

Voice enhancing method based on multiresolution auditory cepstrum coefficient and deep convolutional neural network
A deep convolution, neural network technology, applied in speech analysis, speech recognition, instruments, etc., can solve the problems of unsatisfactory performance of speech enhancement algorithms, unsatisfactory algorithm performance, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach
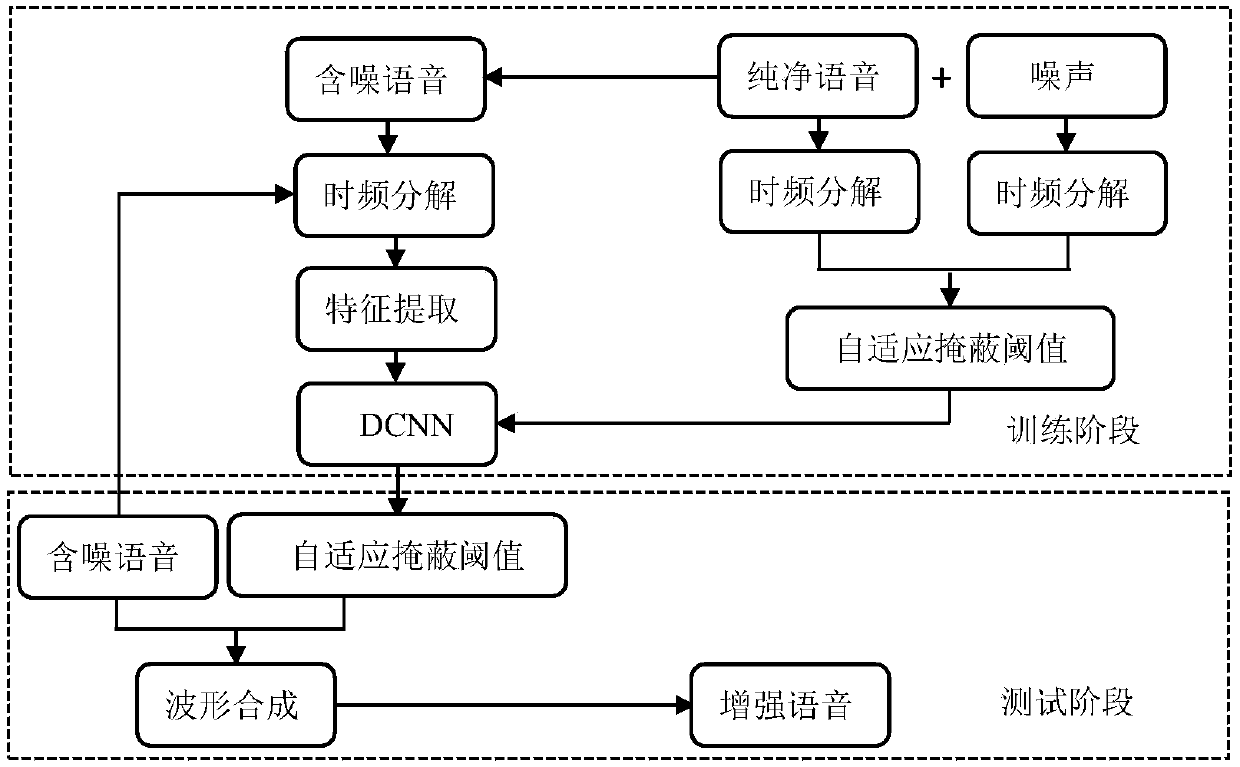
[0031] Such as figure 1 As shown, the present invention provides a kind of speech enhancement method based on multi-resolution auditory cepstral coefficient and deep convolutional neural network, comprising the following steps:
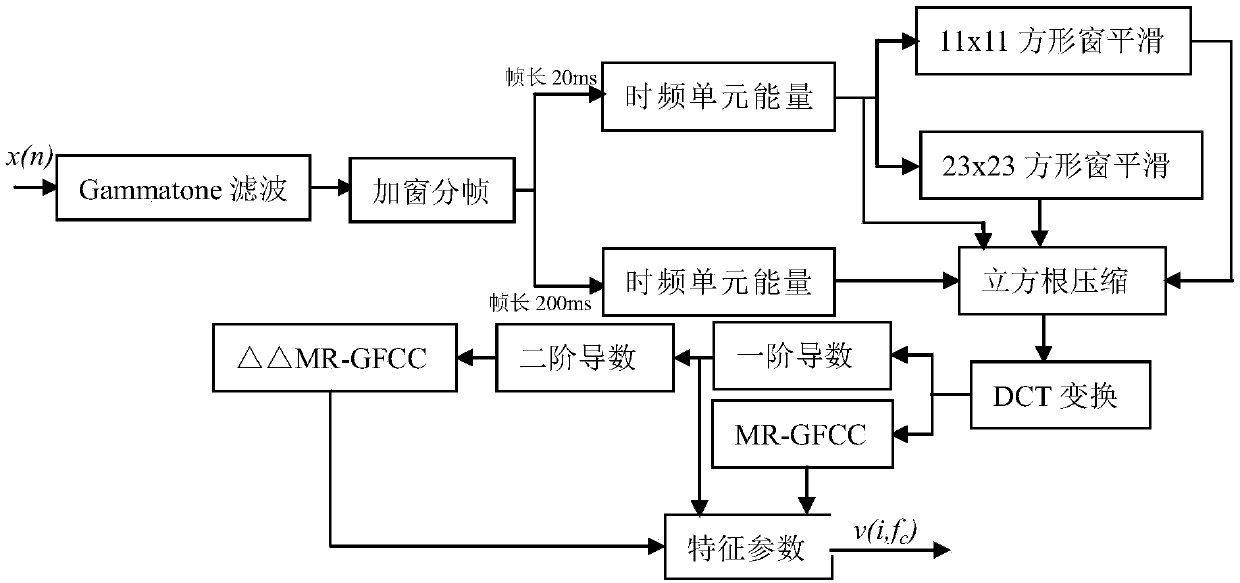
