

Flashback method and device of distributed object-based storage system
An object storage and distributed technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as high complexity, difficult to achieve flashback speed, and high energy consumption.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

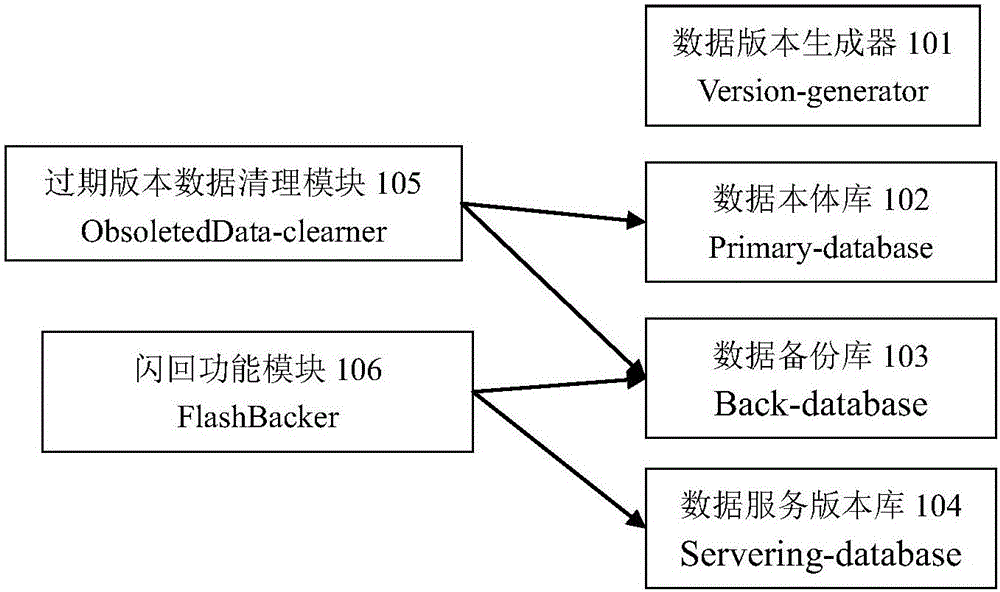
Examples
Embodiment 1
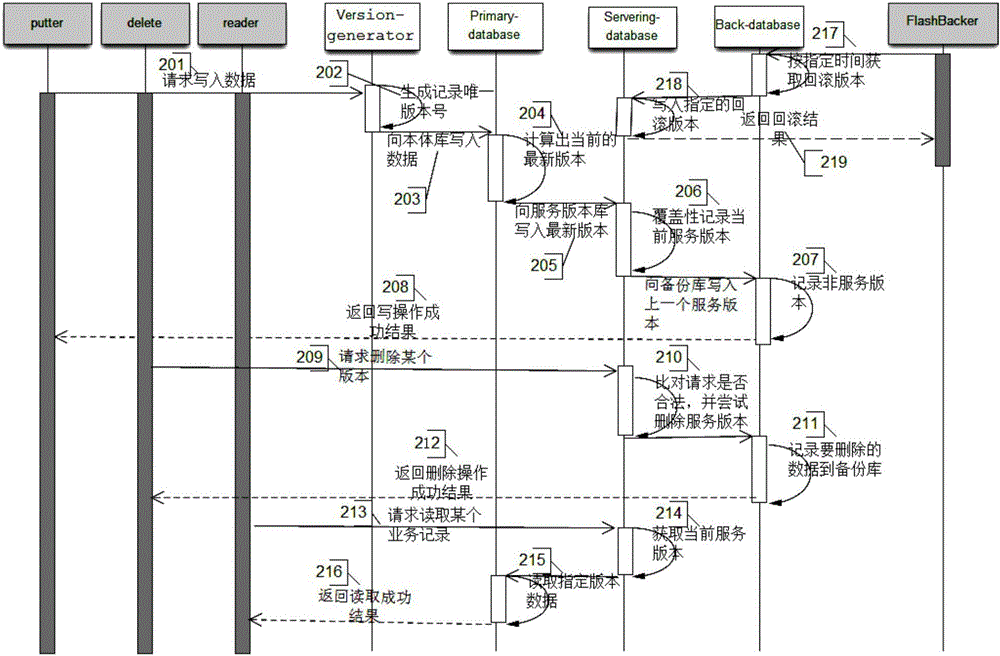
[0069] Example 1, write the data whose business primary key is 100 for the first time, the specific steps are as follows:
[0070] Step 202: After receiving the data write request, the storage system calls Version-generator 101 to generate a unique version number v1;
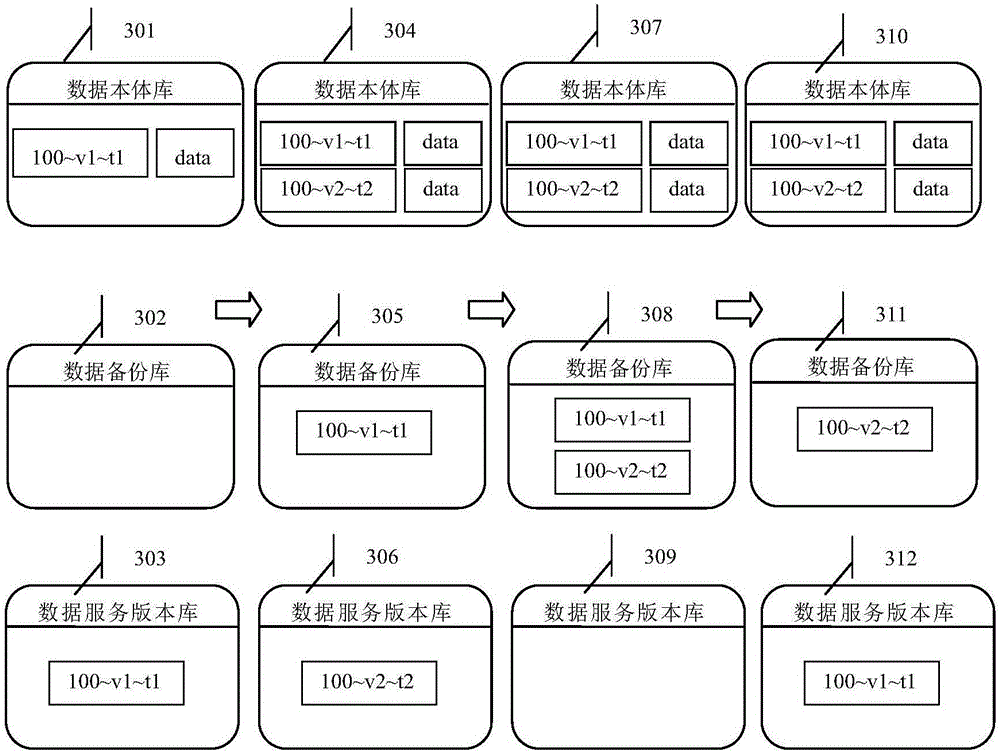
[0071] Step 203: the storage system writes the object data ontology to the Primary-database 102, and the storage primary key is designed to be 100~v1~t1. The result is like image 3 Shown in 301.
[0072] Step 204: Since the record with the business primary key 100 is written for the first time, the latest record of the data with the business primary key 100 is 100~v1~t1 according to the calculation of the Primary-database 102.
[0073] Steps 205-206: Record 100-v1-t1 in the Servering-database 104, use 100-v1-t1 as the primary key for recording, and write null values for the corresponding data. The result is like image 3 Shown in 303.
[0074] Step 207: Since there is no historical version for the record...
Embodiment 2
[0075] Embodiment 2, updating the data whose business primary key is 100, the specific steps include:
