

An unmanned ship path planning method based on a Q learning neural network
A path planning and neural network technology, applied in the field of intelligent control of unmanned ships, can solve problems such as path planning in unknown fields
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

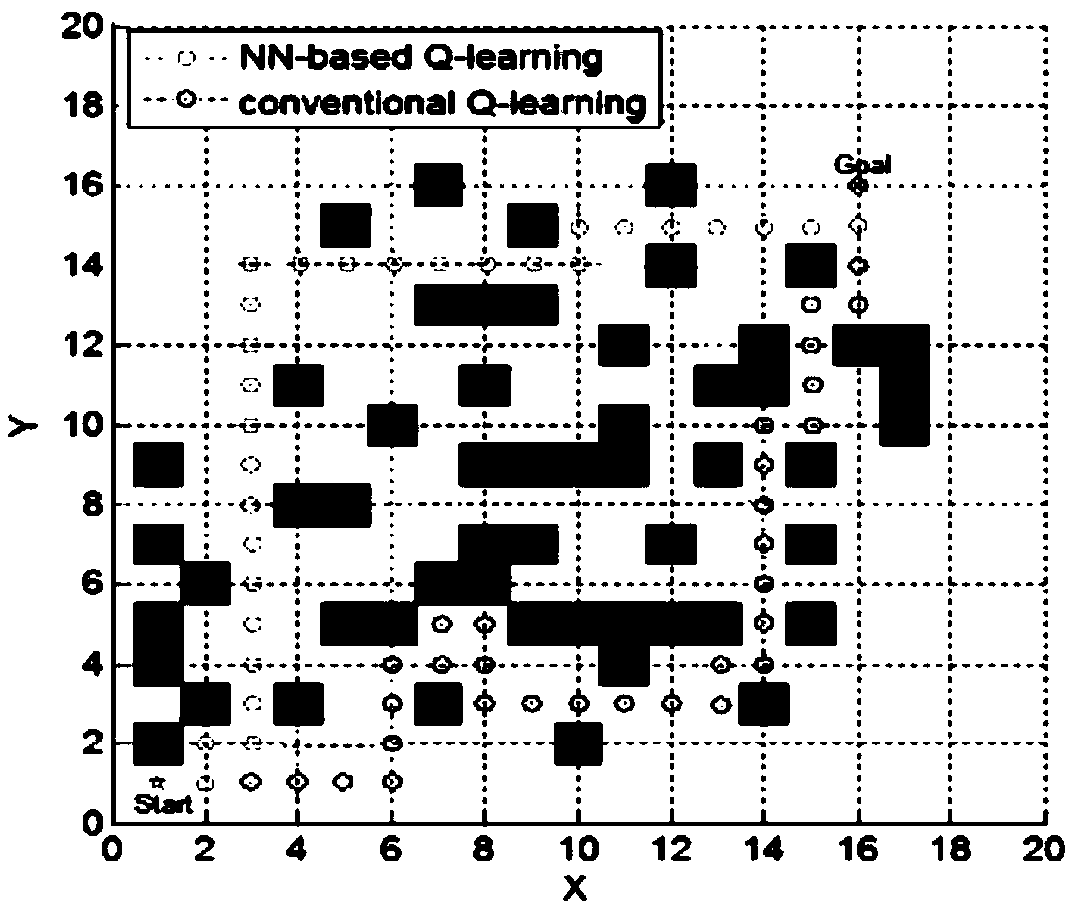
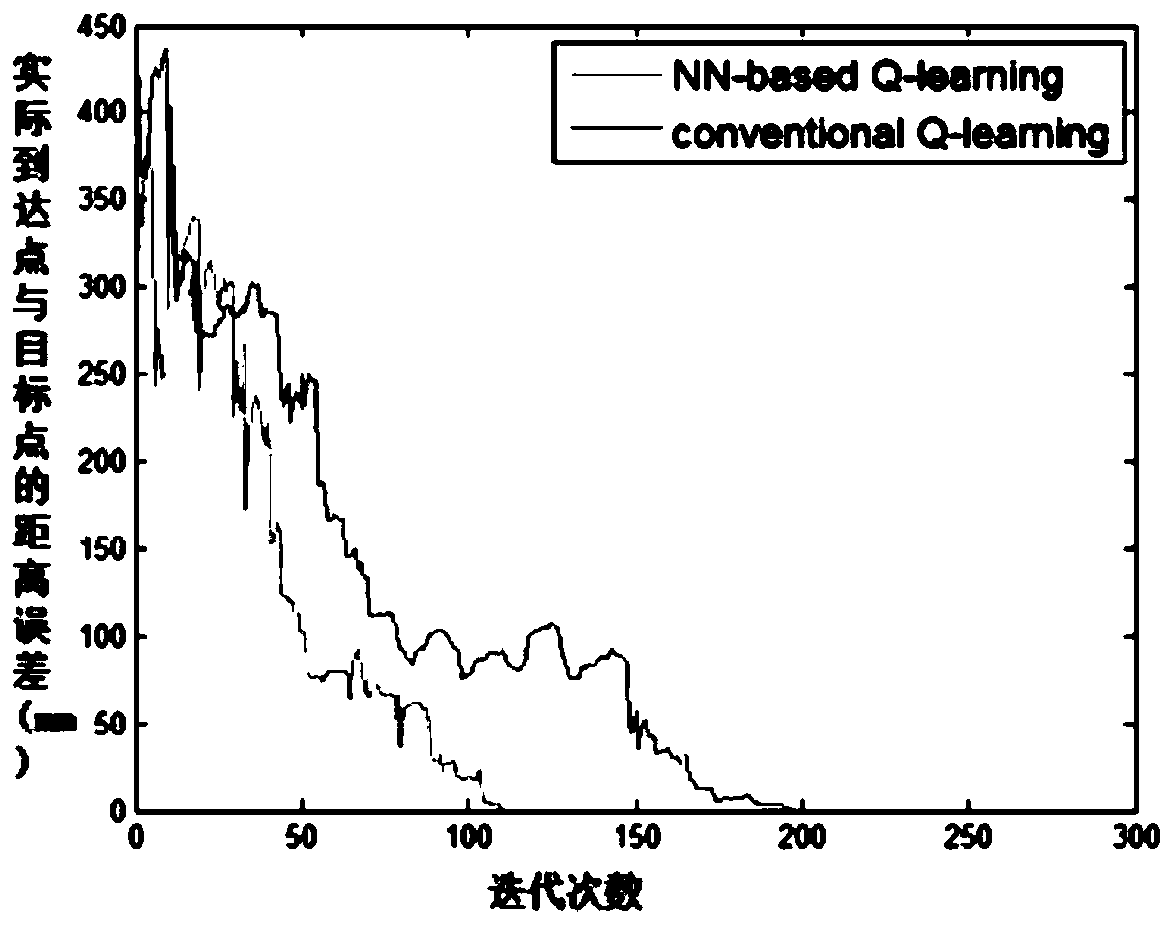
Examples
Embodiment 1
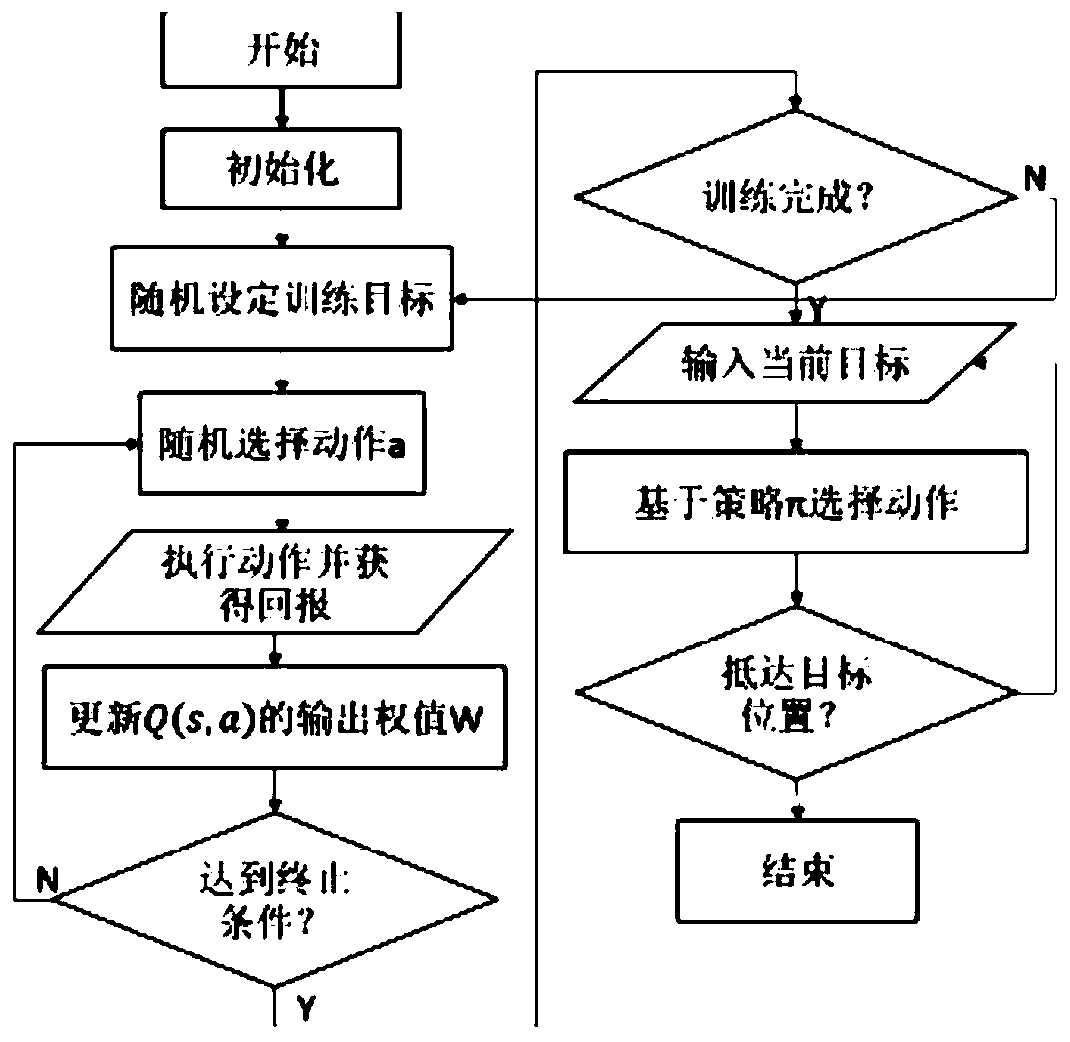
[0078] A kind of unmanned ship path planning method based on Q learning neural network of the present embodiment comprises the following steps: a kind of unmanned ship path planning method based on Q learning neural network is characterized in that, comprises the following steps:
[0079] a), initializing storage area D;
[0080] b) Initialize the Q network, the initial value of the state and action; the Q network contains the following elements: S, A, P s,α , R, where S represents the set of system states the USV is in, A represents the set of actions that the USV can take, P s,α Represents the system state transition probability, R represents the reward function;
[0081] c), Randomly set the training target;