[0032] Step 1, performing time-frequency decomposition on the input signal, and then performing windowing and framing processing to obtain the time-frequency representation of the input signal;
[0033] (1) First, time-frequency decomposition is performed on the input signal;
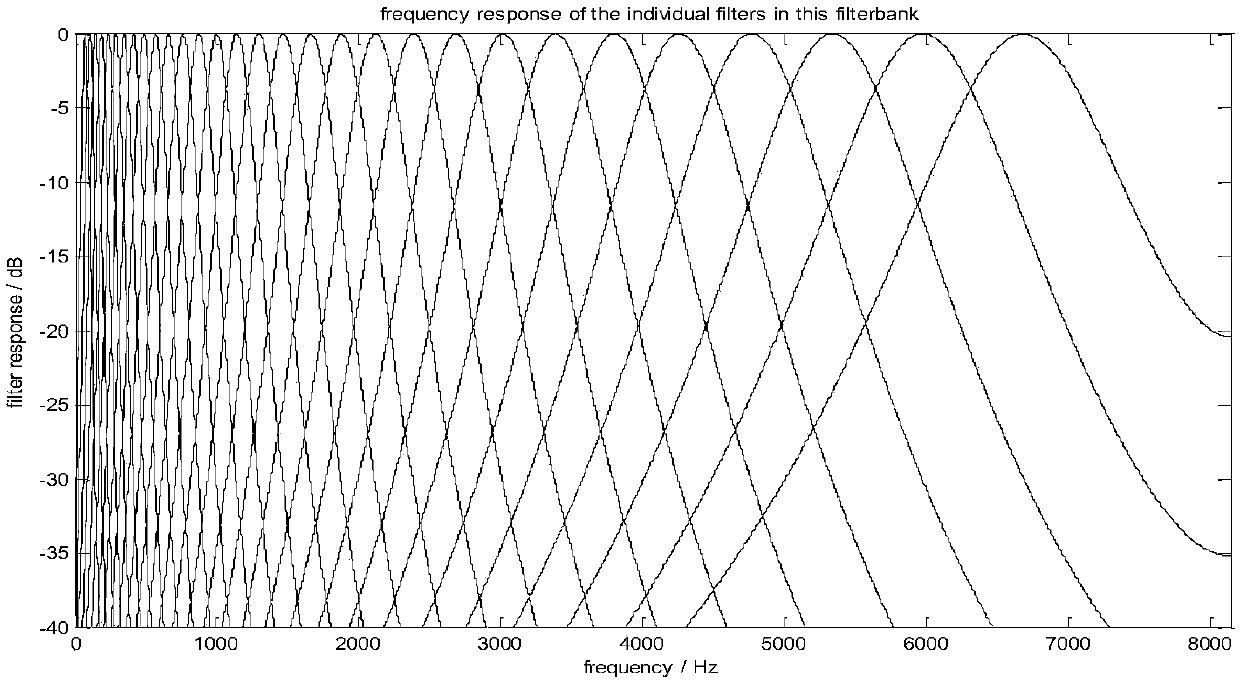
[0034] The speech signal is a typical time-varying signal, and the time-frequency decomposition focuses on the time-varying spectral characteristics of the components of the real speech signal, and decomposes the one-dimensional speech signal into a two-dimensional signal represented by time-frequency, aiming to reveal How many frequency component levels are contained in a speech signal and how each component varies with time. Gammatone filter is a good tool for time-frequenc...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More