

Distributed file system and data access method thereof
A technology of distributed file and file access, applied in the field of distributed file system and its data access, can solve the problems of burden, heavy NameNode, taking a long time, etc., to achieve the effect of reducing delay, reducing pressure, and speeding up
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

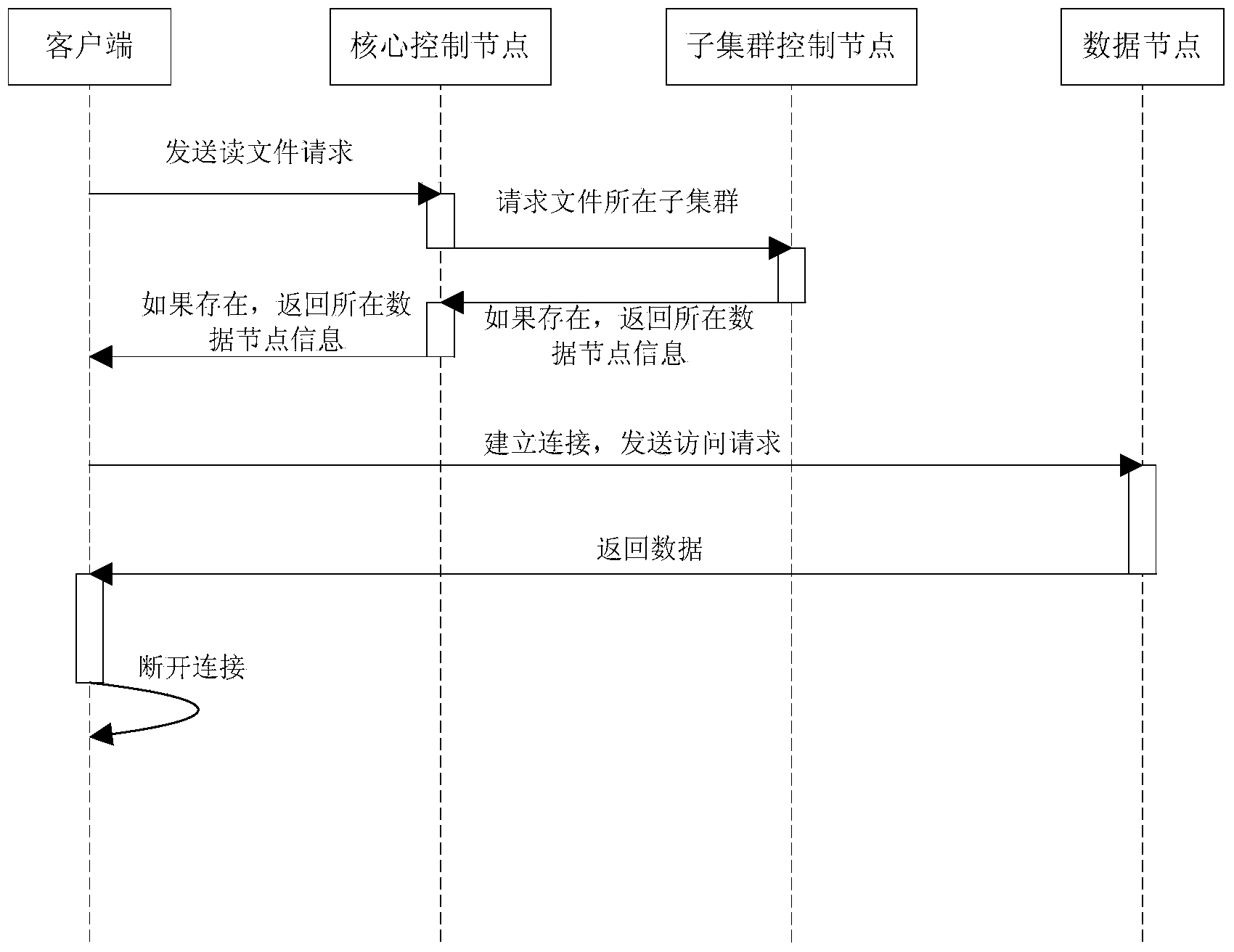
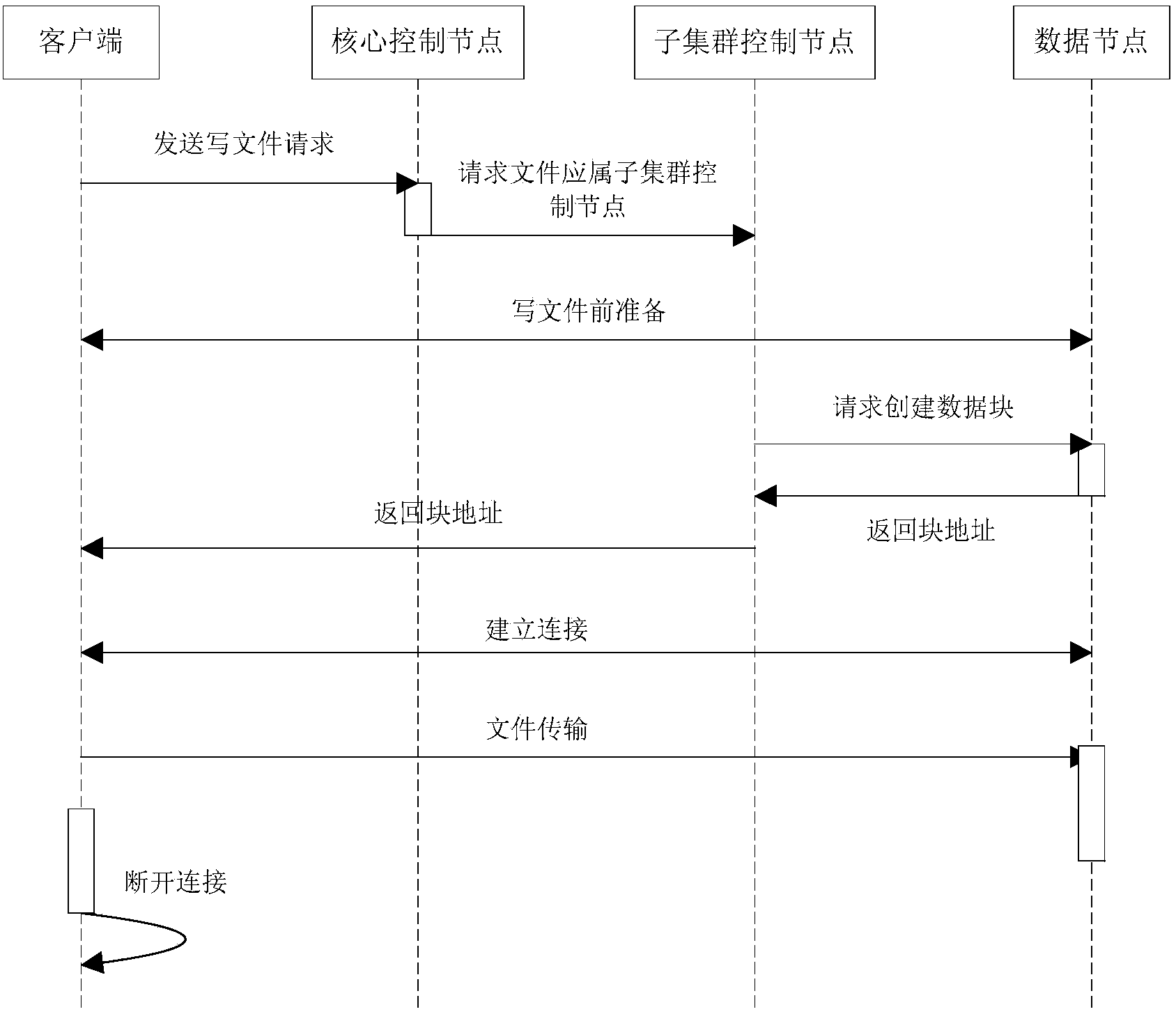
Examples
Embodiment Construction
[0041] In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings.
[0042] The present invention optimizes the above-mentioned problems existing in HDFS, enhances the stability of the distributed file system, and greatly improves the performance of the system. In addition, the whole system has better scalability, which is more conducive to the distributed file system. Deployment and application of the file system.
