

A power grid power supply reliability level clustering method and system
A grid power supply and reliability technology, applied in the field of clustering, can solve problems such as unsatisfactory results and inability to obtain clustering results, and achieve the effects of improving clustering effects, increasing credibility, and reducing dimensions
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
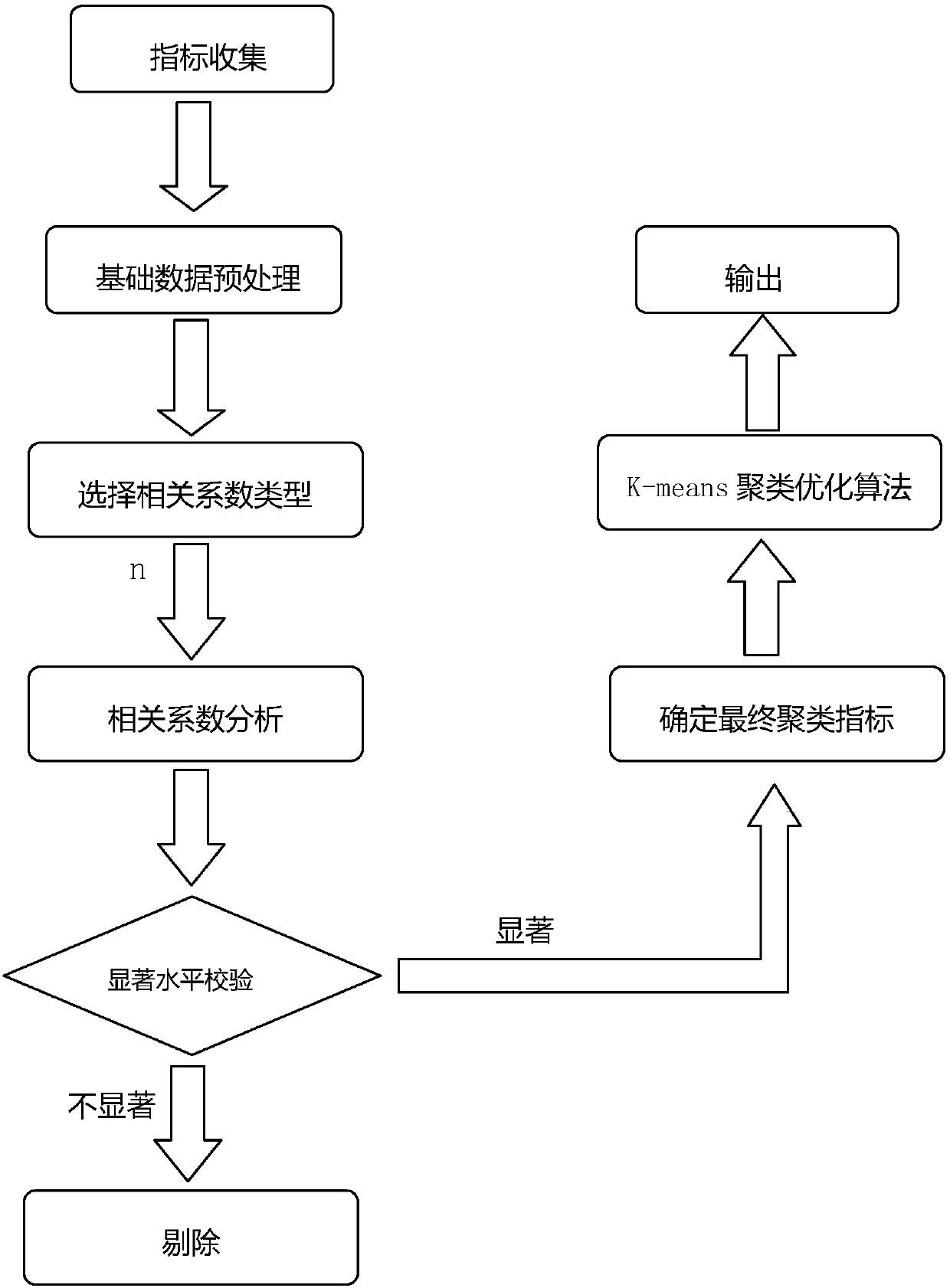
[0066] In the present invention, the input data is preprocessed, and the significance of the correlation coefficient is checked after the correlation processing. In addition, there is an important step of using other auxiliary methods-using the principal component analysis method for demonstration and discrimination. Then, the optimized cost function is used for clustering, so that the clustering can distinguish the data with small similarity between classes as much as possible. Directly apply the output clustering results without reprocessing the applied data, such as abnormal data, even if the clustering results are good, it is difficult to achieve good results in engineering applications. Therefore, in actual engineering applications, the actual situation or data used should also be discriminated against abnormalities, so that abnormal data will not participate in the calculation of the same category.
[0067] The present invention provides a grid power supply reliability l...
