

Density-based partitioning and clustering method for K center points in data mining
A clustering method and data mining technology, applied in the field of clustering, can solve problems that affect the clustering results, the local optimal solution of the results, and the sensitivity of the initial clustering center, so as to save computing time, stabilize the clustering results, and improve computing efficiency fast effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0021] The present invention will be further described below in conjunction with specific drawings and embodiments.
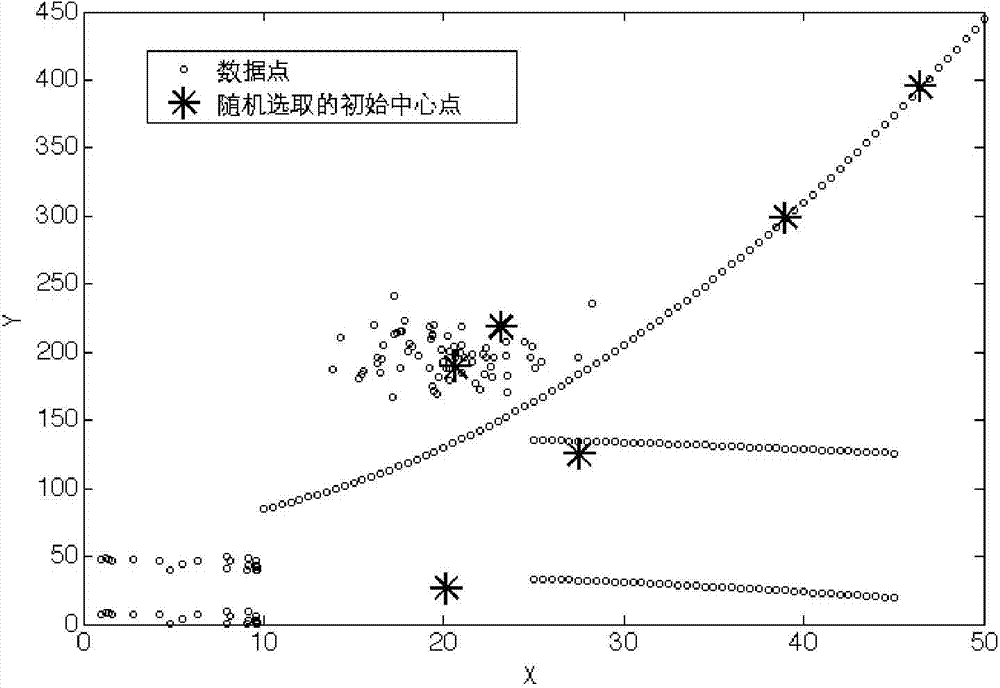
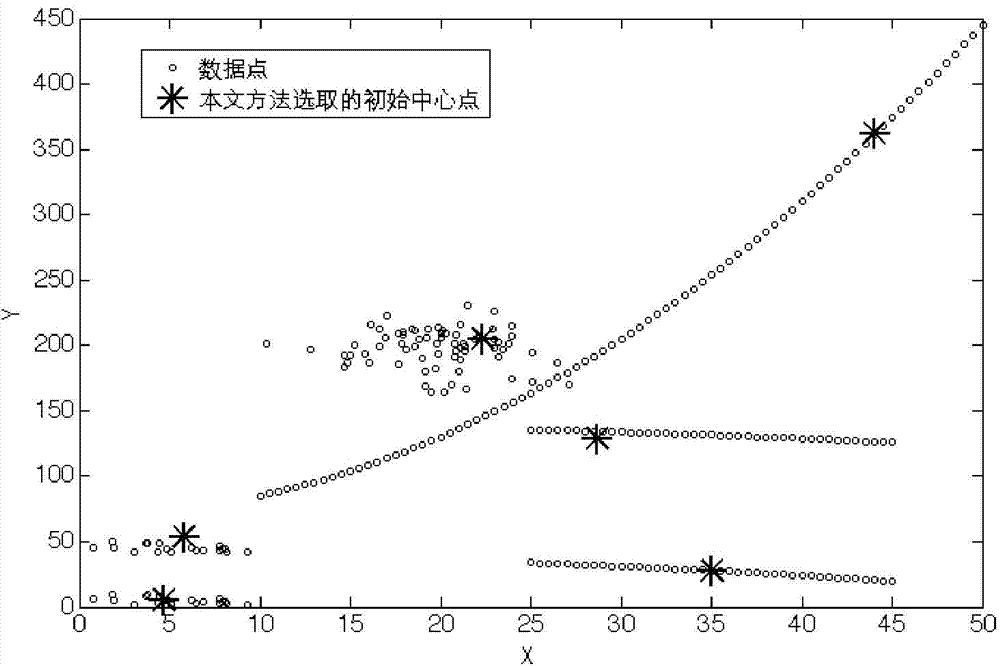
[0022] Such as Figure 5 Shown: in order to improve the accuracy rate of classification, stability is high, improves fast convergence, clustering method of the present invention comprises the following steps:
[0023] Step 1. Given the required data set, and determine the number K of clusters;
[0024] In the embodiment of the present invention, for the data set X={x i |i=1,2,…,n}, the data object has m-dimensional features, C j (j=1,2,...,K) represents K categories of clustering, c j (j=1,2,...,K) represents the initial cluster center.
[0025] Step 2, calculate the density of all data objects in the data set, and calculate the average density of the data set according to the density of the obtained data objects;
[0026] In the embodiment of the present invention, the density of data objects in the data set is
[0027] density ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More