

Method and apparatus for extracting webpage information
A technology of web page information and extraction method, which is applied in website content management, network data retrieval, special data processing applications, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
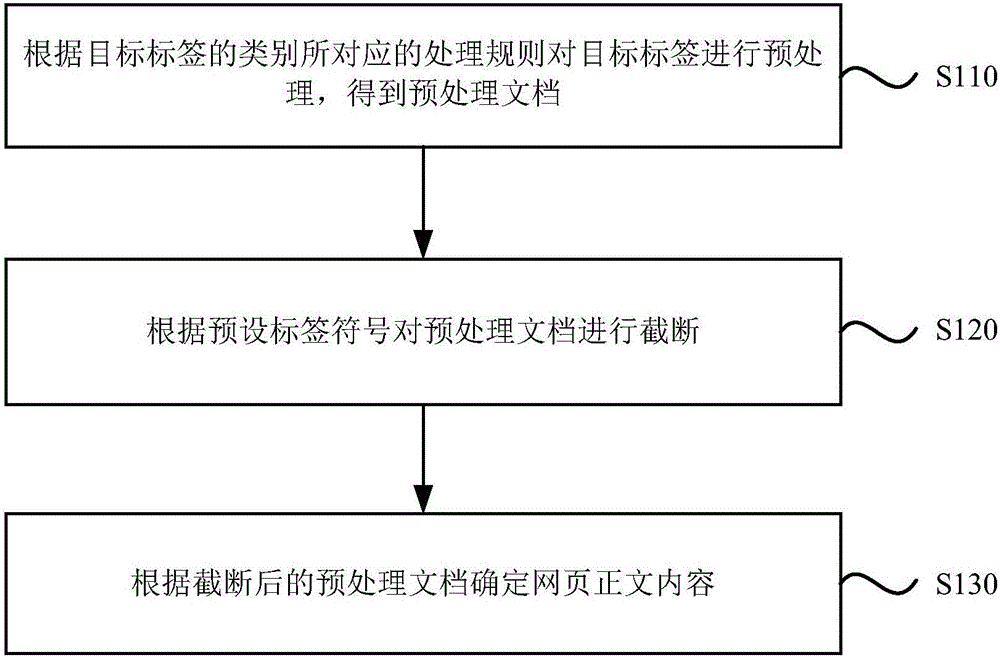
[0050] figure 1 It is a flow chart of a method for extracting webpage information provided by Embodiment 1 of the present invention. This embodiment is applicable to an application scenario of extracting webpage text information in the Internet, and the method can be executed by a server. Such as figure 1 As mentioned above, the method for extracting web page information specifically includes the following steps:
[0051] In step S110, the target tag is preprocessed according to the processing rule corresponding to the category of the target tag to obtain a preprocessed document.
[0052] Wherein, target tag can be hypertext markup language (Hyper Text Markup Language, HTML) label, and HTML is an application under the standard universal markup language, and hypertext refers to that non-text such as picture, link, program or music can be included in the page. Content, the structure of HTML may include a "head" part and a "body" part, wherein the head part provides information...
Embodiment 2
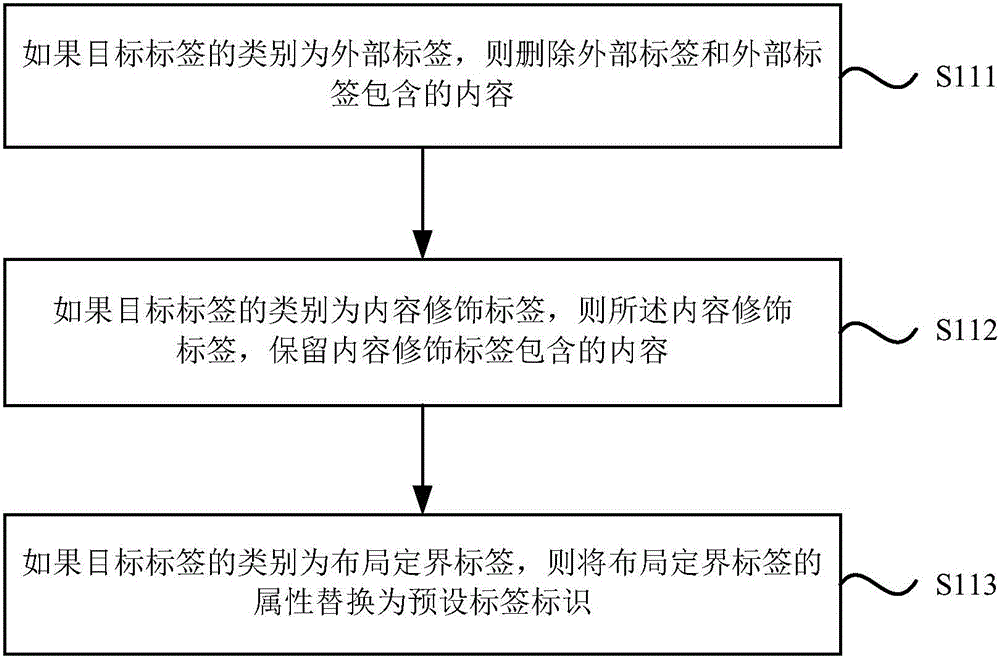
[0060] figure 2 A flow chart of a method for extracting webpage information provided by Embodiment 2 of the present invention is based on the above embodiments, as shown in figure 2 As shown, step S110 includes:
[0061] Step S111, if the category of the target tag is an external tag, delete the external tag and the content contained in the external tag.