Embodiment 2
[0094]This embodiment is to study how to evaluate the reliability level of the State Grid prefecture-level power supply company. The evaluation content specifically includes two aspects: one is the average power outage time of users; the other is the average number of power outages of users. From the perspective of business analysis, the main factors affecting the reliability of power supply are connection rate, transferable rate, line segmentation rate, ring network rate, cable rate, distribution automation rate, equipment level, etc. However, whether there is a relationship between these factors and how strong the relationship is cannot be analyzed in detail in the business, and auxiliary analysis and judgment are required.
[0095] In this study, the factors that affect the reliability index are selected to establish an index set. After collecting the index set, the abnormal data is processed and corrected. Through business analysis, the prefecture-level power supply compani...
Embodiment 3
[0121] Based on the same inventive idea, the present invention also provides a clustering system based on the K-means algorithm for the reliability level of power grid power supply, its structure diagram is as follows Figure 4 shown, including:
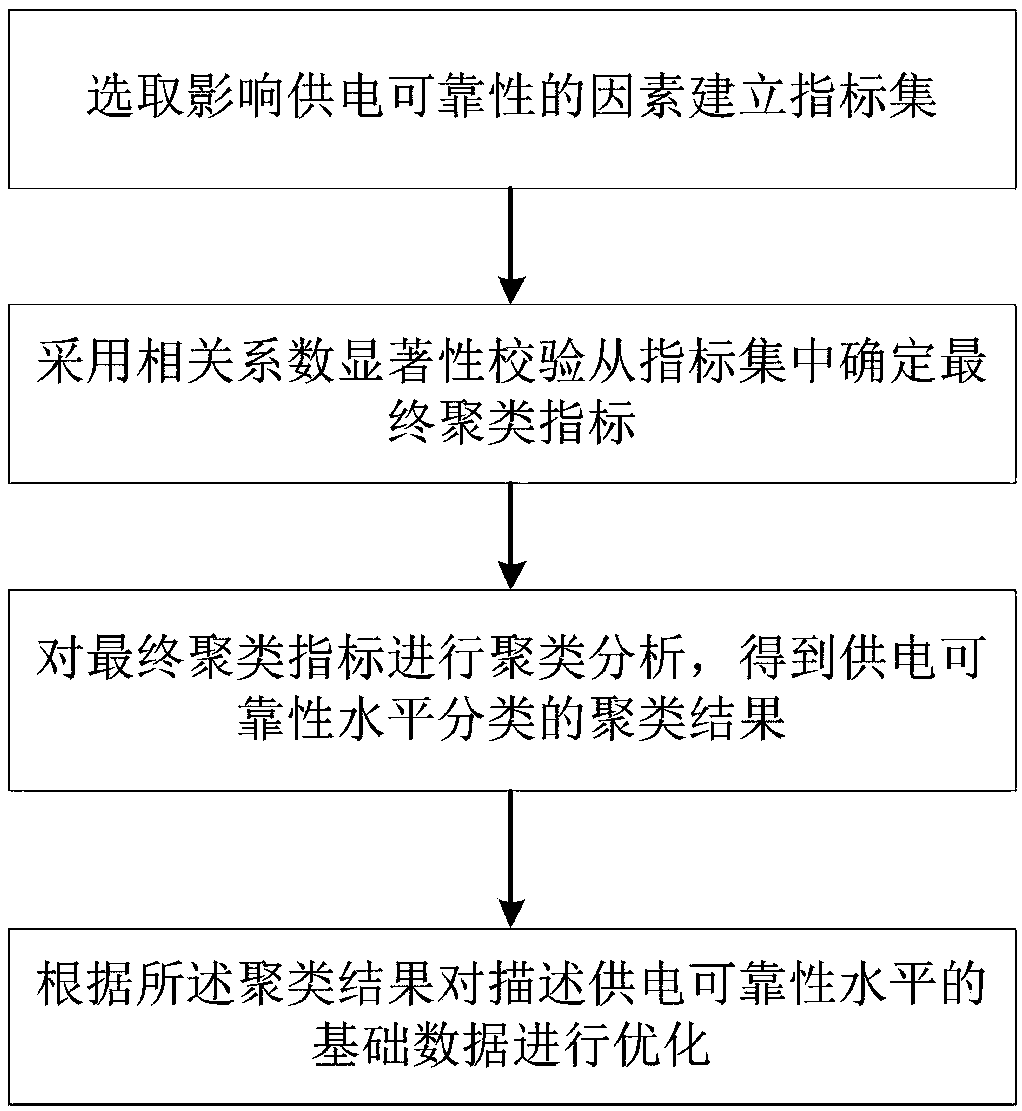
[0122] Building blocks for selecting factors that affect power supply reliability to establish an index set;
[0123] A clustering index determination module, used to determine the final clustering index from the index set by adopting the significance check of the correlation coefficient;
[0124] The clustering analysis module performs clustering analysis on the final clustering index to obtain the optimized clustering index;
[0125] An optimization module, configured to optimize the basic data describing the reliability level of power grid power supply according to the optimized clustering index.
[0126] Further: the clustering index determination module further includes:
[0127] The preprocessing sub-module is used to prepro...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More