

Method, device, server and storage medium for determining data redistribution mode
A determination method and redistribution technology, applied in the database field, can solve problems such as serious resource consumption, improve execution efficiency, and solve the effect of high resource consumption of data redistribution
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
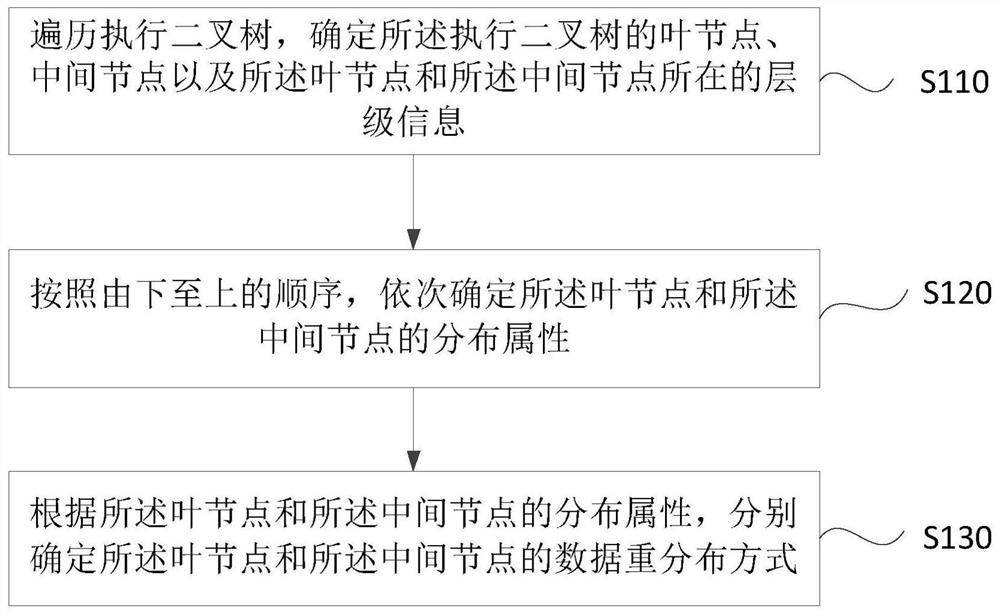
[0030] figure 1 It is a flowchart of a method for determining a data redistribution method provided by Embodiment 1 of the present invention. This embodiment is applicable to determining the data redistribution method of nodes according to the distribution attributes of nodes in a large-scale parallel processing environment, so that In the case where the node executes data redistribution based on the determined data redistribution method, the method can be executed by the device for determining the data redistribution method, which can be implemented by software and / or hardware, and the device is integrated in the server , specifically, the method includes the following steps:
[0031] S110. Traverse the execution binary tree, and determine leaf nodes, intermediate nodes, and level information of the leaf nodes and intermediate nodes of the execution binary tree.
[0032] The execution binary tree is generated by analyzing the query statement input by the user, and the interm...
Embodiment 2
[0046] Figure 4 It is a flow chart of a method for determining a data redistribution method provided by Embodiment 2 of the present invention. This embodiment takes the connection operation as an example, that is, the query statement is a connection query statement, and is embodied on the basis of the above-mentioned embodiment. Specifically, the method includes:
[0047] S210. Traverse the execution binary tree, and determine leaf nodes, intermediate nodes, and level information of the leaf nodes and intermediate nodes of the execution binary tree.
[0048] S220. Determine the distribution attributes of the leaf nodes and the intermediate nodes in sequence from bottom to top.
[0049] The distribution attributes of leaf nodes and intermediate nodes are determined in different ways, as follows:
[0050] S2201. Search the data dictionary to obtain the distribution attributes of the leaf nodes.
[0051] The data dictionary is used to store distribution attributes of each lea...
example 1
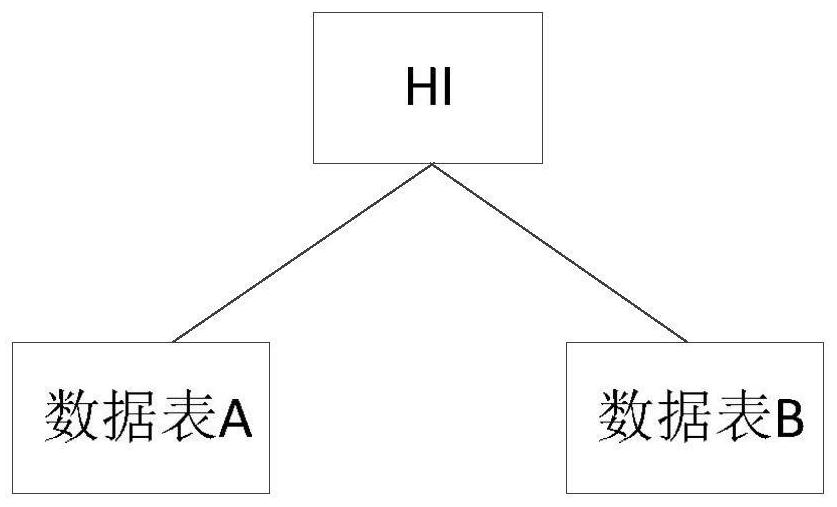
[0108] Data table A and data table B execute hash inner join, the join condition is HI (A.c1=B.d1 and A.c2=B.d2), execute binary tree such as figure 2 shown. The HI node has two optional data redistribution methods, which are the distribution redistribution method and the collection redistribution method.
[0109] (1) Select the distribution redistribution method
[0110] According to the connection conditions, the redistribution item is determined as (c1, d1), (c2, d2) or {(c1, c2), (d1, d2)}, where the distribution attribute of the HI node is consistent with the redistribution item, based on the data table The distribution attributes of A and data table B, specifically include the following situations:
[0111] 1) Both data table A and data table B are not hash distribution, such as random distribution or copy distribution, then both data table A and data table B need to perform distribution redistribution, and the redistribution items are (c1,d1), (c2 ,d2) or {(c1,c2),(...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More