

Cleaning robot optimal target path planning method based on model learning
A technology for cleaning robots and target paths, applied in the field of optimal target path planning for cleaning robots, to achieve the effects of improved model learning efficiency, improved speed and accuracy, and strong applicability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
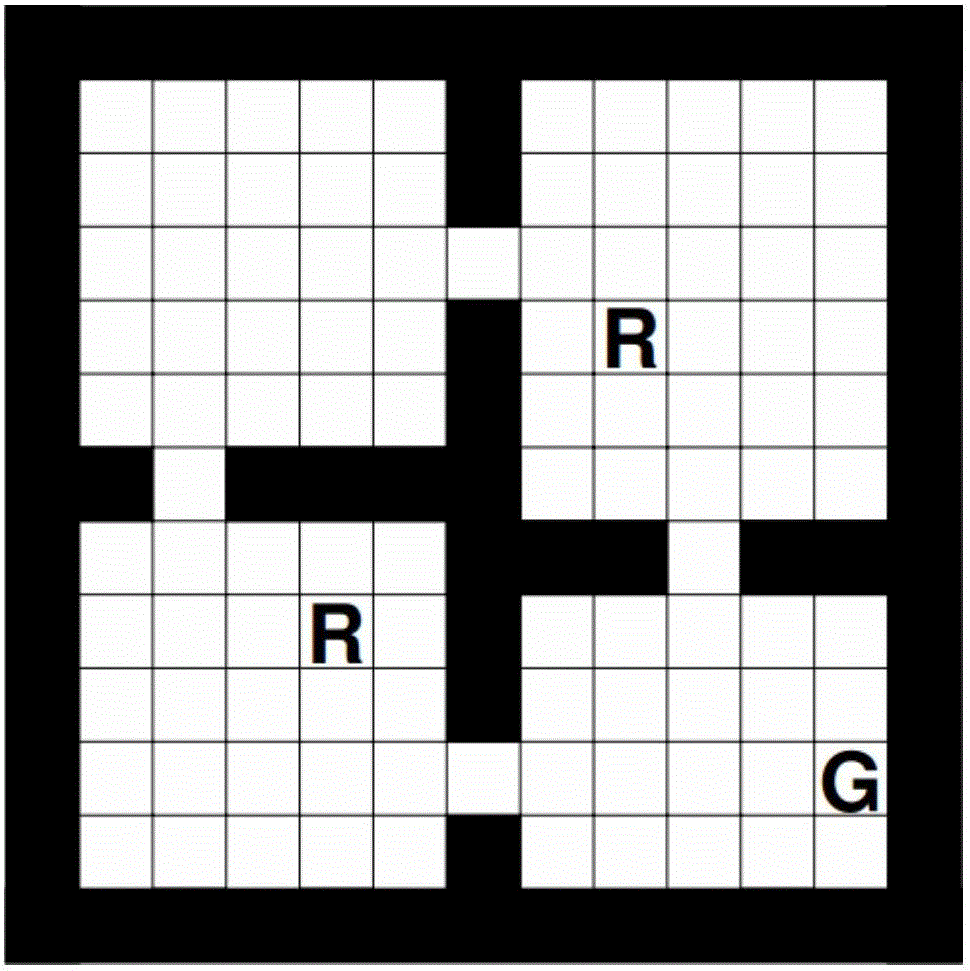
[0037] see figure 1 As shown, the black border is a wall, and the robot cannot reach it; the two R points are places with less garbage, and the reward is 0 when the goal is reached; the point G is the place with more garbage, and the reward is 50 when the goal is reached; The remaining grid rewards are -1.
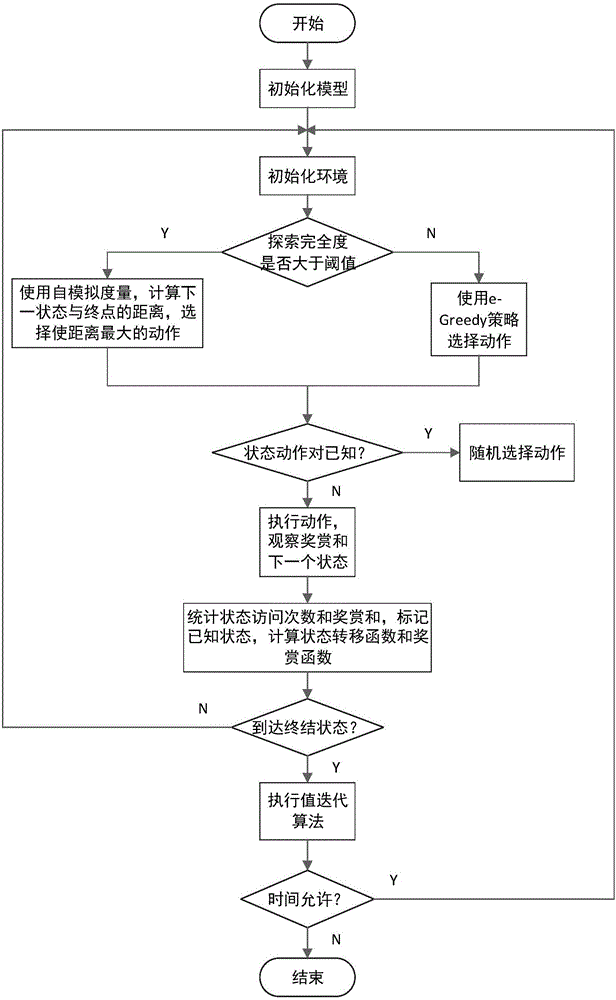
[0038] refer to figure 2 As shown, this embodiment is based on the model learning cleaning robot optimal target path planning method, including the following steps:
[0039] Step 1) Initialize the model, set R(x,u)=R max , f(x,u,x′)=1, where R(x,u) is the reward function, f(x,u,x′) is the state transition function, R max is the maximum reward value, x and u are state-action pairs, and x′ is the next state transferred to after executing x and u;
[0040] Step 2) Initialize the environment, set the starting position of the robot as the grid on the upper left of the map;
[0041] Step 3) Judging the current exploration completeness Where C(x,u) is the number of times t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More