

Broadband background noise and voice separation detection system and method
A background noise and speech detection technology, applied in speech analysis, instruments, etc., can solve the problems of misjudgment of noise as speech, poor adaptability, poor adaptability to quiet environments, etc., to achieve improved accuracy and good detection effect Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
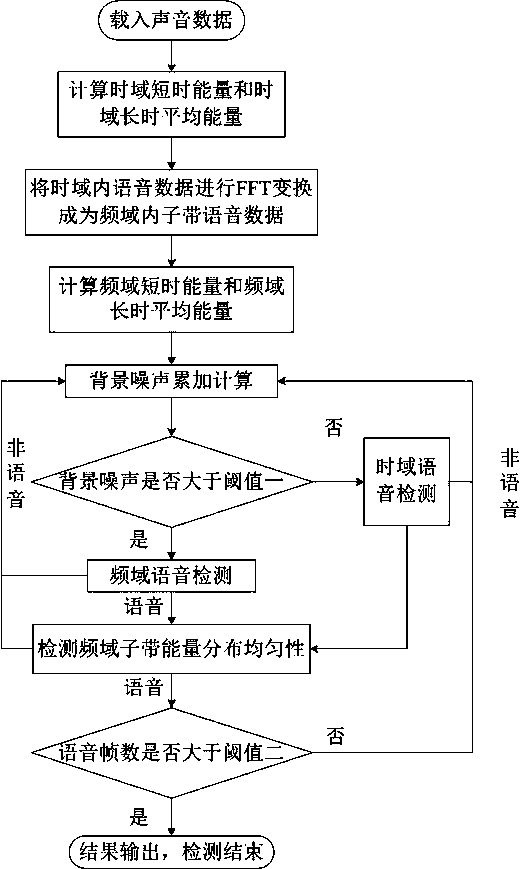
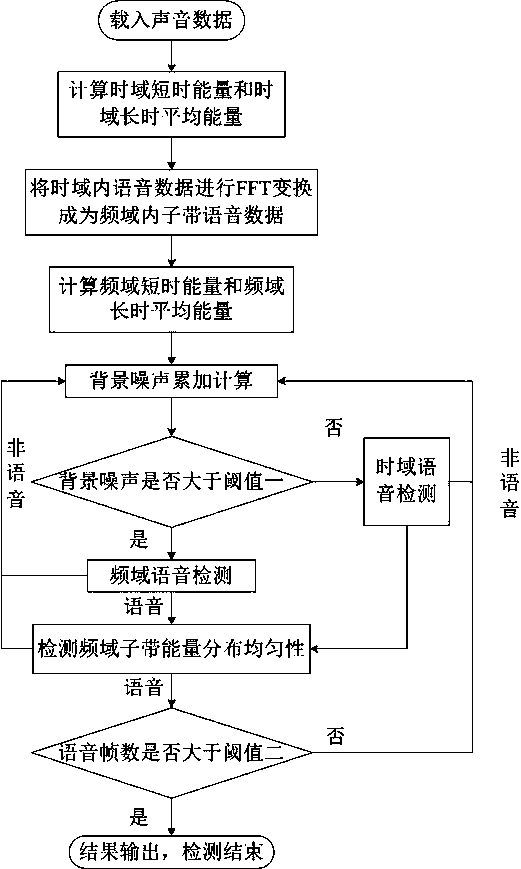
[0032] The present invention will be described in further detail below in conjunction with the examples and specific implementation methods, but this should not be interpreted as the scope of the above-mentioned subject of the present invention being limited to the following examples, and all technologies realized based on the content of the present invention belong to the present invention scope.
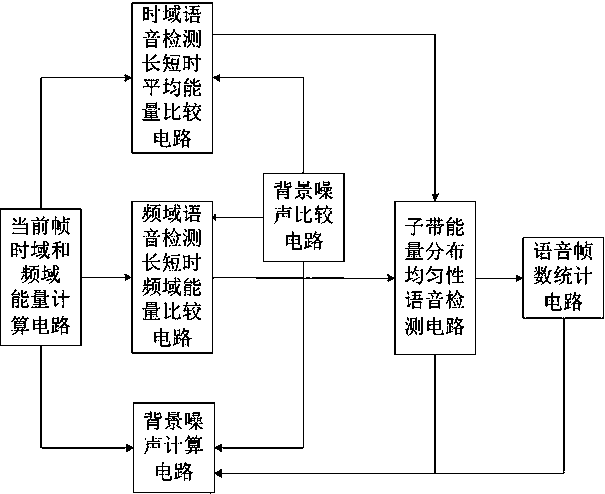
[0033] Such as figure 1 As shown, a wide-band background noise and speech separation detection system, the current frame time-frequency domain energy calculation circuit of the system, the background noise calculation circuit connected to the current frame time-frequency domain energy calculation circuit, and the time-domain speech detection length The average energy comparison circuit and the frequency-domain speech detection long-short time-frequency domain energy comparison circuit, the background connected with the background noise calculation circuit, the time-domain speech de...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More