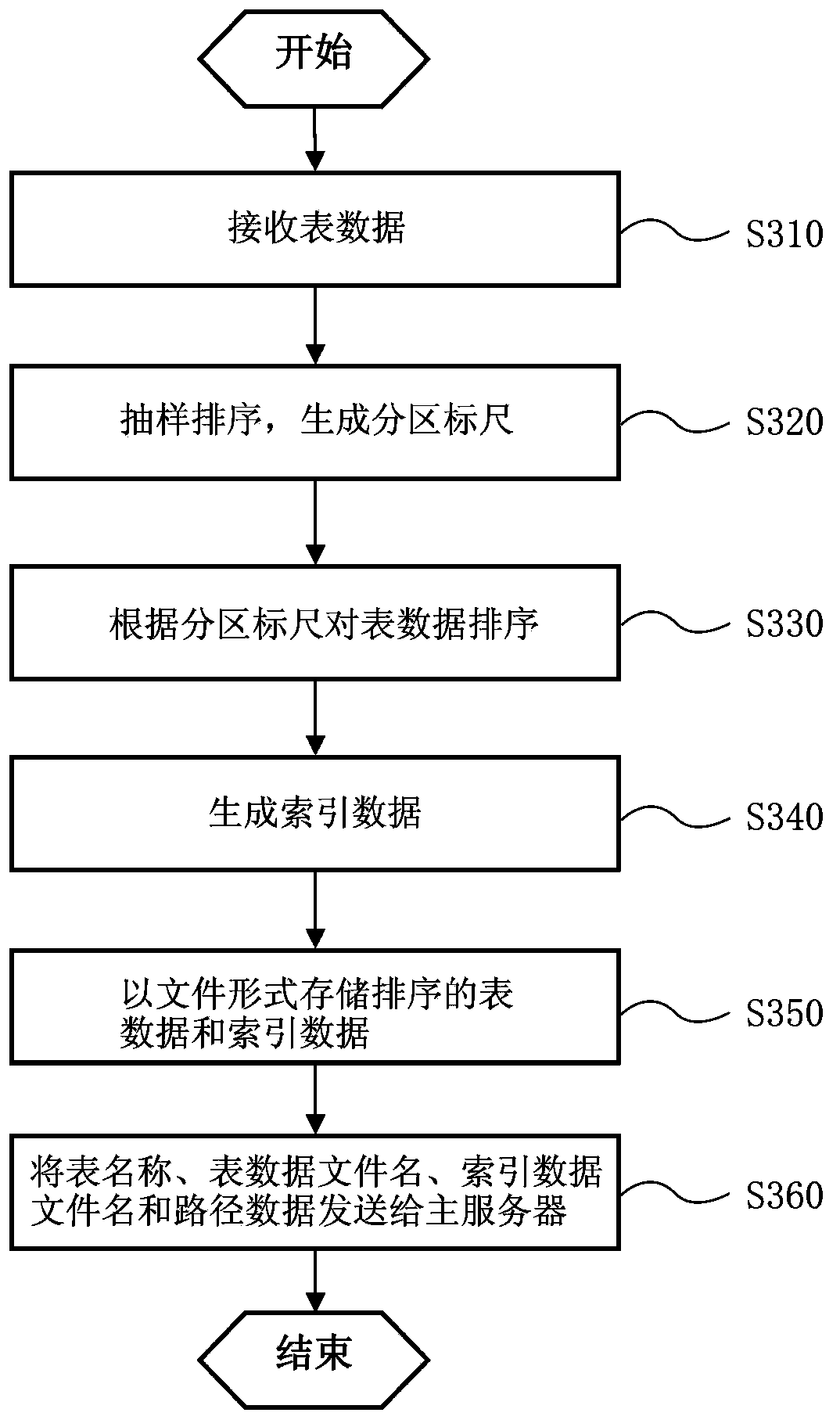
[0043] The technical scheme proposed by the invention mainly manages the table data imported in batches, and executes slice management on the table data belonging to the same table. That is, the batch data of the table imported each time is sorted based on Hadoop as the Base / Patch of the table, after that, index data is generated for the Base / Patch, and the sorted batch data and the generated Indexed data distributions are stored as separate files. In this way, a logically globally ordered table management system can be constructed. In addition, in the system of the present invention, the operation on any table record in the table (such as inserting a record, modifying a field in a record, deleting a record, etc.) A record of operations that manipulate data. Therefore, the batch data imported each time actually includes multiple operation recor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More