

Tree diagram-based data similarity matching method and apparatus
A technology of data similarity and similarity matching, which is applied in the direction of electrical digital data processing, special data processing applications, instruments, etc. Consider the effects of variables
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
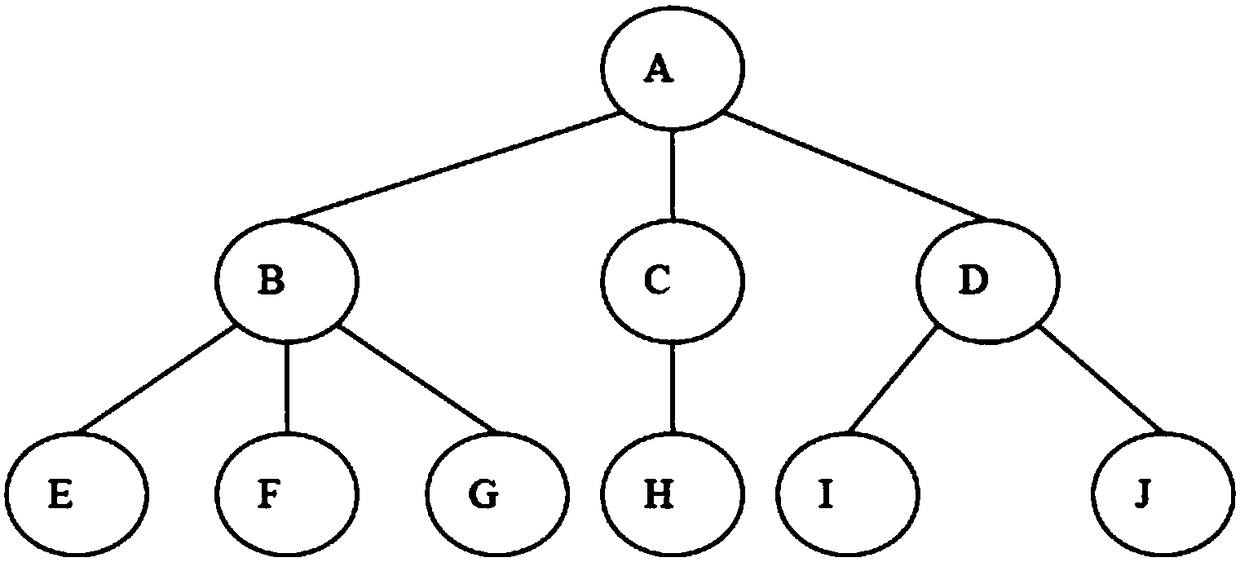
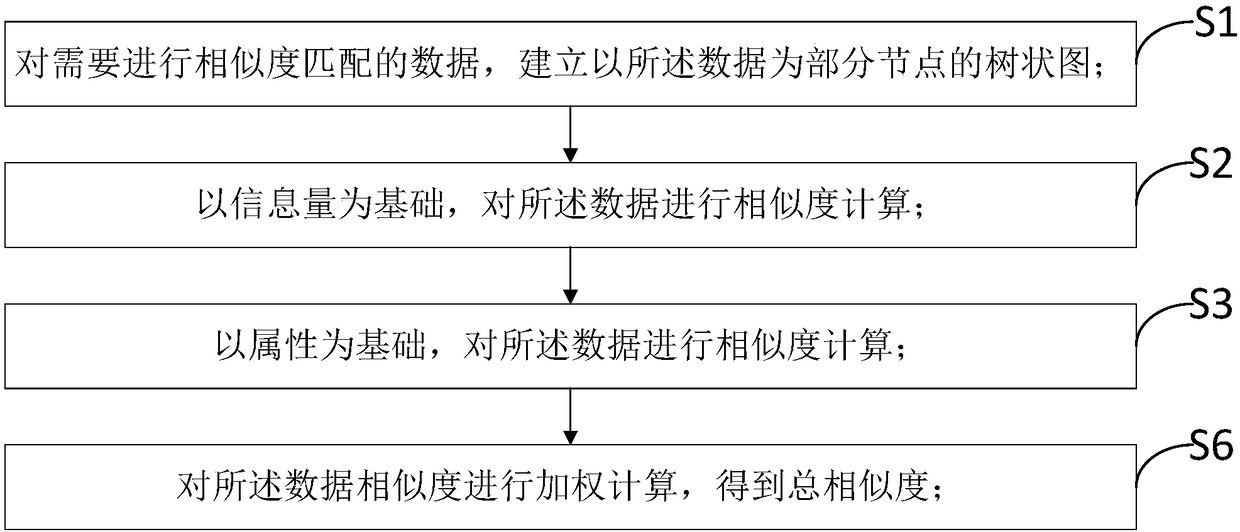
[0060] like figure 2 As shown, it is a flowchart of a data similarity matching method based on a dendrogram in the present invention, wherein the data similarity matching method based on a dendrogram includes:
[0061] Step S1, for the data requiring similarity matching, establish a dendrogram with the data as part of the nodes;
[0062] The need to perform similarity matching on the data means that there must be a connection between these data, that is to say, there is a dendrogram with these data as some nodes to illustrate the relationship between these data. Therefore, a dendrogram with these data as part of nodes can be established or found.