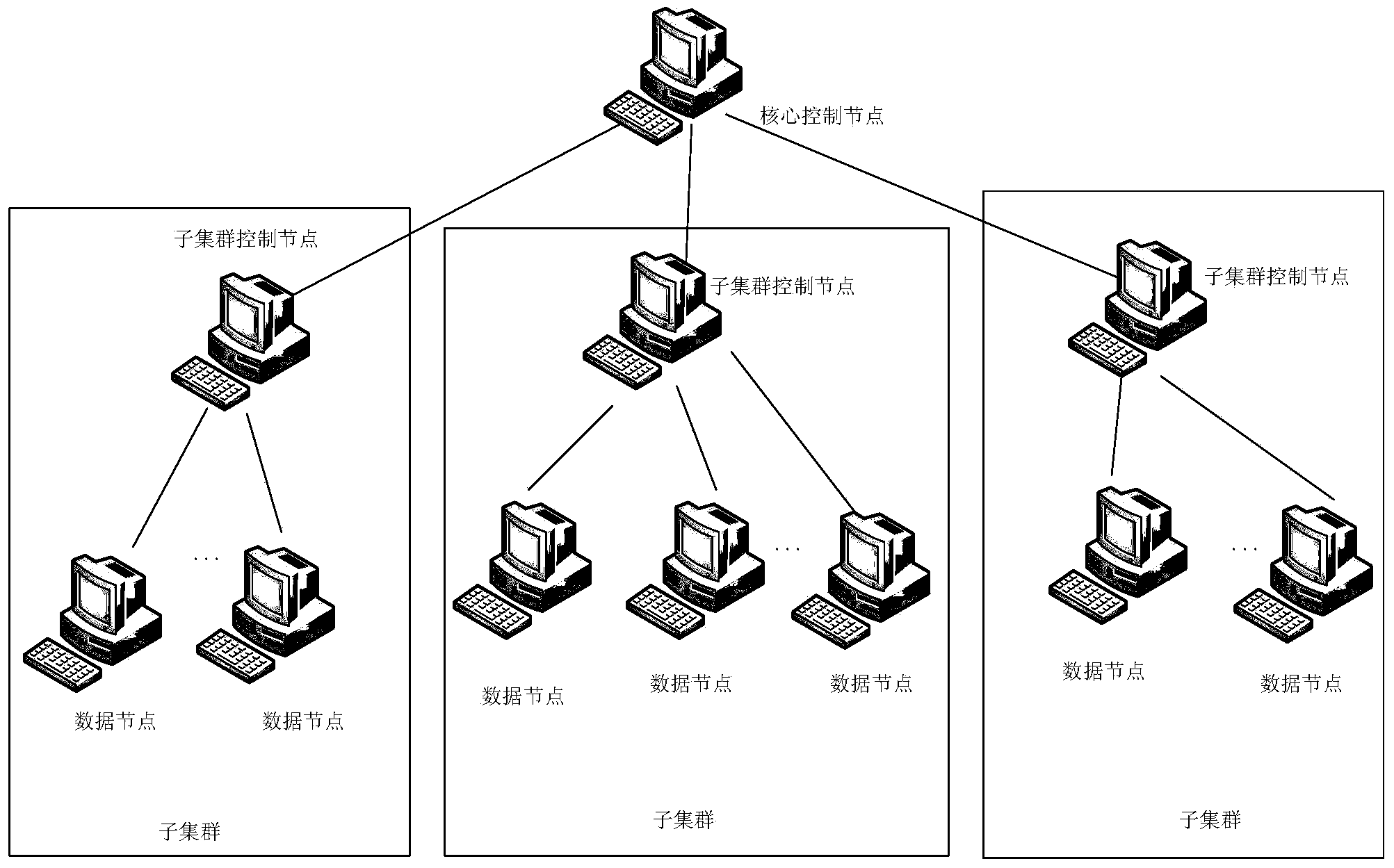
[0043] figure 1 It is a structural diagram of the distributed file system of the present invention.
[0044] Such as figure 1 As shown, the system includes a core control node and multiple sub-clusters, each sub-cluster includes a sub-cluster control node and multiple data nodes, where:
[0045] The core control node is configured to receive a file access request including a file name from the client, parse the file...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More