

Task scheduling method and device
A job scheduling and job technology, applied in the field of distributed computing, can solve the problems of inability to wait for resources, distributed system consumption, reduce distributed system throughput and resource utilization, etc., to improve rationality, throughput and resources. Utilization, the effect of improving processing efficiency and resource utilization
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0058] This embodiment provides a job scheduling method, such as figure 1 shown, including the following steps:
[0059] Step 101, for the first job in the waiting queue in the online mode, according to the task information of all jobs before the first job, estimate the first time point when the available resources meet the requirements of the first job;
[0060] Step 102, comparing the first time point with the upper limit of the waiting time of the first job;
[0061] Step 103, when the first time point is greater than the upper limit of the waiting time of the first job, turn the first job to run in an offline mode.
[0062] In this embodiment, when the scheduled job is in the waiting state, the first time point at which the available resources can meet the demand of the scheduled job can be estimated at any time according to the own situation of the scheduled job and the current running status of other jobs, if the If the first time point is greater than the upper limit ...
example 1
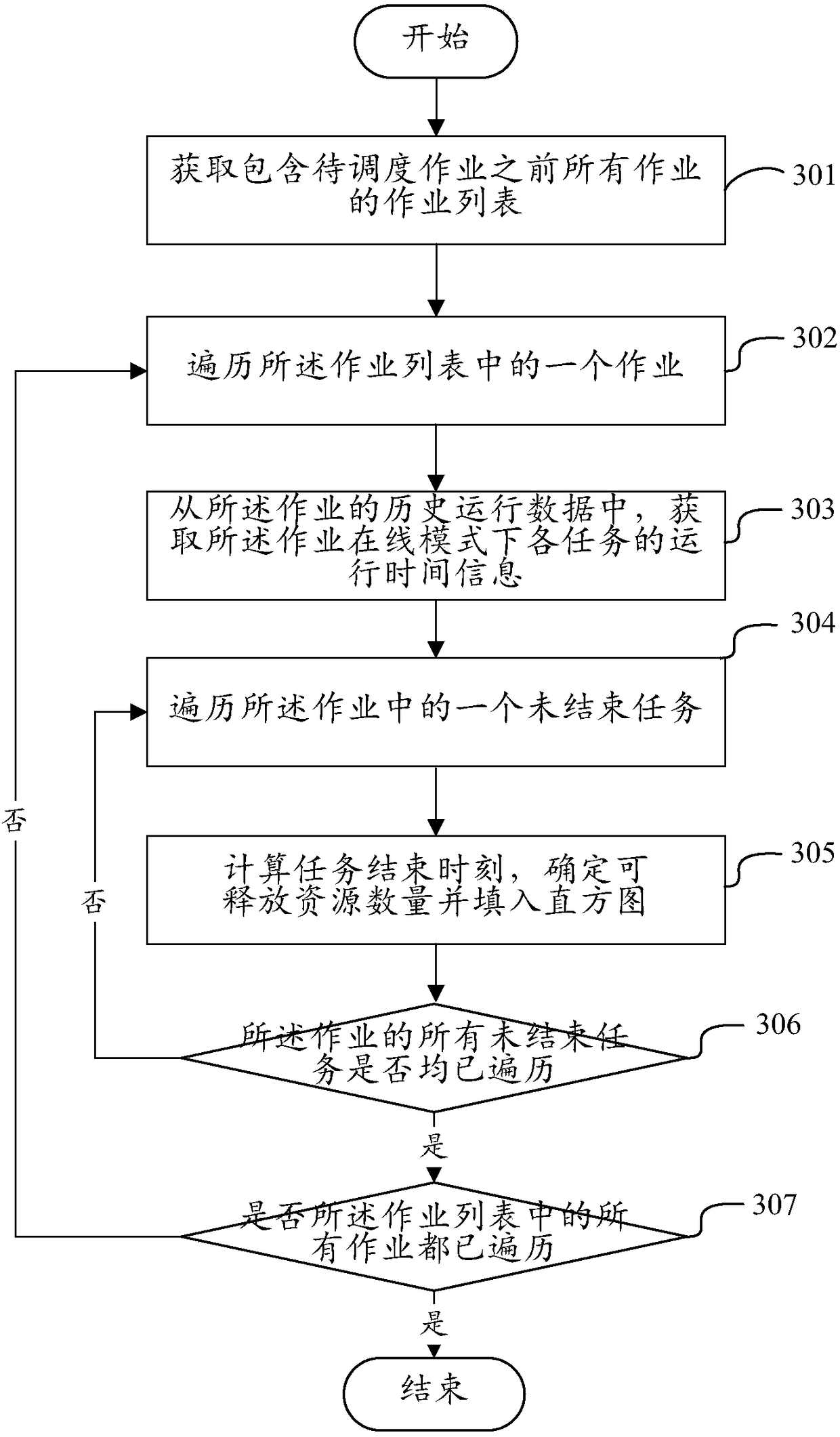
[0086] The process of estimating the end time of the task and the corresponding amount of releasable resources and the way of saving the histogram are described in detail below in the form of an example.
