

Repeating data deleting algorithm in cloud storage
A technology for deduplication and duplication of data, applied in digital data processing, input/output process of data processing, calculation, etc., can solve problems such as retrieval troubles, waste of cloud resources, etc., to avoid accidental deletion and omission, deletion High accuracy and good detection performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

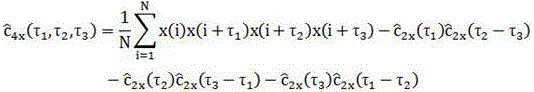
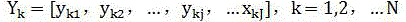
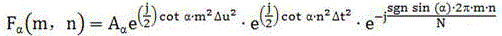
Examples
Embodiment Construction
[0019] Step 1: Data chunking
[0020] In cloud storage, it is divided into three roles, the client is responsible for collecting user information and command generation, the server is responsible for managing user operations and requests, that is, is responsible for identifying data redundancy, and the cloud space is responsible for storing user information. In this algorithm, the data must first be divided into blocks. Assuming that the information F is composed of several files, and each file is divided into blocks as a complete data block, then the complete data information flow is obtained as follows:
[0021]
[0022] Among them, t 0 , t g respectively represent the stagnation steps of the individual extremum and the global extremum of the data block boundary offset; T 0 , T g Respectively represent the stagnation step thresholds of the individual extremum and the global extremum that need to be disturbed.
[0023] Step 2: Generate a verification information storag...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More