[0063] Step S2, based on the amount of information, perform similarity calculation on the data;
[0064] Each data has its information content, and the similarity between two data can be calculated according to the information content.
[0065] Step S3, performing similarity calculation on the data based on attributes;
[0066]...
Embodiment 2
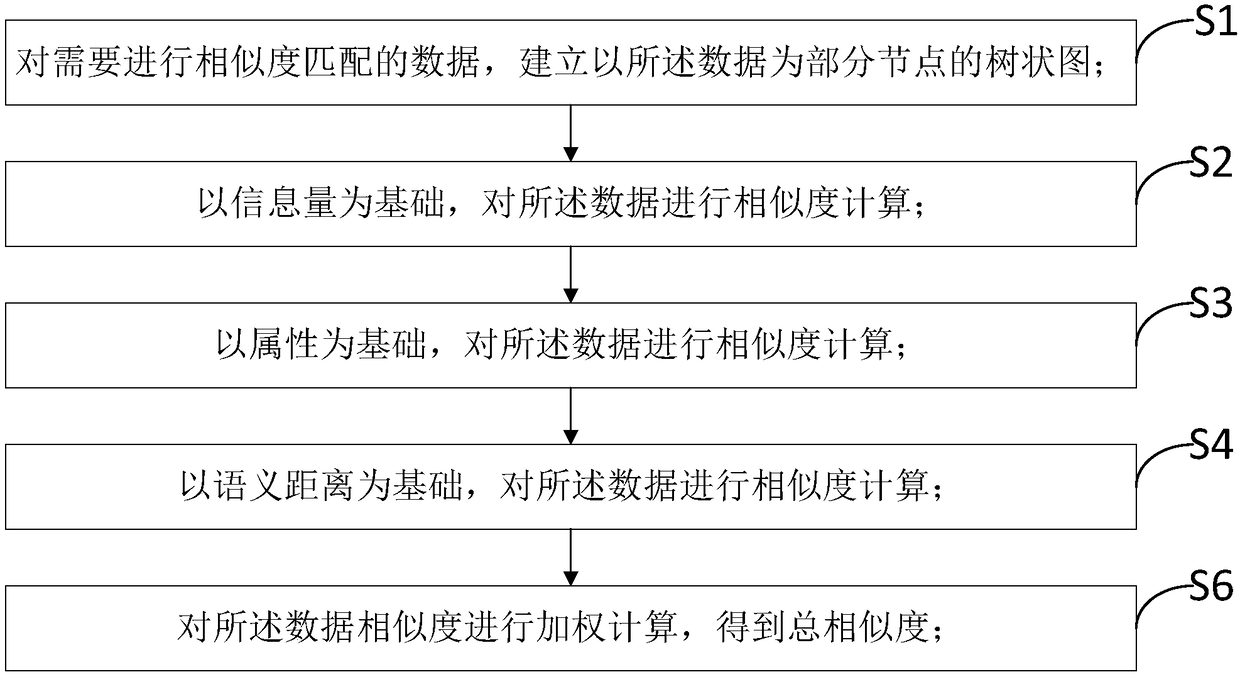
[0071] As described above, the data similarity matching method based on the dendrogram, the difference of this embodiment is that, as image 3 As shown, the dendrogram-based data similarity matching method also includes:
[0072] Step S4, performing similarity calculation on the data based on the semantic distance;
[0073] Semantic distance refers to the number of edges experienced by the shortest path in the path connecting two corresponding nodes in the ontology tree. The semantic distance between two data in the same dendrogram is related to its similarity, so the similarity between two data can be calculated according to the semantic distance.
[0074] In this way, when calculating the similarity of data, the semantic distance is also added as a variable that affects the similarity, which increases the consideration variables when calculating the similarity and improves the accuracy of the similarity.
Embodiment 3
[0076] As described above, the data similarity matching method based on the dendrogram, the difference of this embodiment is that, as Figure 4 As shown, the dendrogram-based data similarity matching method also includes:
[0077] In step S5, the similarity calculation is performed on the data based on the semantic density.
[0078] Semantic density refers to the number of sibling nodes of the data. The number of child nodes of different branch nodes in the dendrogram is different. If in the dendrogram, the greater the density of a certain local node, the greater the refinement of the concept of the node, and the corresponding semantic similarity The higher the degree. Therefore, the similarity between two data can be calculated according to the semantic density.
[0079] In this way, when calculating the similarity of data, the semantic density is also added as a variable that affects the similarity, which increases the consideration variables when calculating the similari...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More