

Method for quickly looking for feature character strings in text sequential data
A technology of characteristic character strings and text sequences, which is applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., and can solve problems such as slow speed and poor adaptability of data sequences
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment
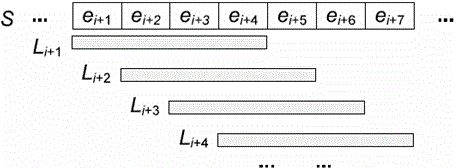
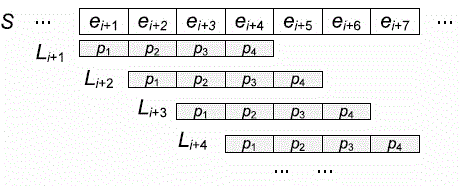
[0022] Define the suffix array: Given a set of text sequences, S=e 1 ...e n and a set of mutually independent hash functions H={h 1 … h n}, let h i (S) is expressed as a sequence of hash results, h i (S)=h i (e 1 )… h i (e n ), where the suffix matrix of S is M s,m = , is h i (S) suffix array. There are many ways to form a suffix prime group, so the generated suffix matrix can be many.
[0023] Search in the suffix array: it is divided into two steps, first find potential similar segments from the suffix matrix, and then directly filter through the similarity.
[0024] Given a set of mutually independent hash functions and query sequences, generate a suffix matrix. Then decompose through binary search, and search for each row according to the number of rows in the suffix matrix. If a field appears a specified number of times in the binary search result set, the field is considered a candidate field.
[0025] The following program sequence shows the process of...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More