[0082] d), randomly select action a t , get the current reward r t , the next moment state s t+1 , will (s t ,a t ,r t ,s t+1 ) is stored in the storage area D;
[0083] e), randomly sample a batch of data from the storage area D for training, that is, a ba...
Embodiment 2
[0088] A kind of unmanned ship path planning method based on Q-learning neural network of the present embodiment, based on embodiment one, traditional Q-learning algorithm specifically is:
[0089] Q learning is based on the Markov decision process (Markov Decision Process) to describe the problem. The Markov decision process contains 4 elements: S, A, P s,a ,R. Among them, S represents the system state set where the USV is located, that is, the current state of the USV and the state of the current environment, such as the size and position of obstacles; A represents the set of actions that the USV can take, that is, the direction of rotation of the USV; P s,a Represents the system model, that is, the system state transition probability, P(s'|s,a) describes the probability of the system reaching state s after executing action a in the current state s; R represents the reward function, which has the current state and all The action taken decides. Think of Q-learning as an inc...
Embodiment 3
[0108] An unmanned ship path planning method based on the Q-learning neural network in this embodiment is based on the second embodiment, as long as the future TD deviation value is unknown, the above update cannot be performed. However, they can be calculated incrementally by using traces. η t (s, a) is defined as a characteristic function: when (s, a) occurs at time t, it returns 1, otherwise it returns 0. For simplicity, ignoring the learning efficiency, define a trace e for each (s, a) t (s,a)
[0109]
[0110]
[0111] Then at time t the online update is
[0112] Q(s,a)=Q(s,a)+α[δ' t n t (s,a)+
[0113] δ t e t (s,a)] (8)
[0114] Among them, the function Q(s, a) is to perform action a in state s, α is the learning rate, η t (s,a) is the characteristic function, e t (s,a) is the trace, δ' t Represents the bias value of past learning, δ 1 is the deviation value learned now, δ 1 is the deviation value δ' between the cumulative return R(s) and the current...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More