Method and device for enhancing reliability and availability of dual-computer clusters
A usability and clustering technology, applied in digital transmission systems, electrical components, error prevention, etc., can solve problems such as node failure, achieve the effect of enhancing stability and availability, and avoiding power failure of the rack
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0042] The present invention will be described in detail below in conjunction with specific embodiments.
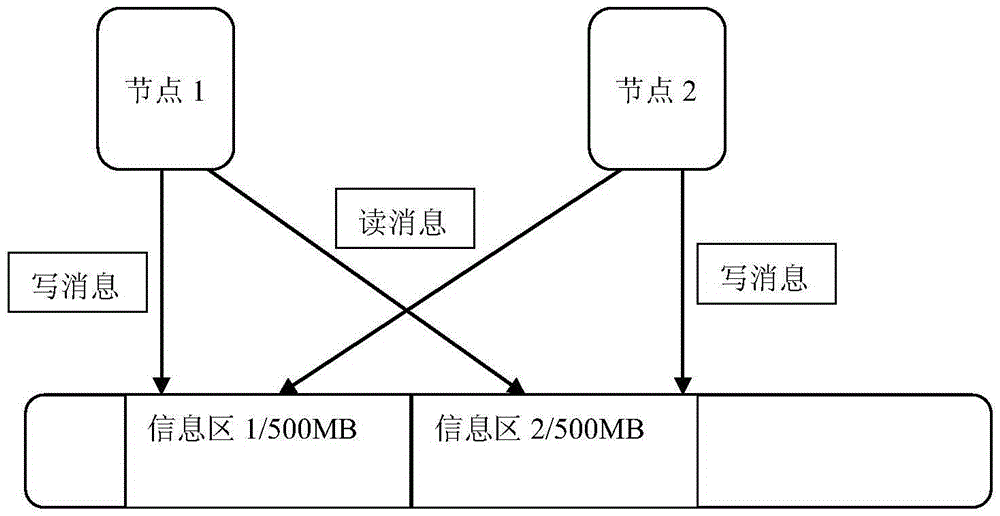
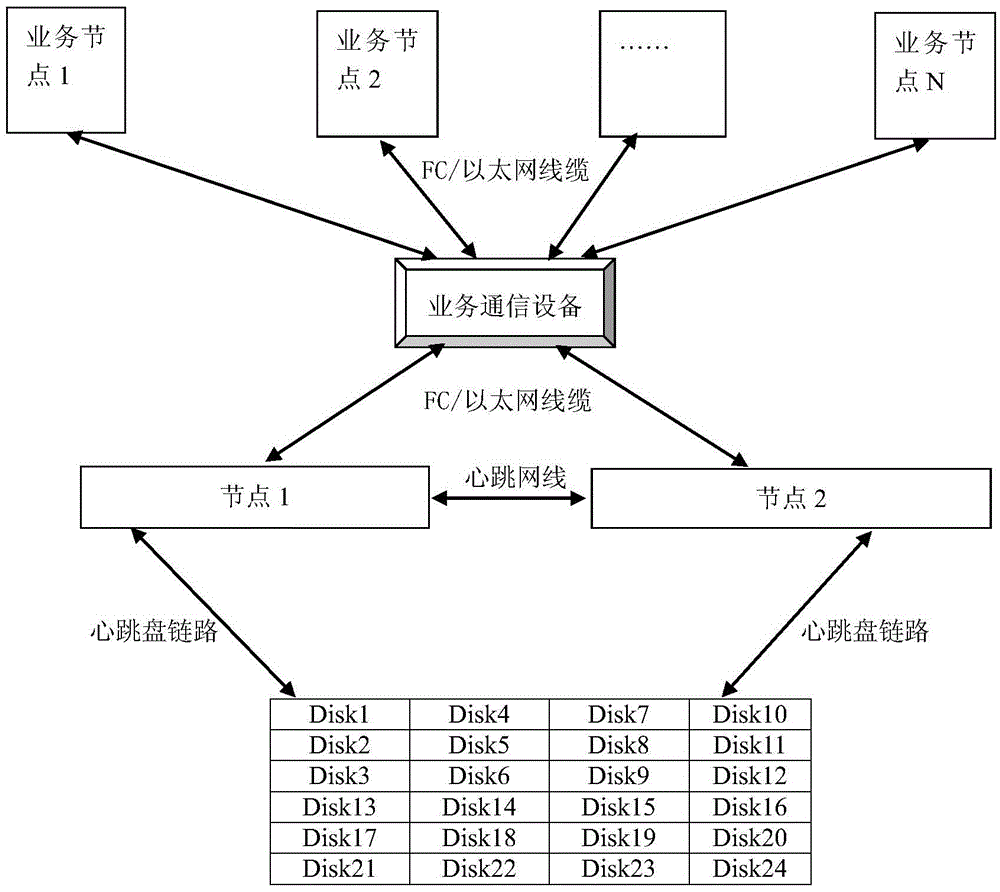
[0043] In this embodiment, the method of the present invention is described in detail by taking a two-machine cluster of shared disks composed of 24 disks as an example.
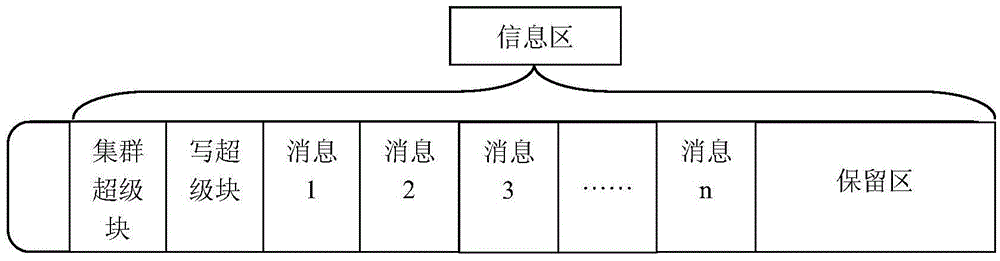
[0044] One: Take one of the two computers as the master control node, create a RAID storage pool for 24 disks on it, that is, a shared disk, and create raw device volumes and file system data sets on the pool, and the raw device volumes are passed through optical fiber or iSCSI protocol. (not limited to these two methods) external mapping, file system data sets provide external access through CIFS or NFS protocol (not limited to these two methods); when creating a RAID storage pool, reserve a part on the disk selected for heartbeat communication The area is used as the heartbeat disc to store the heartbeat information. In this embodiment, the 4MB position from the starting position of the disk is used a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



