

A Cross-Domain Text Classification Method Based on Adaptive Noise Reduction Encoder
A text classification, cross-domain technology, applied in the field of network text data information for cross-domain classification, can solve the problems of enlarged feature space, sensitivity to noise coefficient, increased text data high-dimensionality, sparsity, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

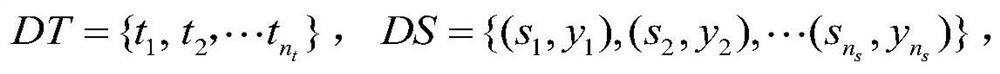
Examples
Embodiment Construction
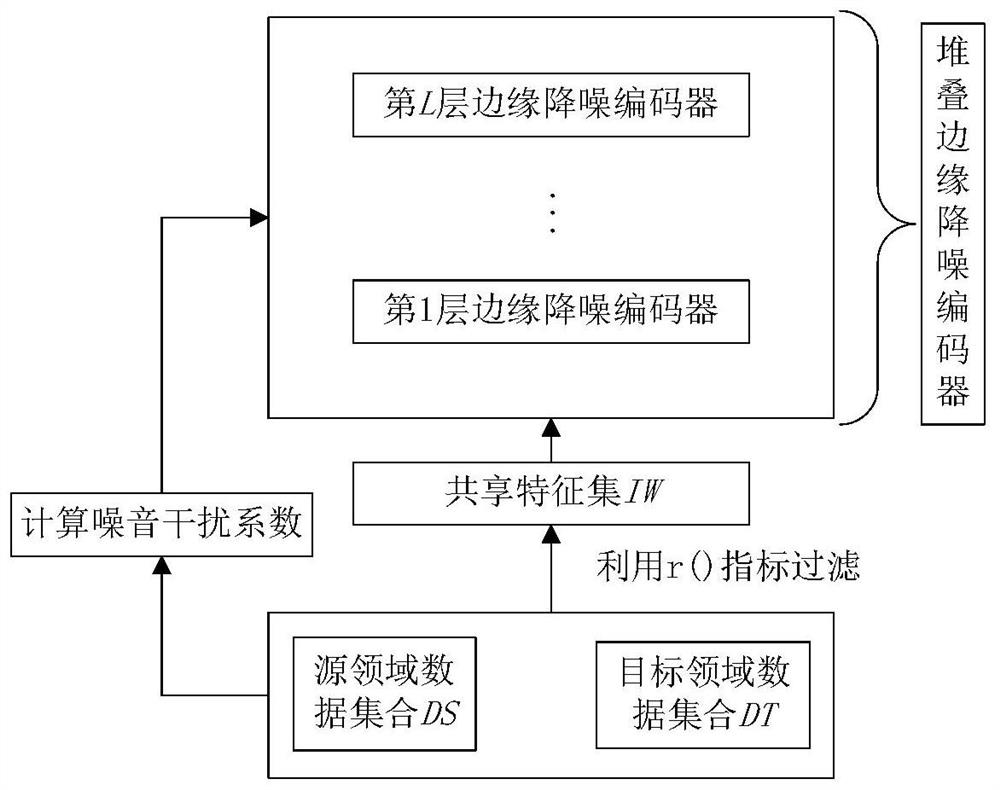
[0052] see figure 1 , the cross-domain text classification method based on the adaptive noise reduction encoder in this embodiment is carried out in the following steps:
[0053] Step 1: Statistical feature words and their frequency of occurrence in the source and target domains
[0054] Obtain the target domain data set DT and the source domain data set DS with label information respectively,
[0055]
[0056] t i is the i-th sample in the target domain data set DT, no t is the number of samples in the target domain data set DT, Indicates the i-th sample t in the target field data set DT i The a-th feature word in , a=1,2,...,nw t , nw t is the number of characteristic words of samples in the target domain data set DT.
[0057] the s j is the jth sample in the source domain data set DS, no s is the number of samples in the source domain data set DS, w b j Indicates the jth sample s in the source domain data set DS j The b-th feature word in , b=1,2,...,nw ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More