

A deepdive-based domain text knowledge extraction method
A knowledge extraction and text technology, applied in text database query, unstructured text data retrieval, instruments, etc., can solve the problems of difficulty and lack of data utilization, achieve strong practicability and flexibility, and reduce costs.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0033] In order to describe the present invention more specifically, the technical solutions of the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
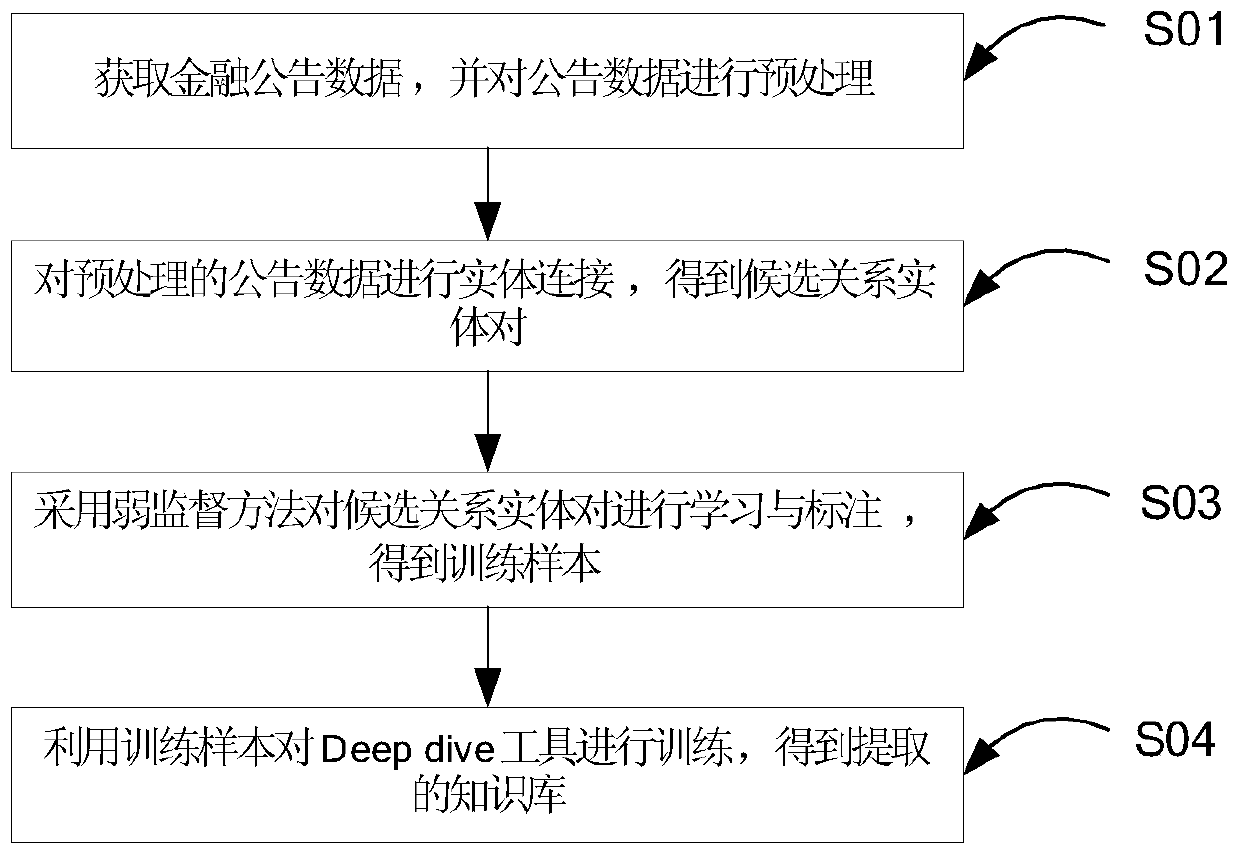
[0034] This example requires the analysis of financial announcement data to extract the knowledge of equity changes in the financial sector, so as to build a corresponding company equity knowledge base. The construction method of the overall corresponding corporate equity knowledge base is as follows: figure 1 Shown:
[0035] S01, obtain the corresponding financial announcement data, convert it into txt text content through a series of tools, and use the jieba tool to segment the announcement data, and use Stanford's core NLP tool to perform part-of-speech tagging and named entity tagging on the word-segmented announcement data and syntax-dependent processing to obtain the preprocessed announcement data, figure 2 Shown is a schematic diagram of the res...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More