[0076] Step 202: Since the data whose business primary key is 100 has been written before, when the storage system receives the write request, it calls Version-generator 101 to generate the unique version number of the data as v2;
[0077] Step 203: the storage system writes the object data ontology to the Primary-database 102, and the primary key is designed to be 100~v2~t2. The result is like Figure 3-3 04.
[0078] Step 204: Since v2 is the latest version with the business primary key of 100, the latest data records of the data with the business primary key of 100 are 100~v2~t2 through the calculation of the Primary-database 102.
[0079] Steps 205-206: Record 100-v2-t2 in the Servering-database 104. The result is like Figure 3-3 06.
[0080] Step 207: Compared with the data stored with the primary key of "100-v2-t2", the stored primary key of "100-v1-t1" is the hi...
Embodiment 3
[0081] Example 3: Delete the data whose business primary key is 100, and the data version is v2. The specific steps are as follows:
[0082] Step 210: Receive the record request for deleting the business primary key of 100 sent by the system, find the service version with the business primary key of 100 in the Servering-database 104, and delete the version (v2) according to the request, from the Servering-database 104 Remove 100~v2~t2;. The result is like image 3 Shown in 309.
[0083] Step 211: Write the record with 100-v2-t2 as the primary key in the Back-database 103. The result is like Figure 3-3 08. However, the data in Primary-database 102 remains unchanged during this delete operation, and the result is as follows Figure 3-3 07.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More