[0087] Before executing the scheduling process on the jobs in the waiting queue, you can pre-estimate the task end time and the number of releasable resources at the end of the unfinished tasks in the jobs before the job, and convert them into a histogram for easy storage.
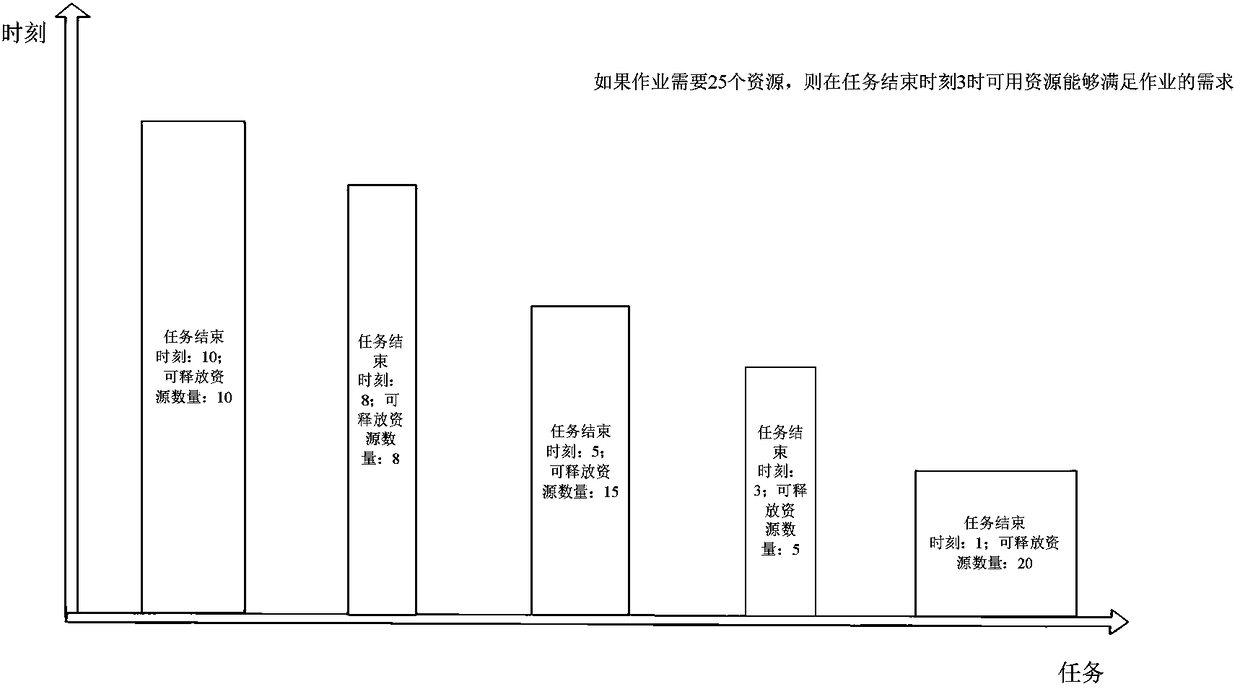
[0088] Such as figure 2 Shown is an example of a histogram. Each bar in the histogram corresponds to an unfinished task. The width of the bar indicates the amount of releasable resources of the unfinished task. The time point corresponding to the bar is the end of the task of the unfinished task. time.
[0089] Such as image 3 As shown, the end time of the task and the corresponding amount of releasable resources can be estimated and converted into histogram elements through the following process:
...
example 2
[0100] The method of determining the lower limit of the waiting time and the upper limit of the waiting time of the job in this embodiment will be described in detail below with specific examples.
[0101] In practical applications, the lower limit of waiting time and the upper limit of waiting time can be determined by the following formula:
[0102] Lower limit of waiting time = job submission time + waiting time threshold;
[0103] Upper limit of waiting time = job submission time + max (waiting time threshold, Tx2-Tx1);
[0104] Among them, Tx2 represents the running time of the job in offline mode, Tx1 represents the running time of the job in online mode, and the waiting time threshold can be an empirical value, which can be calculated by historical running data of each job in the online mode According to the analysis, for example, the waiting time threshold may be set as 10 seconds.
[0105] In practical applications, when a job is submitted to the online mode, if the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More