

Small file storage method based on Hadoop distributed file system
A distributed file and small file technology, applied in the computer field, can solve the problem of low memory usage and storage access efficiency, and achieve the effect of satisfying low-latency access, reducing storage burden, and high efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

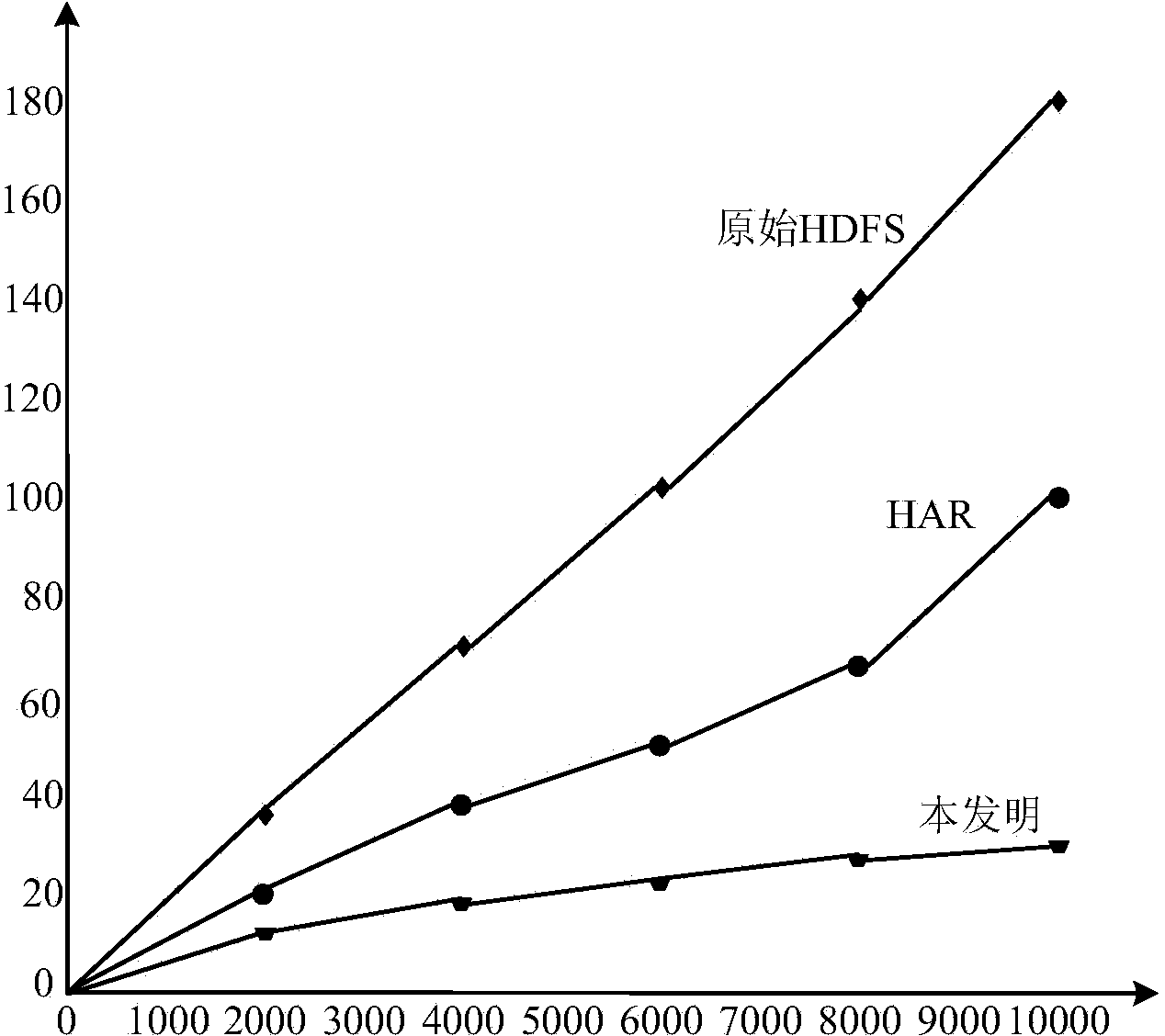
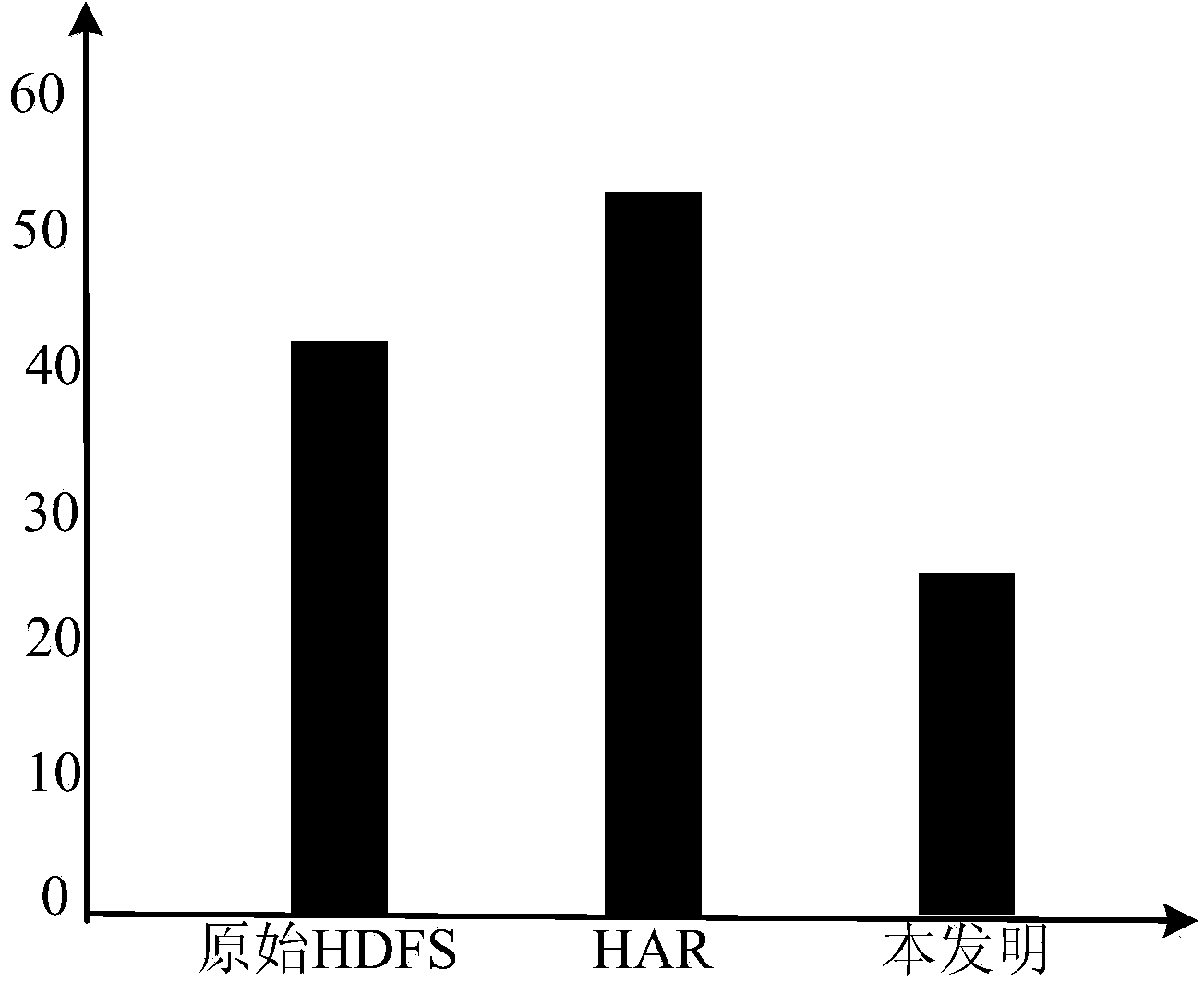
Examples
Embodiment Construction
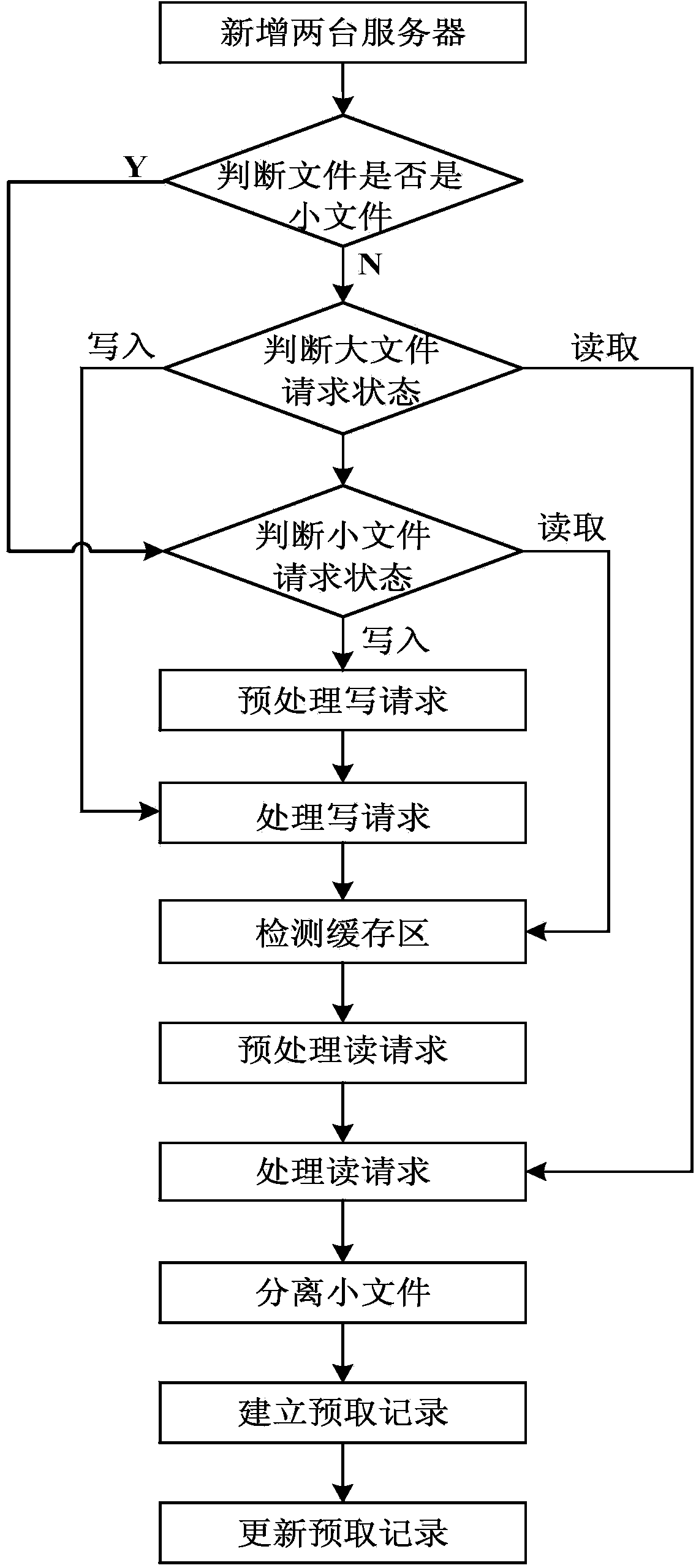
[0042] The present invention will be further described below in conjunction with the accompanying drawings.
[0043] refer to figure 1 , the specific implementation steps of the present invention are as follows:
[0044] Step 1, add two new services.
[0045] In addition to the Hadoop distributed file system HDFS, add a web server Websever for monitoring file read and write requests, and add a small file processing server for processing small files: the system architecture of the present invention consists of web server Websever, The small file processing server and the original HDFS system are composed of three parts. The small file processing server mainly performs operations such as file merging, file mapping, and file prefetching on small files.
[0046] Step 2, judging whether the file is a small file.
[0047] The web server Websever judges whether the monitored request file is a file smaller than 16M, if it is smaller than 16M, it is regarded as a small file, and ste...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More