

Oversampling method for unbalanced data set
A data set and oversampling technology, which is applied in the direction of electrical digital data processing, special data processing applications, digital data information retrieval, etc., can solve the problems of affecting analysis results and poor data validity, so as to improve the effectiveness and increase the ease of learning Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0018] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
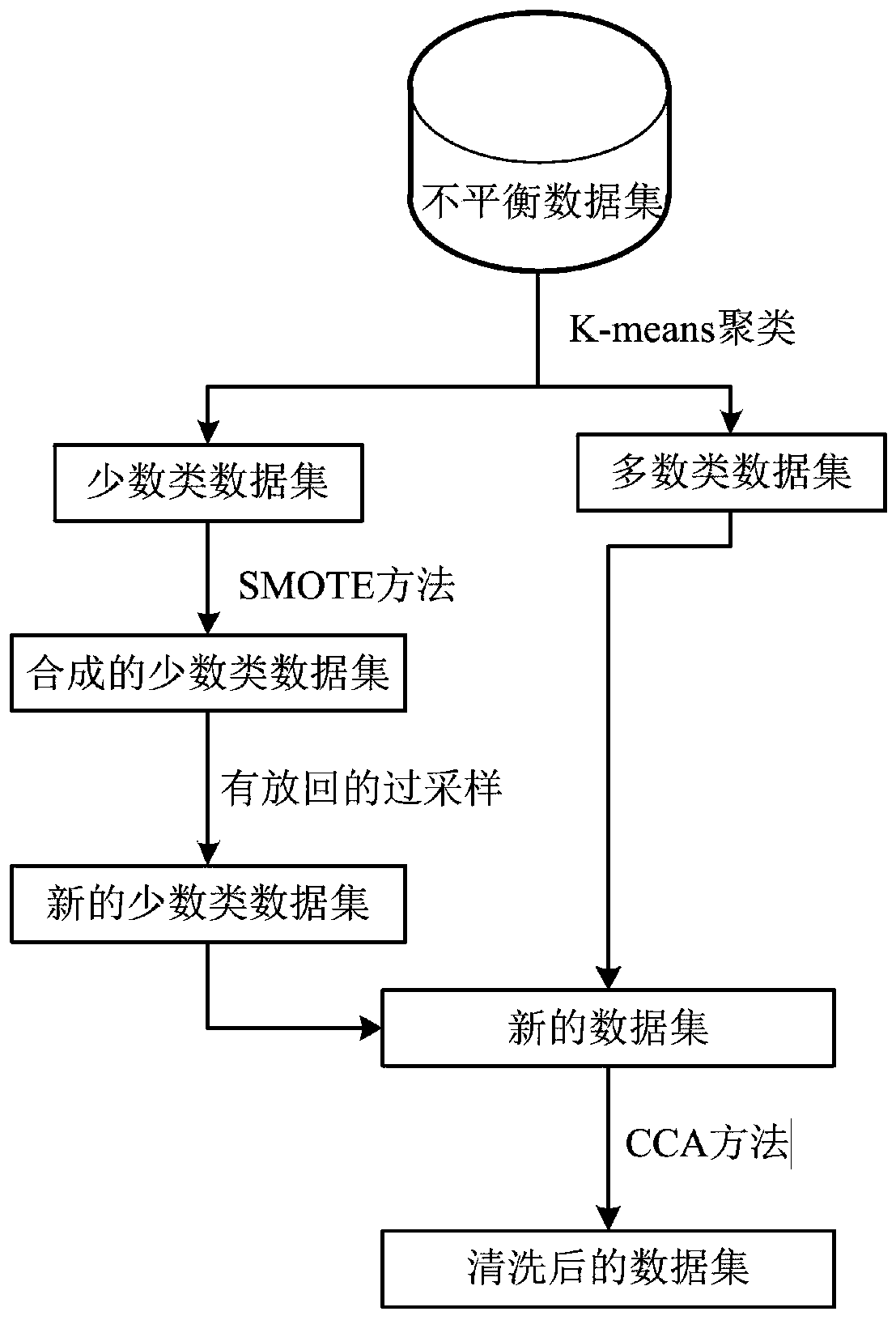
[0019] like figure 1 Shown is a flow chart of the oversampling method of the unbalanced data set of the present invention. The oversampling method of unbalanced data set of the present invention is characterized in that, comprises the following steps:
[0020] Step 1: Collect the unbalanced dataset U 0 , based on the K-means method, for the unbalanced data set U 0 Perform clustering to obtain a data set of K classes {U 01 , U 02 ,...,U 0q ,...,U 0K}, q∈{1,2,...,K}; remember the data set U 0q The number of elements in is s(U 0q ), if s(U 0q )0q into the minority class dataset U m , if s(U 0q )≥ε, the data set U 0q into the majority class dataset U l .
[0021] In this example, the unbalanced data set U 0 It is a telecom user data set, which includes SERV_LEV (service level), CONSUME_GRADE (consumption level), CREDIT_DEG (credit de...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More