

Mass small file processing method based on HDFS
A technology of massive small files and processing methods, applied in the field of distributed data optimization storage, can solve the problems of inability to process image upload requests, inability to delete and modify files, and cost, achieve efficient file real-time update processing, and improve writing. And the effect of reading efficiency and overall performance improvement
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0027] The technical scheme of the present invention is further elaborated below in conjunction with accompanying drawing and embodiment:
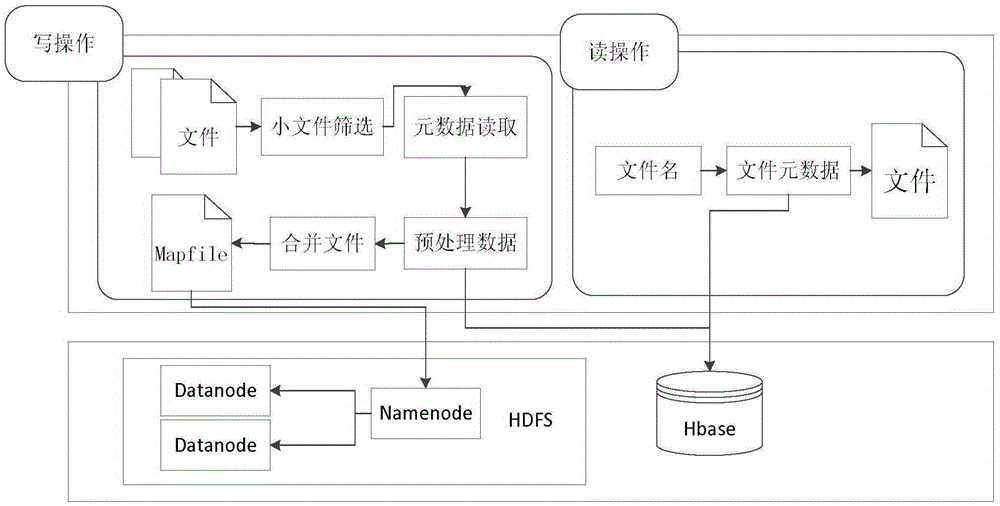
[0028] A method for processing a large amount of small files based on HDFS in the present invention is as follows: figure 1 As shown, the specific content will not be repeated here.
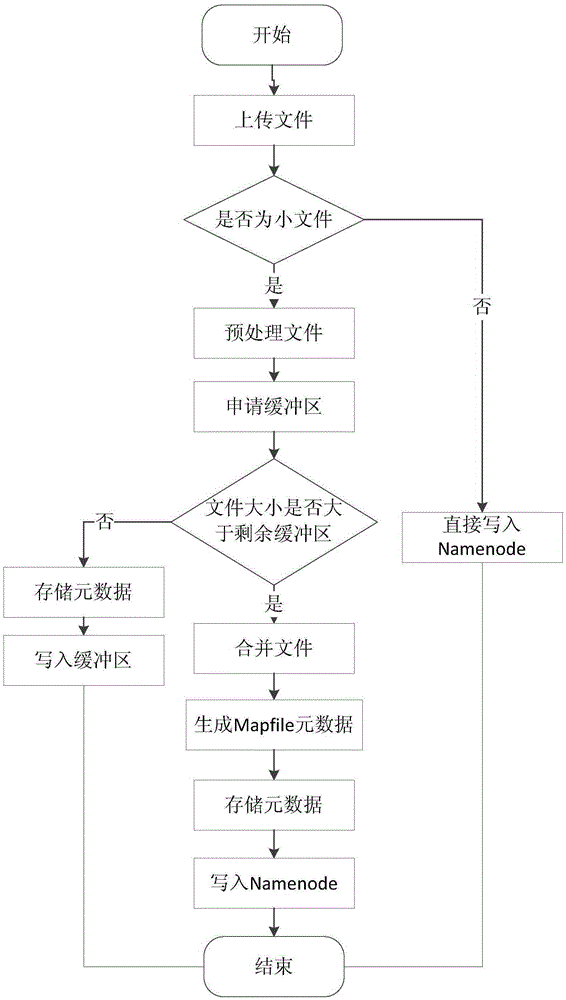
[0029] Adopt the file upload of a kind of massive small file processing method based on HDFS of the present invention, as figure 2 As shown, its working process is as follows:
[0030] 1) Filter the uploaded files received by the server according to the set first threshold. Set the first threshold to 1M. If the size of the uploaded file is greater than 1M, it is a large file. The uploaded file directly uses the HDFS file storage interface, that is Allocate the file storage block (BlockID) through Namenode and store it in HDFS; otherwise, if it is a small file, go to 2);
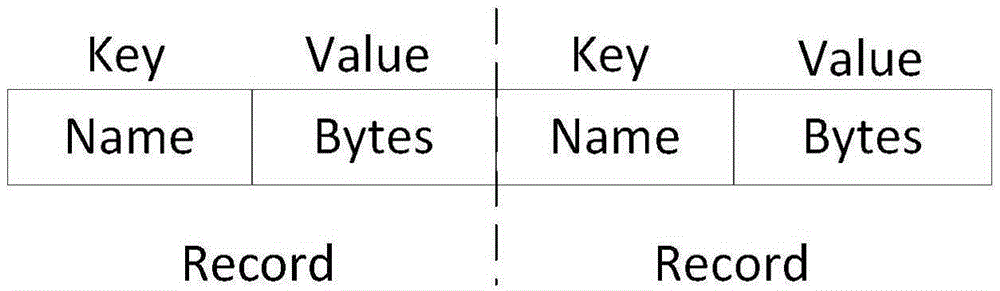
[0031] 2) After obtaining the file name of the small file, the length of the file, a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More