[0062] Among them, the external label can be a label used outside the body, mainly can be, and Wait. In this application scenario, the method of deleting the external tag and the content contained in the external tag can be, for example, in an HTML webpage, a certain external tag and the contained content are " 文本A ", when preprocessing the web page, you need to put" 文本A "Delete all.
[0063] Step S112, if the category of the target tag is a content modification tag, delete the content modification tag, and retain the content contained in the content modification tag.
[0064] Among them, the conte...
Embodiment 3
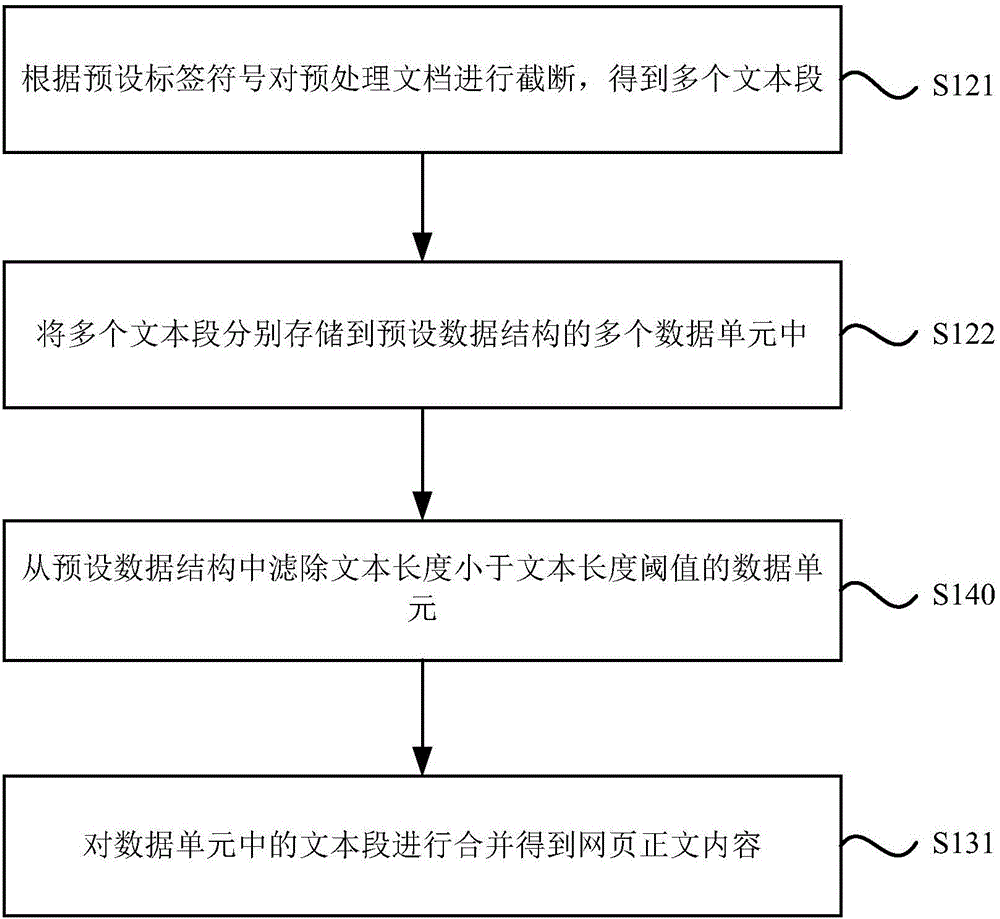
[0069] image 3 A flow chart of a method for extracting web page information provided by Embodiment 3 of the present invention is based on the above embodiments, as shown in image 3 As shown, step S120 includes:
[0070] Step S121, truncate the preprocessed document according to preset tag symbols to obtain multiple text segments.
[0071] In step S122, the multiple text segments are respectively stored in multiple data units of a preset data structure, the preset data structure is an array structure or a linked list structure, and the text segments correspond to the data units one by one.
[0072] Among them, an array can be a collection of elements of the same data type arranged in a certain order. In programming, for the convenience of processing, it is a form of organizing several variables of the same type in an orderly form. The linked list can be a non-sequential and non-sequential storage structure on the physical storage unit, and the logical order of the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More